Data-Centric AI Careers – Data engineering, quality, labeling, and stewardship

Artificial intelligence breakthroughs are often attributed to better algorithms or larger models. Yet inside real enterprises, a quieter truth dominates: most AI systems succeed or fail because of data, not models. As organizations scale AI beyond pilots into core operations, the limiting factor is no longer model architecture – it is data quality, availability, governance, and continuity.
Enterprise AI depends on vast, evolving data ecosystems: transactional records, sensor streams, documents, logs, images, and human-generated annotations. These data assets must be collected, cleaned, labeled, versioned, governed, and maintained over time. This reality has elevated a critical class of roles that rarely make headlines but increasingly determine AI outcomes: data-centric AI professionals. Careers in data engineering, data quality, labeling, and stewardship now sit at the foundation of scalable, trustworthy AI.
1. Why data-centric AI careers now matter
Many AI initiatives stall not because models underperform, but because data pipelines collapse under real-world complexity. Data arrives late, incomplete, biased, mislabeled, or inconsistent across systems. Training data drifts silently while models continue to produce confident predictions.
Enterprise leaders now ask different questions:
- Where does our training data come from—and can we trust it?
- How do we ensure data quality at scale and over time?
- Who owns labels, definitions, and data standards?
- How do we detect data drift before models degrade?
- How do we govern data used in regulated AI systems?
These questions have shifted attention away from purely model-centric roles toward professionals who treat data as infrastructure, not raw material. Data-centric AI careers exist to ensure that AI systems are built on reliable, auditable, and evolving data foundations.
2. From model-centric to data-centric AI thinking
Traditional AI workflows prioritized model tuning and algorithm selection, often treating data preparation as a one-time preprocessing step. In production environments, this assumption fails quickly. Data changes continuously, new sources emerge, labels decay, and business definitions evolve.
Modern enterprises are moving toward data-centric AI, which emphasizes:
- Continuous data collection and validation,
- Explicit data quality metrics and monitoring,
- Structured labeling and annotation workflows,
- Versioned datasets aligned with model versions,
- Feedback loops between model performance and data gaps.
Data-centric professionals anchor this shift. Their focus is not optimizing loss functions, but ensuring that the data feeding AI systems remains accurate, representative, and aligned with real-world conditions. An excellent collection of learning videos awaits you on our Youtube channel.

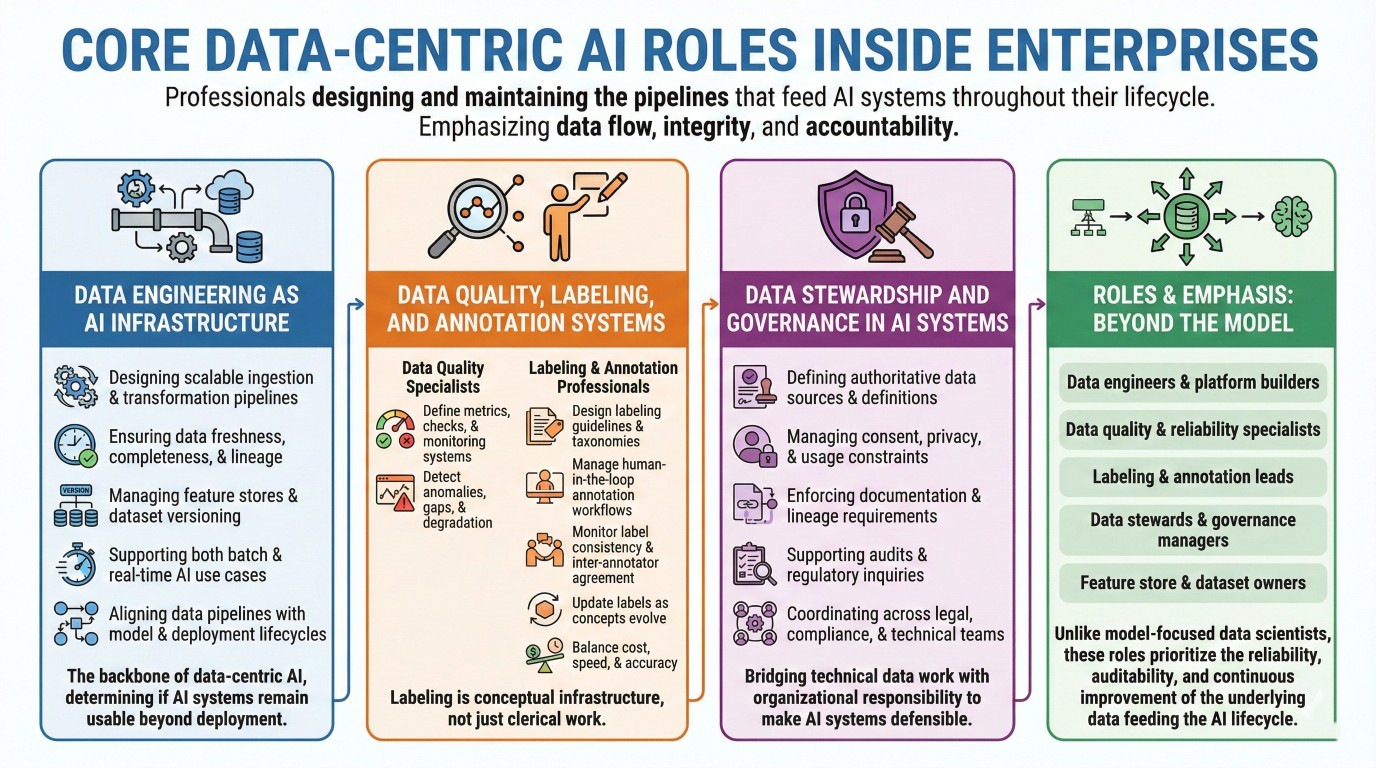
3. Core data-centric AI roles inside enterprises
Data-centric AI roles span engineering, operations, governance, and human workflows. These professionals design and maintain the pipelines that feed AI systems throughout their lifecycle.
They may work as:
- Data engineers and platform builders,
- Data quality and reliability specialists,
- Labeling and annotation leads,
- Data stewards and governance managers,
- Feature store and dataset owners.
Unlike model-focused data scientists, these roles emphasize data flow, integrity, and accountability. Success depends on understanding how data is generated, transformed, labeled, and consumed -often across dozens of systems and teams.
4. Data engineering as AI infrastructure
Data engineering is the backbone of data-centric AI. These professionals build pipelines that ingest raw data from operational systems, apply transformations, enforce schemas, and deliver consistent datasets for training and inference.
Key responsibilities include:
- Designing scalable ingestion and transformation pipelines,
- Ensuring data freshness, completeness, and lineage,
- Managing feature stores and dataset versioning,
- Supporting both batch and real-time AI use cases,
- Aligning data pipelines with model and deployment lifecycles.
Without strong data engineering, even the best models operate on unstable ground. In practice, data engineers often determine whether AI systems remain usable beyond their first deployment. A constantly updated Whatsapp channel awaits your participation.
5. Data quality, labeling, and annotation systems
High-quality data is rarely accidental. Data quality specialists define metrics, checks, and monitoring systems that detect anomalies, gaps, and degradation before they affect models.
Labeling and annotation professionals play an equally critical role. Many AI systems rely on human-labeled data – images, text, audio, or structured records. These labels embed assumptions, definitions, and bias into models.
Professionals in this space:
- Design labeling guidelines and taxonomies,
- Manage human-in-the-loop annotation workflows,
- Monitor label consistency and inter-annotator agreement,
- Update labels as concepts and business needs evolve,
- Balance cost, speed, and accuracy in annotation pipelines.
Labeling is not clerical work – it is conceptual infrastructure for AI systems.
6. Data stewardship and governance in AI systems
As AI influences decisions with legal, ethical, or societal impact, data stewardship becomes central. Data stewards define ownership, access, and accountability across datasets used for AI.
Their responsibilities often include:
- Defining authoritative data sources and definitions,
- Managing consent, privacy, and usage constraints,
- Enforcing documentation and lineage requirements,
- Supporting audits and regulatory inquiries,
- Coordinating across legal, compliance, and technical teams.
Data stewardship ensures that AI systems are not only effective, but defensible. These roles bridge technical data work with organizational responsibility. Excellent individualised mentoring programmes available.
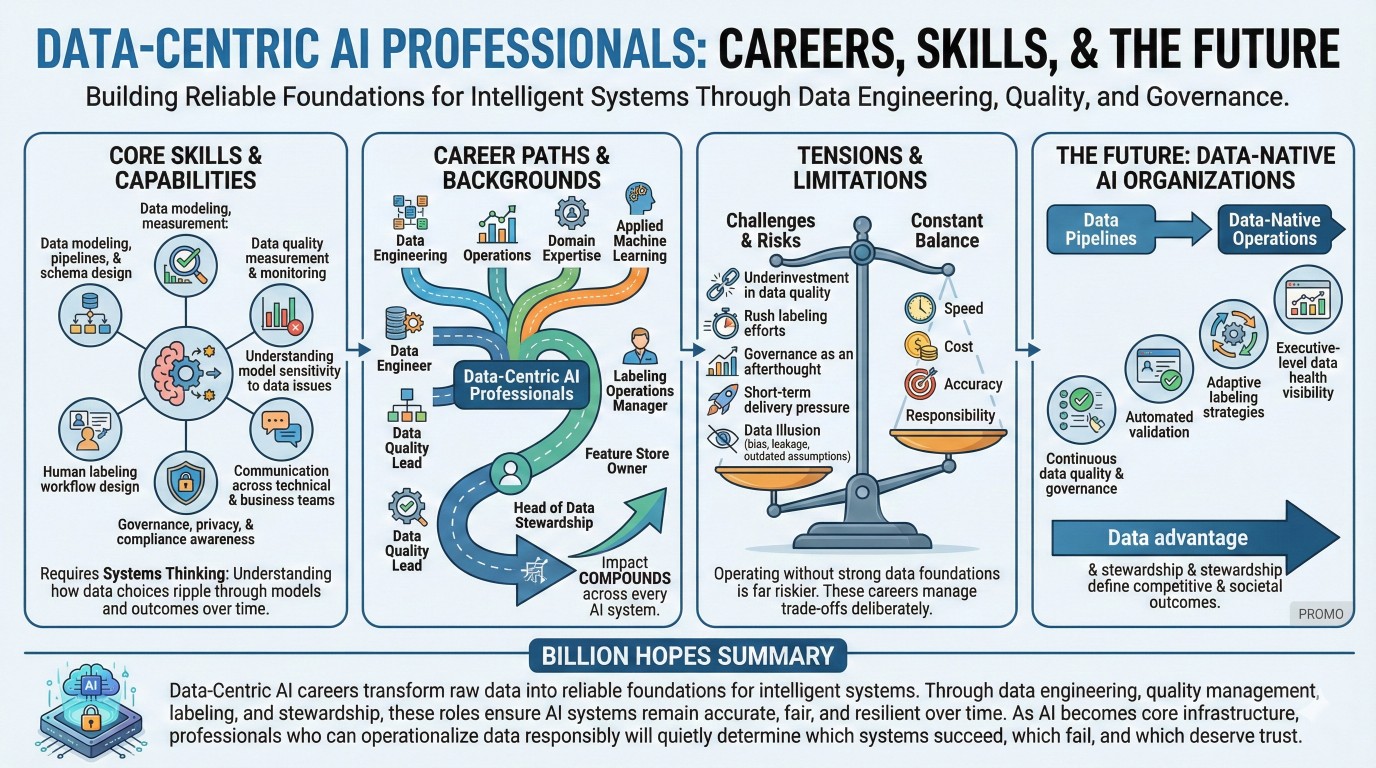
7. Skills that define data-centric AI professionals
Careers in data-centric AI demand a hybrid skill set that blends engineering rigor with contextual judgment.
Core capabilities include:
- Data modeling, pipelines, and schema design,
- Data quality measurement and monitoring,
- Understanding model sensitivity to data issues,
- Human labeling workflow design,
- Governance, privacy, and compliance awareness,
- Communication across technical and business teams.
Above all, these roles require systems thinking – understanding how data choices ripple through models, decisions, and outcomes over time.
8. Career paths and professional backgrounds
Data-centric AI professionals come from diverse backgrounds: data engineering, analytics, operations, domain expertise, and applied machine learning. Some transition from data science after recognizing that data limitations – not algorithms – were holding systems back.
Common titles include Data Engineer, Data Quality Lead, Labeling Operations Manager, Feature Store Owner, or Head of Data Stewardship. Career growth depends less on mastering specific tools and more on enabling reliable AI data foundations at scale.
These roles often operate behind the scenes, but their impact compounds across every AI system an organization builds.
Subscribe to our free AI newsletter now.
9. Tensions and limitations in data-centric AI work
Data-centric AI work faces persistent challenges. Organizations may underinvest in data quality, rush labeling efforts, or treat governance as an afterthought. Short-term delivery pressure often conflicts with long-term data integrity.
There is also the risk of data illusion – datasets that appear large and clean but encode bias, leakage, or outdated assumptions. Data-centric professionals must constantly balance speed, cost, accuracy, and responsibility.
Despite these tensions, operating AI without strong data foundations is far riskier. Data-centric careers exist to manage these trade-offs deliberately.
10. The future: From data pipelines to data-native AI organizations
The future of AI will be increasingly data-centric. Enterprises are moving toward data-native operations, where data quality, labeling, governance, and feedback loops are continuously integrated into AI systems.
This includes automated data validation, adaptive labeling strategies, active learning, and executive-level visibility into data health. As models commoditize, data advantage and stewardship capability will define competitive and societal outcomes.
Upgrade your AI-readiness with our masterclass.
Billion Hopes summary
Data-Centric AI careers transform raw data into reliable foundations for intelligent systems. Through data engineering, quality management, labeling, and stewardship, these roles ensure AI systems remain accurate, fair, and resilient over time. As AI becomes core organizational infrastructure, professionals who can operationalize data responsibly will quietly determine which systems succeed, which fail, and which deserve trust.
Share this with the world
Related Articles



