DATA BASICS

DATA BASICS
The Foundation of AI, Machine Learning, and Intelligent Systems
1. Why Data is the true starting point of AI
There is no AI without data. And there is no good AI without good data.
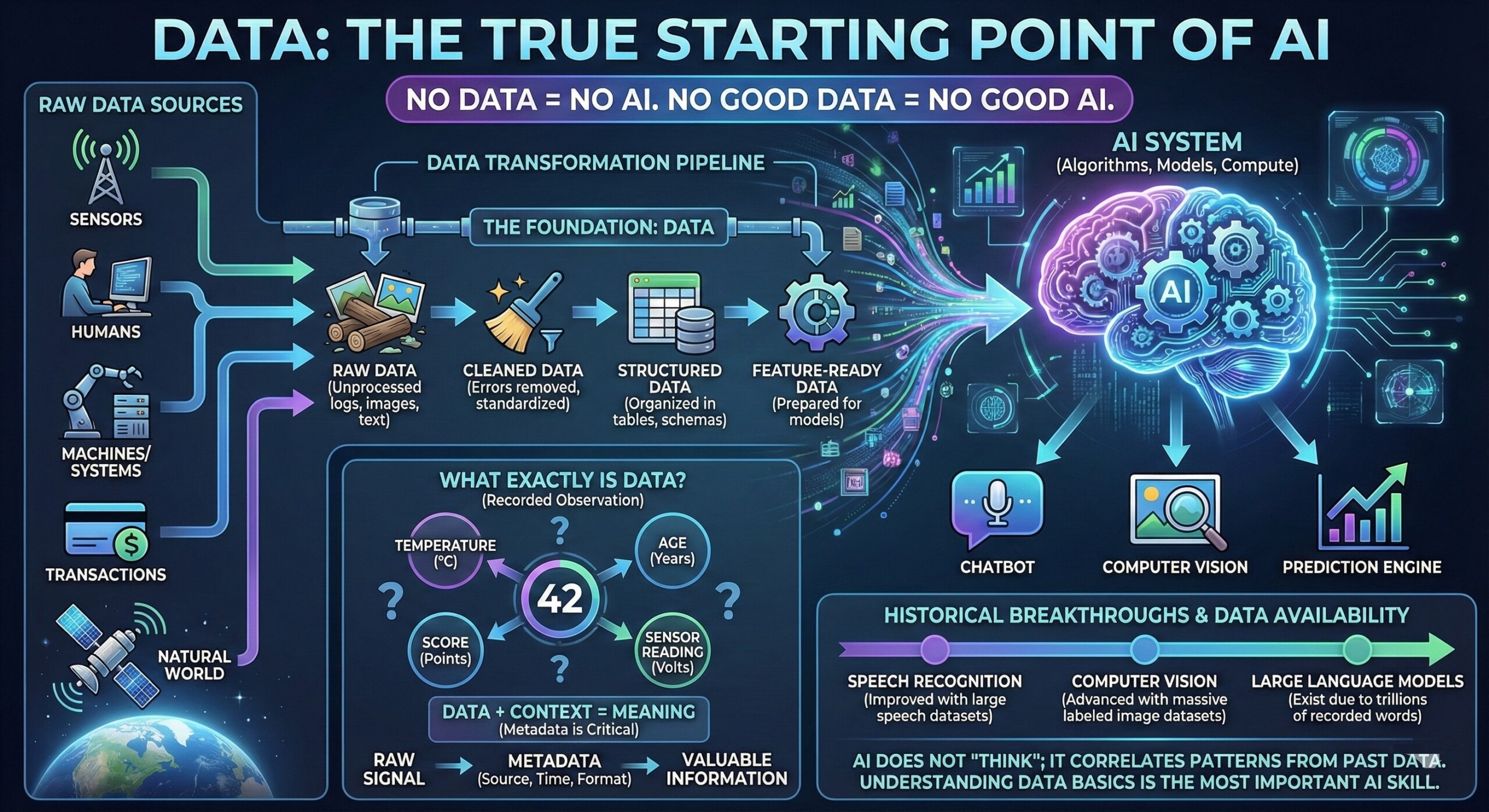
Artificial Intelligence often feels like a story about algorithms, models, and compute power. In reality, data is the real beginning. Every AI system – whether a chatbot, recommendation engine, fraud detector, or medical diagnostic tool – starts with data. Without data, models have nothing to learn from, nothing to generalize, and nothing to predict.
Historically, major AI breakthroughs followed data availability, not algorithmic genius alone. Speech recognition improved dramatically once large speech datasets became available. Computer vision advanced when massive labeled image datasets appeared. Modern large language models exist only because trillions of words were digitally recorded across decades.
In simple terms: AI does not “think”; it correlates patterns from past data. Understanding data basics is therefore not optional – it is the most important AI skill, even for non-technical professionals.
2. What exactly Is Data? From raw signals to meaning
At its core, data is recorded observation. It may come from sensors, humans, machines, systems, transactions, or the natural world. A temperature reading, a customer purchase, a medical scan, a tweet, or a satellite image – all are data.
Data becomes valuable only when it carries context. A number like “42” means nothing until you know whether it is a temperature, age, score, or sensor reading. This is why metadata – data about data – is critical in AI systems. Metadata describes source, time, format, reliability, and usage constraints.
In AI pipelines, data typically moves through stages:
- Raw data (unprocessed logs, images, text)
- Cleaned data (errors removed, formats standardized)
- Structured data (organized into tables or schemas)
- Feature-ready data (prepared for models)
Most AI project failures happen not at the modeling stage – but because this transformation pipeline was poorly understood or underestimated. An excellent collection of learning videos awaits you on our Youtube channel
3. Types of data used in AI and ML
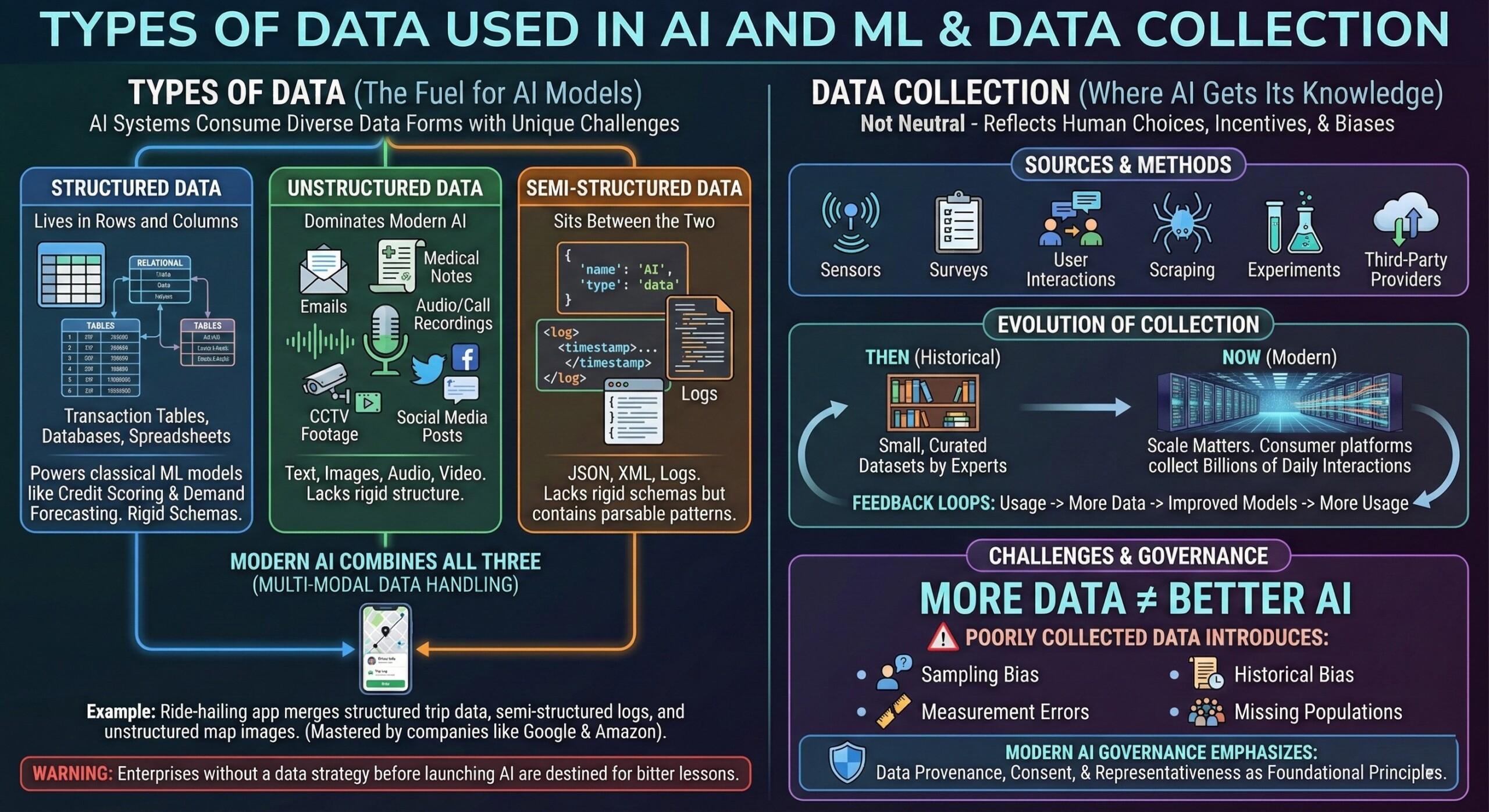
AI systems consume many forms of data, each with unique challenges.
Structured data lives in rows and columns – databases, spreadsheets, transaction tables. It powers classical ML models like credit scoring and demand forecasting.
Unstructured data includes text, images, audio, and video. This dominates modern AI. Emails, medical notes, call recordings, CCTV footage, and social media posts fall here.
Semi-structured data (JSON, XML, logs) sits between the two. It lacks rigid schemas but contains patterns machines can parse.
Modern AI systems often combine all three. For example, a ride-hailing app merges structured trip data, semi-structured logs, and unstructured map images. Companies like Google and Amazon built their AI dominance by mastering multi-modal data handling.
Enterprises that do not get their data strategy in place before launching an AI project are destined to learn some bitter lessons.
4. Data Collection: Where AI gets its knowledge
Data collection is not neutral – it reflects human choices, incentives, and biases. Data may be collected via sensors, surveys, user interactions, scraping, experiments, or third-party providers.
Historically, early AI systems relied on small, curated datasets created by experts. Today, scale matters more. Consumer platforms collect billions of daily interactions, creating feedback loops where usage generates more data, which improves models, which drives more usage.
However, more data does not automatically mean better AI. Poorly collected data introduces:
- Sampling bias
- Historical bias
- Measurement errors
- Missing populations
This is why modern AI governance emphasizes data provenance, consent, and representativeness as foundational principles. A constantly updated Whatsapp channel awaits your participation.
5. Data Quality: The hidden determinant of AI performance
A powerful model trained on poor data will still fail. Data quality issues quietly destroy AI reliability.
Key dimensions of data quality include:
- Accuracy – Is the data correct?
- Completeness – Are important fields missing?
- Consistency – Do values agree across systems?
- Timeliness – Is the data outdated?
- Relevance – Does it reflect the real problem?
In real-world ML projects, 70–80% of effort goes into fixing data quality, not model tuning. Even companies like Netflix attribute recommendation accuracy more to clean behavioural data than algorithmic novelty.
This reality explains why data engineers and data governance teams are now as critical as data scientists.
6. Data Labeling: Teaching machines what matters
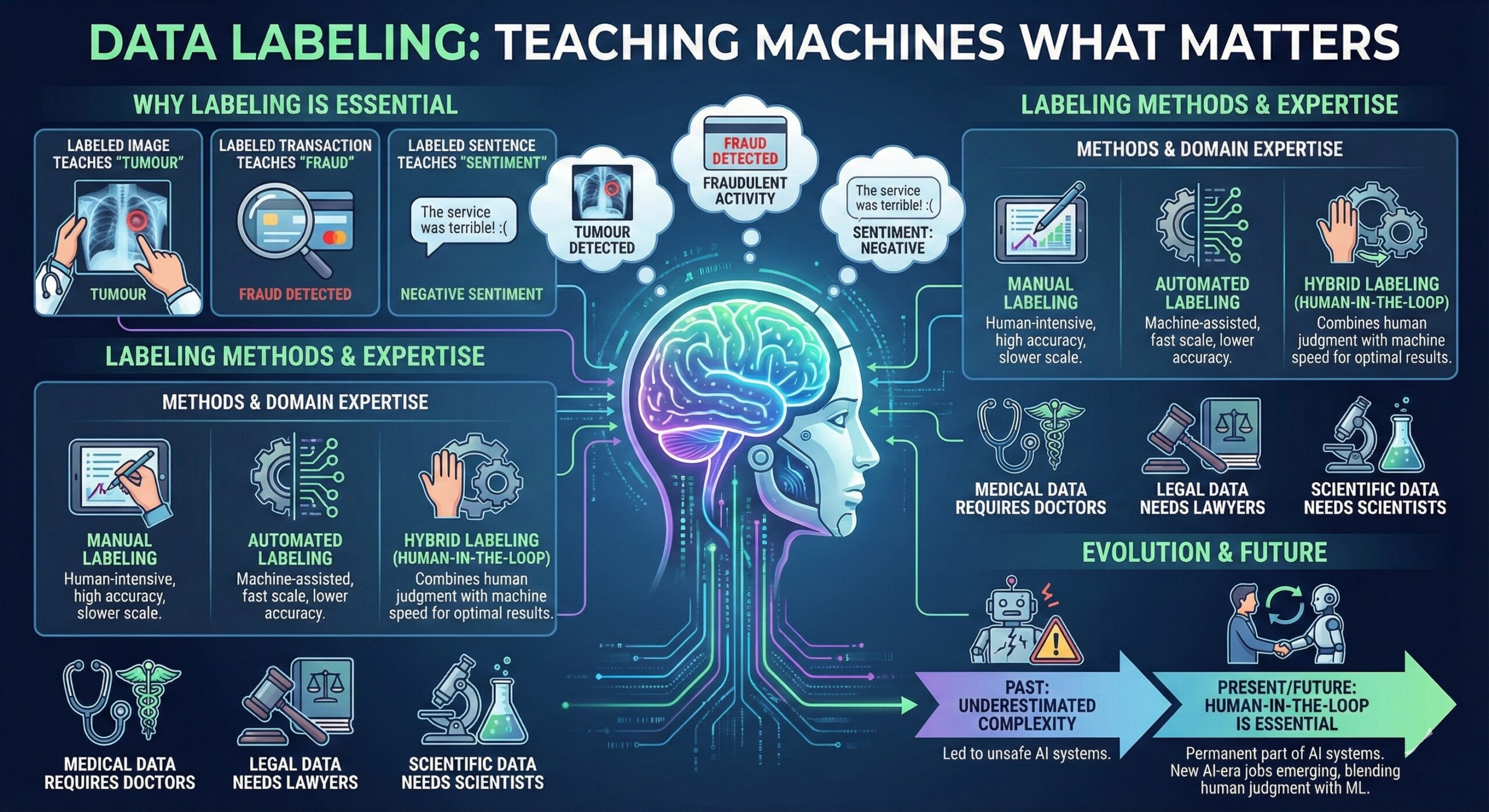
Machine learning does not automatically understand meaning. Labels provide meaning. A labeled image teaches a model what a “tumour” looks like. A labeled transaction teaches what “fraud” means. A labeled sentence teaches sentiment or intent.
Labeling can be manual, automated, or hybrid. Domain expertise matters deeply. Medical data requires doctors. Legal data needs lawyers. Scientific data needs scientists.
Historically, underestimating labeling complexity led to unsafe AI systems. Today, organizations recognize human-in-the-loop labeling as essential – not a temporary step, but a permanent part of AI systems.
This is also where many new AI-era jobs are emerging, blending human judgment with machine learning. Excellent individualised mentoring programmes available.
7. Data Architectures powering modern AI
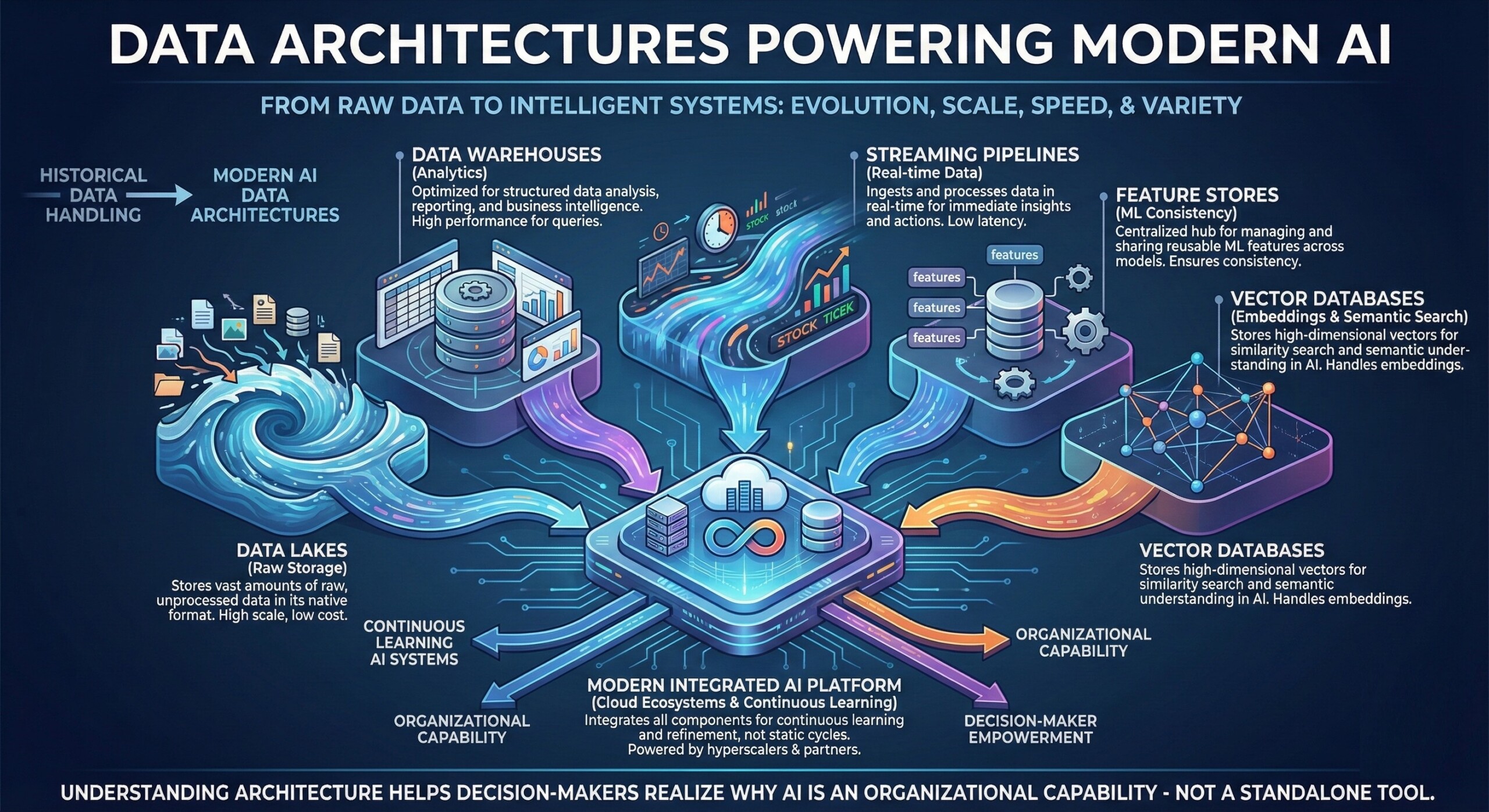
AI does not run on data alone – it runs on data architectures. Over decades, architectures evolved to handle scale, speed, and variety.
Key architectural components include:
- Data lakes for raw storage
- Data warehouses for analytics
- Streaming pipelines for real-time data
- Feature stores for ML consistency
- Vector databases for embeddings and semantic search
Modern AI platforms integrate all of these. Cloud ecosystems, often built by organizations like OpenAI partners and hyperscalers, allow AI systems to learn continuously rather than in static cycles.
Understanding architecture helps decision-makers realize why AI is an organizational capability – not a standalone tool.
8. Data Bias, Ethics, and Social Impact
Data reflects society – including its inequalities. When biased data trains AI, those biases scale automatically.
Historical examples show this clearly:
- Hiring systems favouring certain demographics
- Credit models penalizing marginalized groups
- Facial recognition failing across skin tones
These failures are not “AI mistakes”; they are data mistakes. Ethical AI begins with ethical data practices: diverse sampling, bias audits, transparency, and accountability.
Regulators increasingly focus on data governance rather than algorithms. This shift reflects a growing consensus: controlling data is the most effective way to control AI behaviour. Subscribe to our free AI newsletter now.
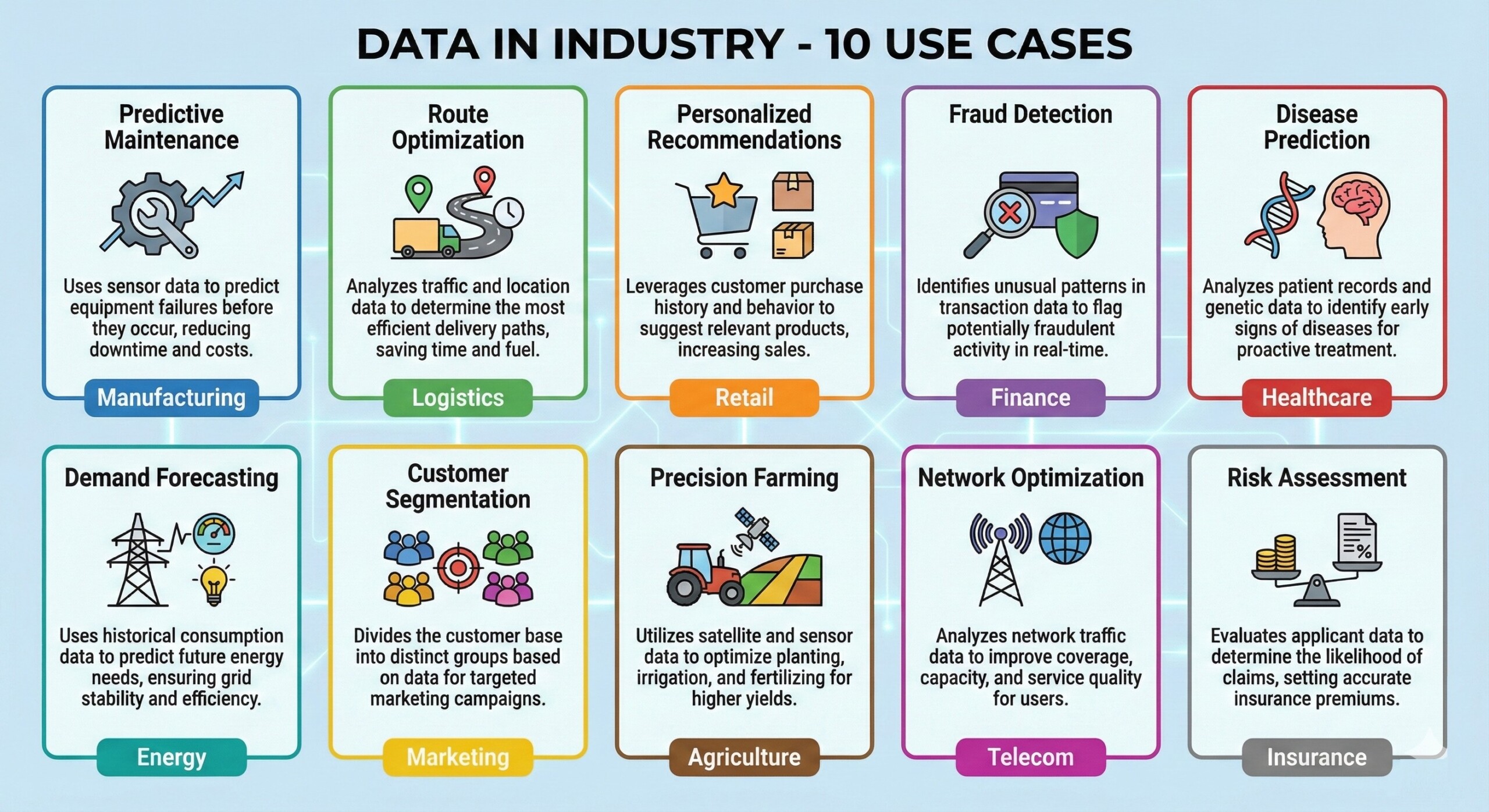
9. Industry Use Cases: Data in action
Across industries, data drives AI differently.
In healthcare, patient records, scans, and genomics enable diagnostics and drug discovery – yet demand extreme data privacy.
In finance, transaction data powers fraud detection and risk scoring but must satisfy regulatory explainability.
In manufacturing, sensor data enables predictive maintenance, reducing downtime.
In retail and media, behavioural data fuels personalization engines that shape user experience.
Across all sectors, success correlates less with having “advanced AI” and more with having disciplined data foundations.
10. The Future: From data exhaust to data strategy
The future of AI is not just more data – but better data strategy. Organizations are moving from accidental data accumulation to intentional data design.
Emerging trends include:
- Synthetic data to overcome scarcity
- Privacy-preserving learning techniques
- Real-time learning systems
- Domain-specific data ecosystems
Ultimately, AI maturity is data maturity. Those who understand data deeply – its limits, strengths, and responsibilities – will shape the next decade of intelligent systems.
AI will keep evolving. Algorithms will change. Compute will grow.
But data will remain the bedrock.
If AI is the engine, data is the fuel, the map, and the memory. Master data basics, and AI stops being mysterious – it becomes manageable, explainable, and useful. Upgrade your AI-readiness with our masterclass.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



