Continual and lifelong learning solving catastrophic forgetting

Continual and lifelong learning solving catastrophic forgetting
How to update a model with new information without losing previously learned skills
Introduction
Modern AI systems are increasingly expected to behave like human learners: they should continuously acquire new knowledge while retaining previously learned skills. However, traditional machine learning models struggle with a fundamental limitation known as catastrophic forgetting. This phenomenon occurs when a neural network trained on new tasks or data abruptly loses its ability to perform earlier tasks well.
The reason lies in how neural networks store knowledge. Information is encoded in model weights, and when new training updates those weights, they may overwrite representations that were essential for earlier tasks. As a result, improving performance on a new dataset can unintentionally degrade performance on previous ones.
This problem becomes critical in real-world AI systems where data evolves continuously—new customer behaviour patterns, changing language usage, emerging cybersecurity threats, or newly discovered medical information. Retraining models from scratch every time new data appears is expensive and inefficient.
To address this challenge, researchers developed continual learning (also called lifelong learning or incremental learning). Continual learning enables AI models to learn sequentially from streams of data while preserving previously acquired knowledge. In simple terms, the goal is to build AI systems that can update themselves with new information without “forgetting” what they already know—much like human learning. Over the past decade, a wide range of techniques have emerged to make this possible, forming one of the most important research areas in modern machine learning.
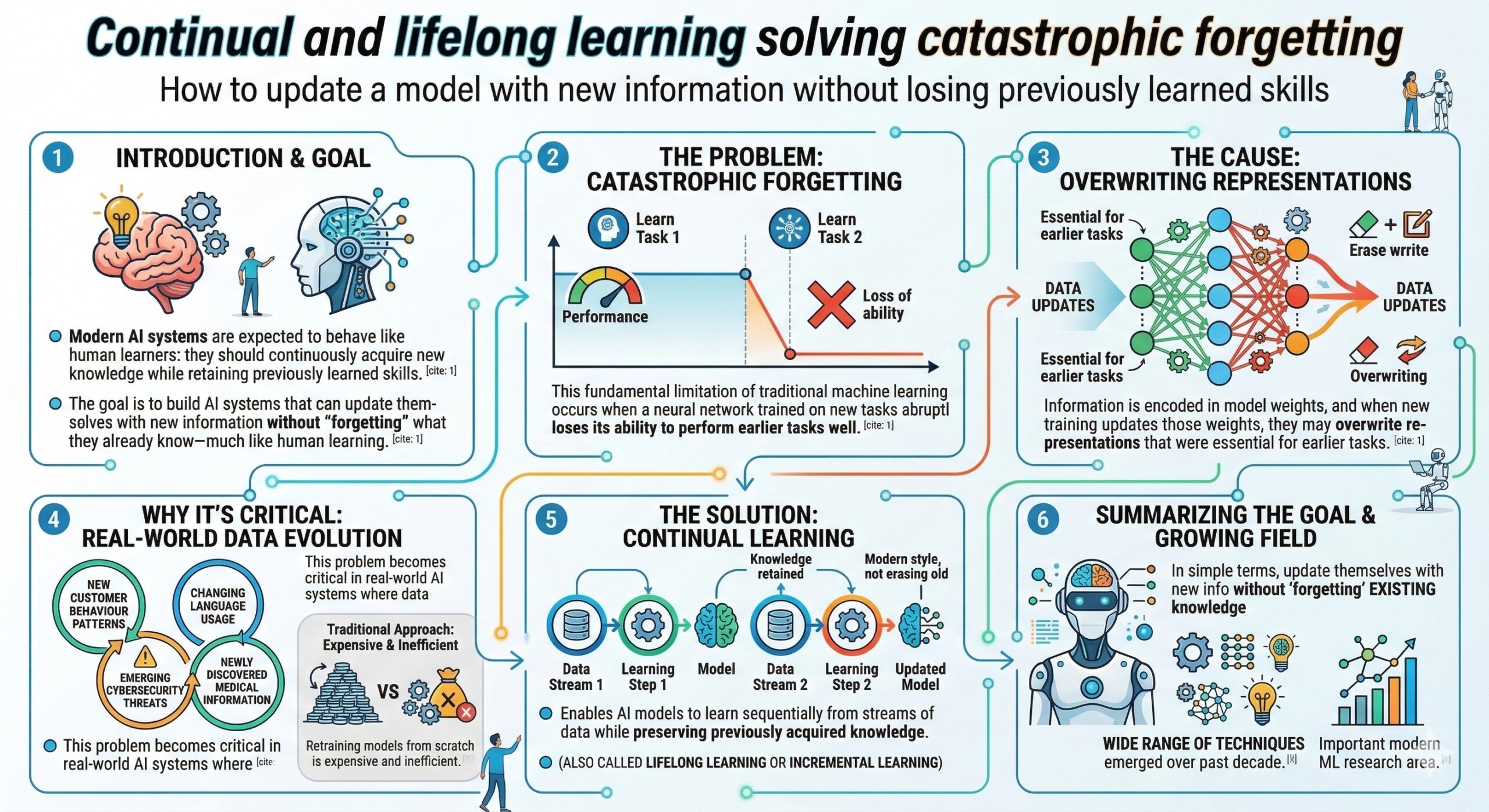
1. Understanding the stability-plasticity dilemma
The central challenge in continual learning is balancing stability and plasticity.
- Plasticity: The ability of a model to learn new information quickly.
- Stability: The ability to preserve previously learned knowledge.
If a model is too plastic, it forgets older knowledge. If it is too stable, it cannot adapt to new information. Continual learning methods aim to find the right balance so that models evolve without losing past competence.
This dilemma is a core reason catastrophic forgetting occurs.
2. Replay-based learning: Remembering past experiences
One of the most practical strategies is experience replay.
The idea is simple: when training the model on new data, it also revisits samples from earlier tasks.
Key techniques include:
- Rehearsal methods – store a small subset of old training examples and replay them during new training.
- Generative replay – use a generative model to recreate synthetic examples of past data.
- Memory buffers – maintain representative examples from previous tasks.
By periodically reviewing old knowledge during training, the model maintains performance on earlier tasks while learning new ones.
This approach mimics how humans recall previous experiences while learning something new. An excellent collection of learning videos awaits you on our Youtube channel.
3. Regularization methods: Protecting important knowledge
Another major class of techniques modifies the training objective to protect critical model parameters.
A well-known example is Elastic Weight Consolidation (EWC).
- The method identifies parameters that were important for previous tasks.
- During training on new tasks, it penalizes large changes to those parameters.
- As a result, important knowledge remains intact.
This technique allows the model to update itself while preserving key weights that encode earlier knowledge.
Regularization methods are popular because they do not require storing large amounts of old data.
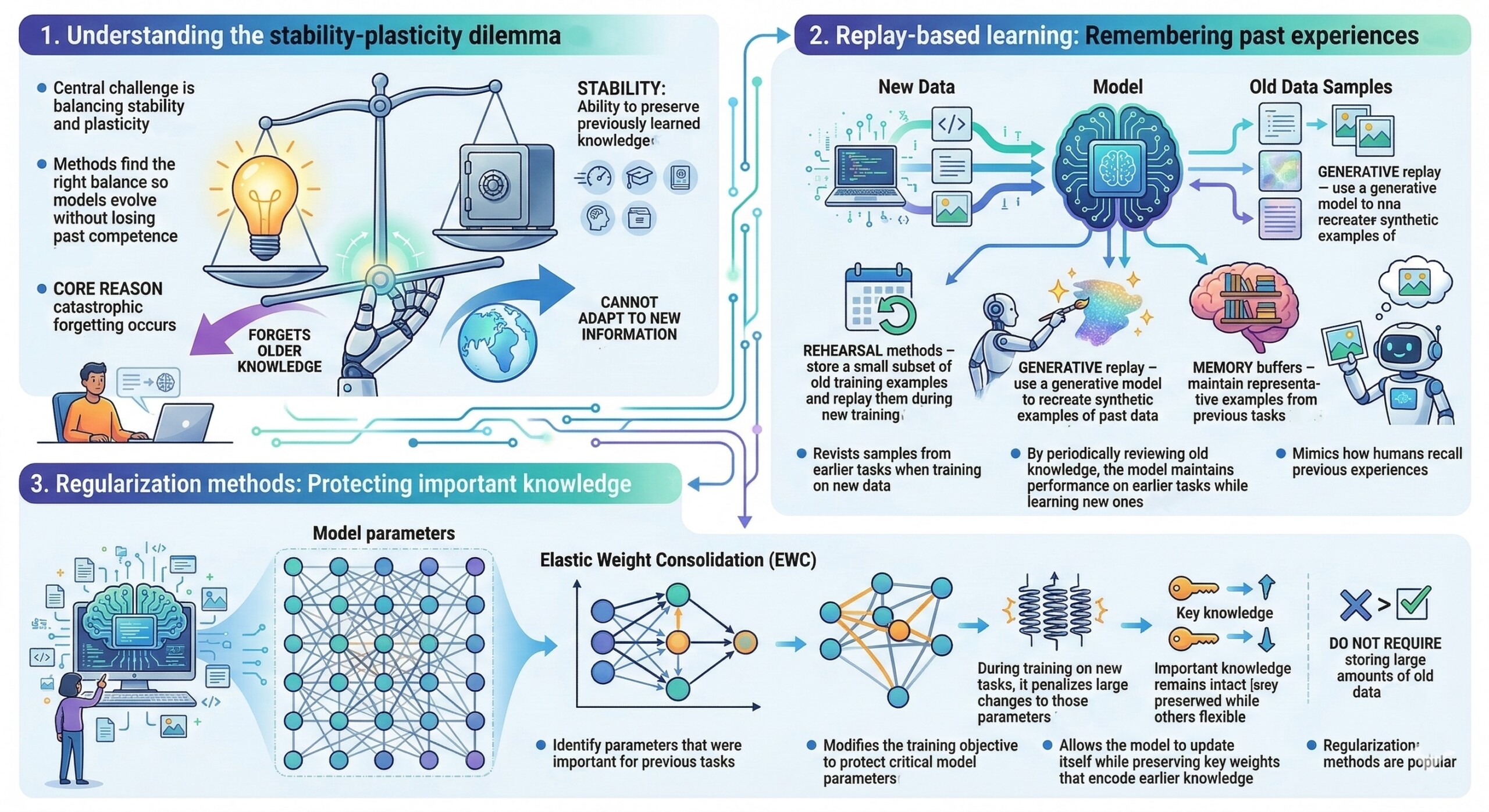
4. Architecture-based methods: Expanding the model
Some approaches modify the architecture of the neural network itself.
Instead of forcing one model to handle everything with the same parameters, the system grows or adapts as new tasks arrive.
Examples include:
- Dynamically adding new neurons or layers for new tasks
- Allocating task-specific subnetworks
- Using modular neural architectures
By separating parameters for different tasks, the system reduces interference between new and old knowledge.
This strategy resembles how the human brain recruits new neural pathways when learning new skills. A constantly updated Whatsapp channel awaits your participation.
5. Gradient-constrained learning
Another technique focuses on controlling how gradients update the model.
Methods such as Gradient Episodic Memory (GEM) adjust the gradient updates so that learning a new task does not increase the loss on previous tasks.
In practice:
- The model stores gradients from earlier tasks.
- During new training, updates are modified to remain compatible with past learning.
This ensures that learning new knowledge does not damage old capabilities.
6. Knowledge distillation and “Learning without forgetting”
Knowledge distillation is also used to maintain past capabilities.
In the Learning Without Forgetting (LwF) approach:
- The original model acts as a “teacher”.
- The updated model is trained to produce outputs similar to the teacher for previous tasks.
This method preserves earlier behaviour while allowing the model to learn new data.
It is particularly useful when access to old training data is limited. Excellent individualised mentoring programmes available.
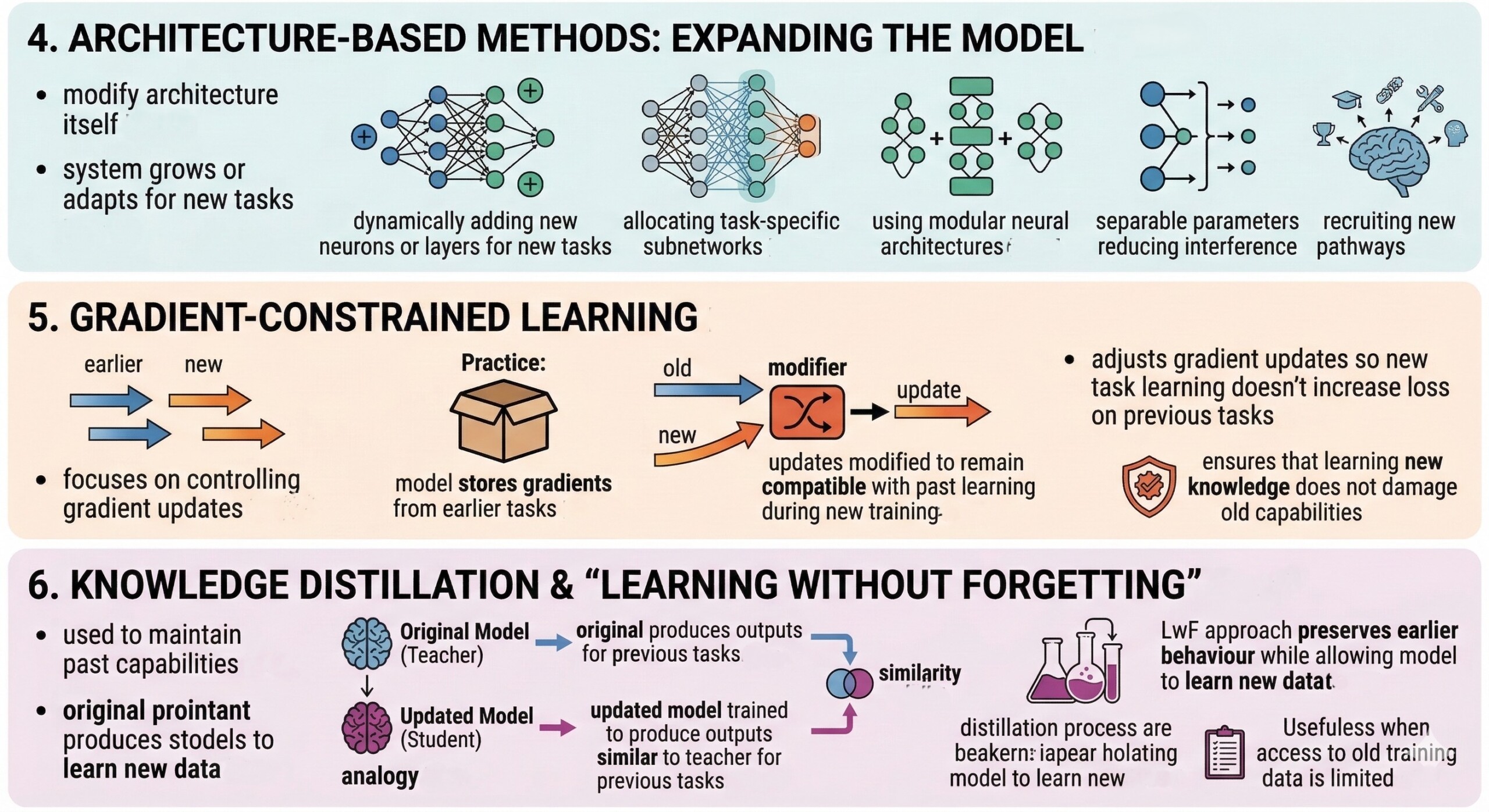
7. Sparse updates and Parameter-efficient learning
Recent research in large language models explores sparse updates.
Instead of updating all parameters during fine-tuning:
- Only specific memory layers or parameter subsets are updated.
- Most of the model remains unchanged.
This reduces interference between old and new knowledge and significantly lowers catastrophic forgetting.
Such approaches are increasingly important for updating large AI models in production.
8. Meta-learning and Trust-region methods
Newer research combines continual learning with meta-learning principles.
Techniques such as trust-region continual learning constrain updates so that the model remains close to parameter regions that worked well for earlier tasks.
The result:
- Faster adaptation to new tasks
- Better recovery of earlier capabilities
These methods treat continual learning as a problem of maintaining a good starting point for future learning. Subscribe to our free AI newsletter now.
9. Biological inspiration from human learning
Human brains rarely experience catastrophic forgetting.
Neuroscience suggests several mechanisms that inspire AI solutions:
- Sparse neural representations
- Context-dependent memory recall
- Rehearsal during sleep
- Task-specific neural pathways
Researchers increasingly draw from these ideas to design brain-inspired continual learning algorithms.
This cross-disciplinary approach may unlock more robust lifelong learning systems.
10. Real-world importance of continual learning
Continual learning is becoming essential for modern AI deployment.
Examples include:
- Recommendation systems adapting to changing user preferences
- Autonomous vehicles learning from new driving scenarios
- Fraud detection models adapting to new attack patterns
- Large language models updating with new facts and knowledge
Instead of periodic retraining, organizations increasingly adopt continuous model updating pipelines that combine incremental learning with occasional full retraining cycles.
This makes AI systems more adaptive, efficient, and scalable. Upgrade your AI-readiness with our masterclass.
Conclusion
Catastrophic forgetting has long been one of the most significant obstacles in machine learning. Traditional neural networks excel when trained once on a fixed dataset, but they struggle when required to learn sequentially from evolving data. As real-world applications demand continuously updating AI systems, this limitation becomes increasingly problematic.
Continual and lifelong learning provide a path forward. By combining replay mechanisms, parameter regularization, architectural expansion, gradient constraints, and knowledge distillation, researchers have developed a toolkit that enables AI models to learn new information without erasing past knowledge. The field is still evolving rapidly. New techniques – especially those designed for large language models – focus on sparse updates, modular architectures, and hybrid replay-regularization approaches.
These innovations move AI closer to a fundamental goal: machines that can learn throughout their lifetime, accumulating knowledge rather than repeatedly overwriting it. Ultimately, the ability to update models without forgetting will determine whether AI systems can function as long-term learning entities rather than static tools. As research progresses, continual learning may become the default paradigm for building adaptive, intelligent systems capable of evolving alongside the world they serve.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



