Embedding Spaces & Representation Geometry

Embedding Spaces & Representation Geometry
Semantic structure of vector spaces, Anisotropy, clustering
Introduction
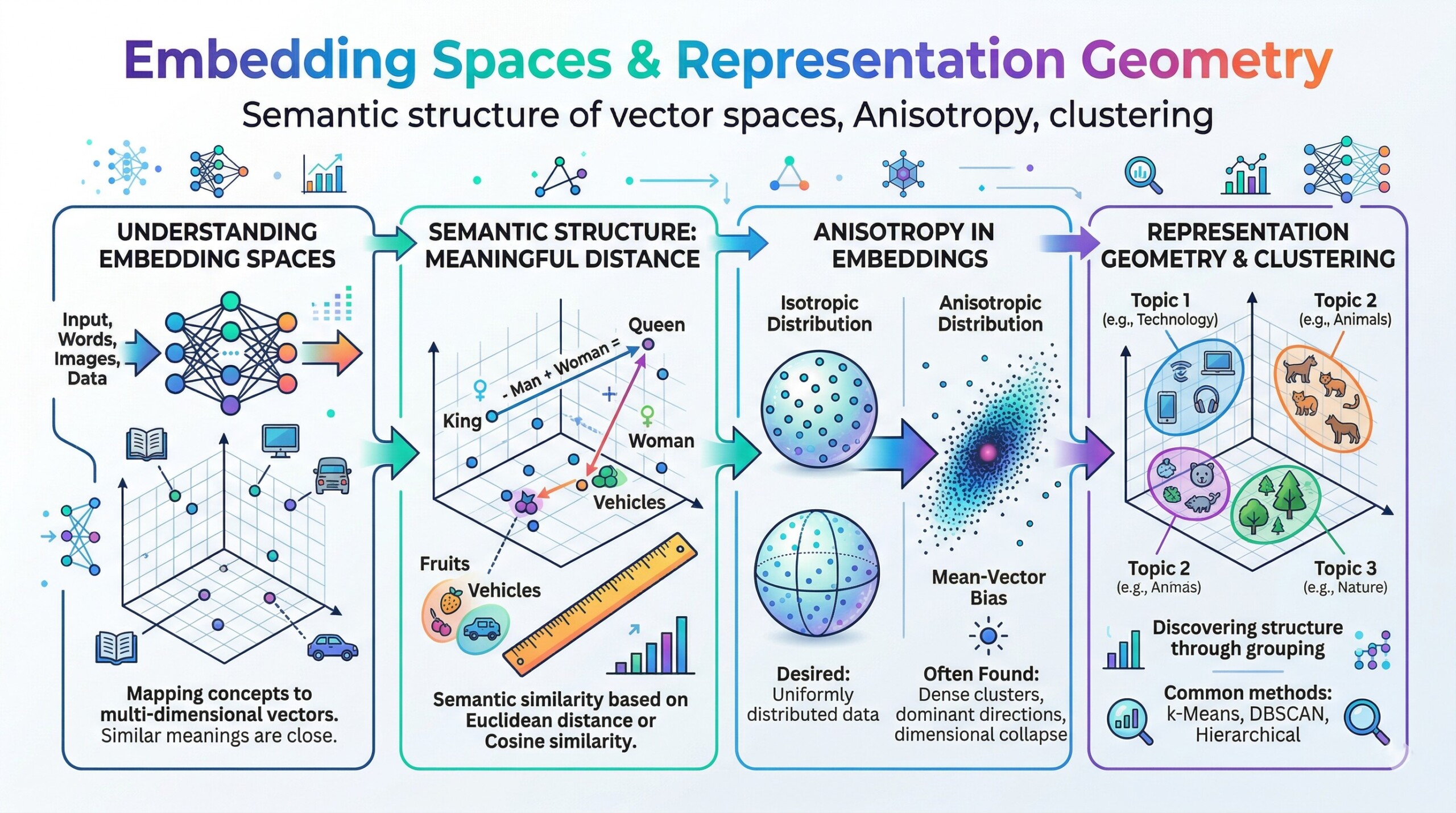
Modern AI systems – especially those built on deep learning – do not “understand” language, images, or data in the way humans do. Instead, they convert everything into numbers. These numbers are not random; they live inside structured mathematical environments called embedding spaces. In these spaces, meaning is encoded through position, distance, and direction. Words with similar meanings, images with similar features, or users with similar preferences tend to cluster together in these high-dimensional landscapes.
Understanding embedding spaces is crucial because they form the backbone of systems like search engines, recommendation systems, and large language models. But beyond their practical utility lies a deeper geometric story: how meaning becomes shape. Concepts such as semantic structure, anisotropy, and clustering reveal that these spaces are not uniform or random—they have patterns, biases, and hidden geometries that influence how AI systems behave. This article explores these underlying structures and why they matter.
Let’s dive deep into the topic.
1. What is an Embedding Space
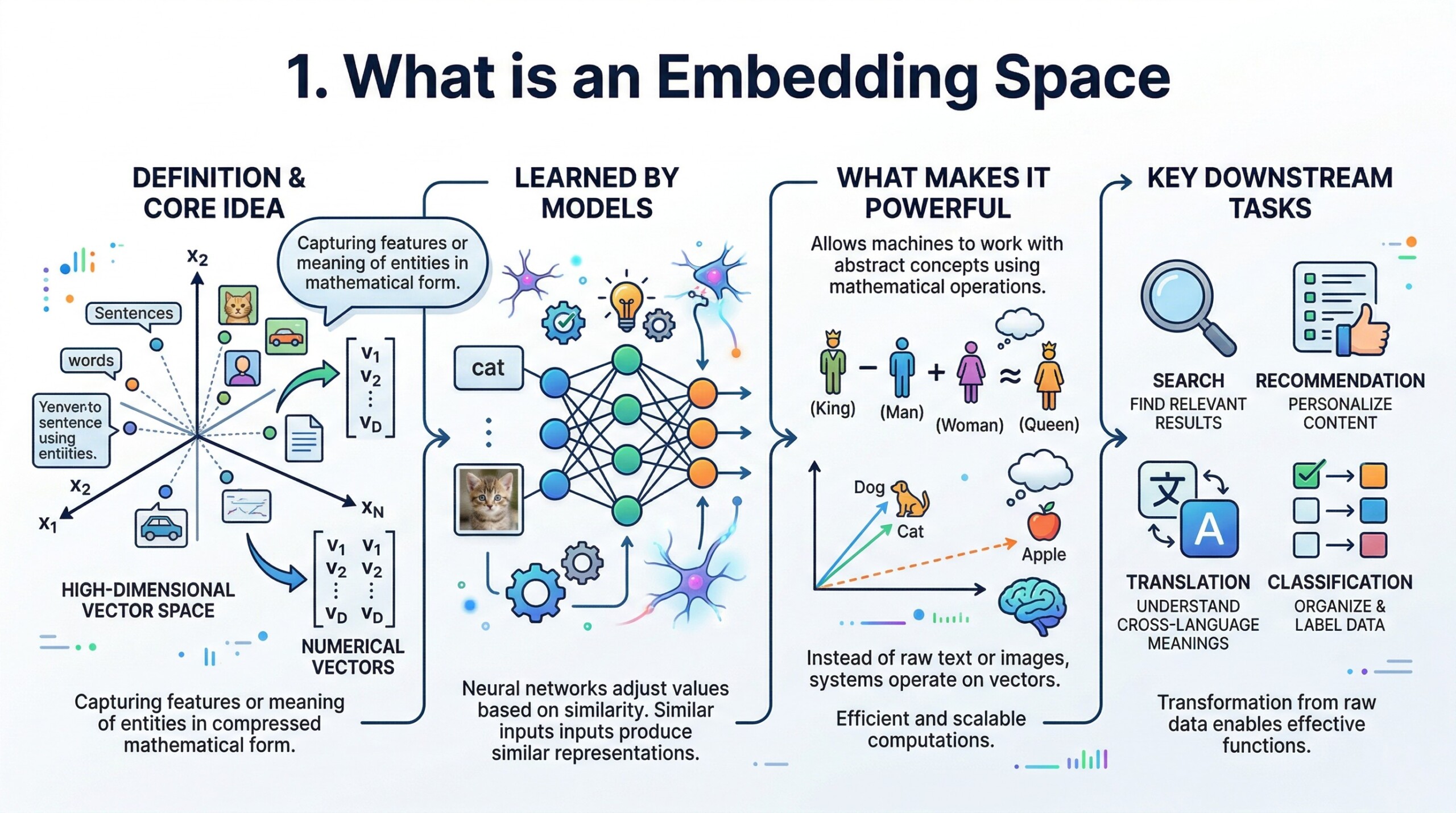
An embedding space is a high-dimensional vector space where data (words, sentences, images, users, or even entire documents) is represented as numerical vectors. Each vector is essentially a list of numbers that captures the features or meaning of that entity in a compressed mathematical form. These vectors are learned by models such as neural networks, which adjust their values so that similar inputs produce similar representations.
What makes embedding spaces powerful is that they allow machines to work with abstract concepts using mathematical operations. Instead of dealing with raw text or images, the system operates on vectors, making computations efficient and scalable. This transformation from raw data to structured vectors is what enables downstream tasks such as search, recommendation, translation, and classification to function effectively.
2. Semantic Structure is Geometric
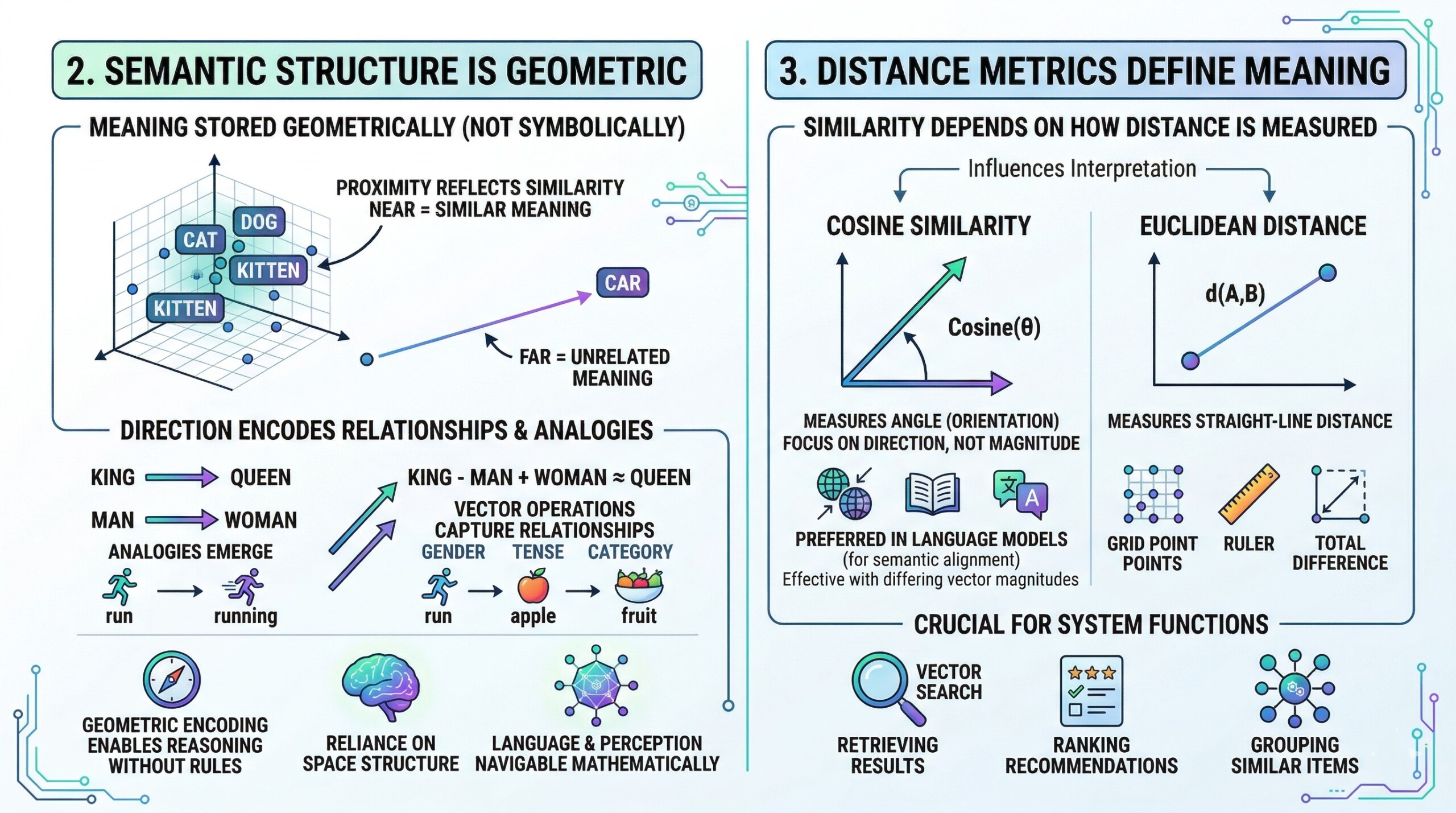
In embedding spaces, meaning is not stored symbolically but geometrically. Concepts that are semantically similar are located near each other, while unrelated concepts are positioned far apart. This creates a spatial organization where proximity reflects similarity, and direction can encode relationships between concepts.
For example, relationships such as analogies emerge naturally in well-trained embeddings. Operations like vector subtraction and addition can capture relationships such as gender, tense, or category. This geometric encoding allows machines to perform a form of reasoning without explicit rules, relying instead on the structure of the space. It transforms language and perception into something that can be navigated mathematically. An excellent collection of learning videos awaits you on our Youtube channel.
3. Distance Metrics define meaning
The idea of “similarity” in an embedding space depends entirely on how distance is measured. Two of the most commonly used metrics are cosine similarity and Euclidean distance. Cosine similarity measures the angle between two vectors, focusing on their orientation rather than magnitude, while Euclidean distance measures the straight-line distance between points in space.
The choice of metric can significantly influence how relationships are interpreted. For example, cosine similarity is often preferred in language models because it captures semantic alignment more effectively, even when vector magnitudes differ. Understanding these metrics is crucial because they define how systems retrieve results, rank recommendations, and group similar items.
4. Clustering reveals conceptual groupings
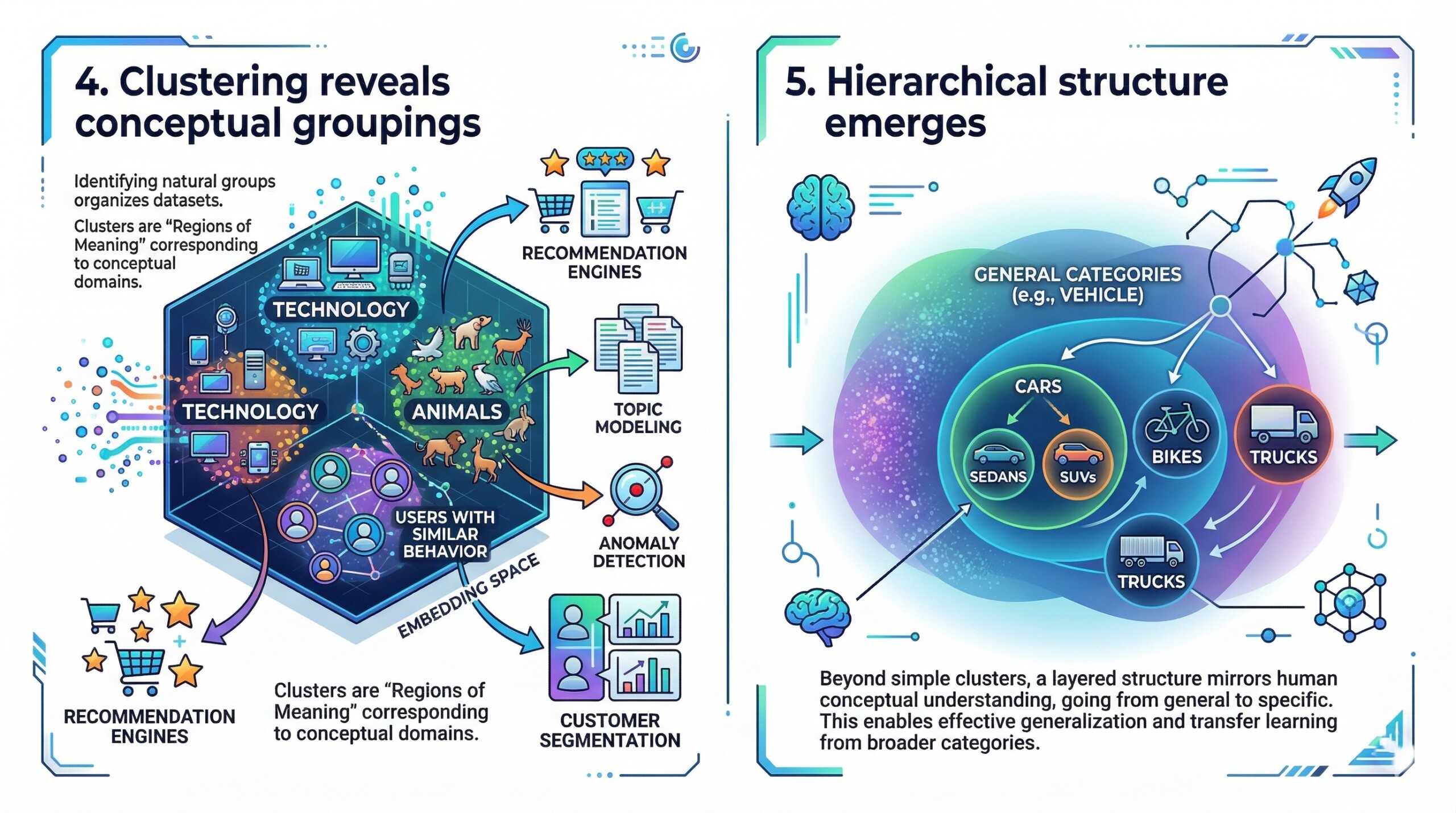
One of the most observable properties of embedding spaces is the emergence of clusters. These clusters represent groups of similar items, such as words related to technology, images of animals, or users with similar behavioral patterns. Clustering algorithms can identify these groups, making it easier to organize and interpret large datasets.
However, clustering is not just a visualization tool – it has practical applications. It powers recommendation engines, topic modeling, anomaly detection, and customer segmentation. By identifying natural groupings in data, systems can make more informed decisions. Clusters essentially act as “regions of meaning,” where each region corresponds to a conceptual domain. A constantly updated Whatsapp channel awaits your participation.
5. Hierarchical structure emerges
Beyond simple clustering, embedding spaces often exhibit hierarchical organization. Broad concepts occupy larger, more diffuse regions, while specific concepts form tighter clusters within those regions. This creates a layered structure where general categories encompass more specific subcategories.
For instance, the concept of “vehicle” may include subclusters like “cars,” “bikes,” and “trucks,” each with its own internal structure. This hierarchy mirrors human conceptual understanding and allows models to generalize effectively. It also enables transfer learning, where knowledge from broader categories can inform more specific tasks.
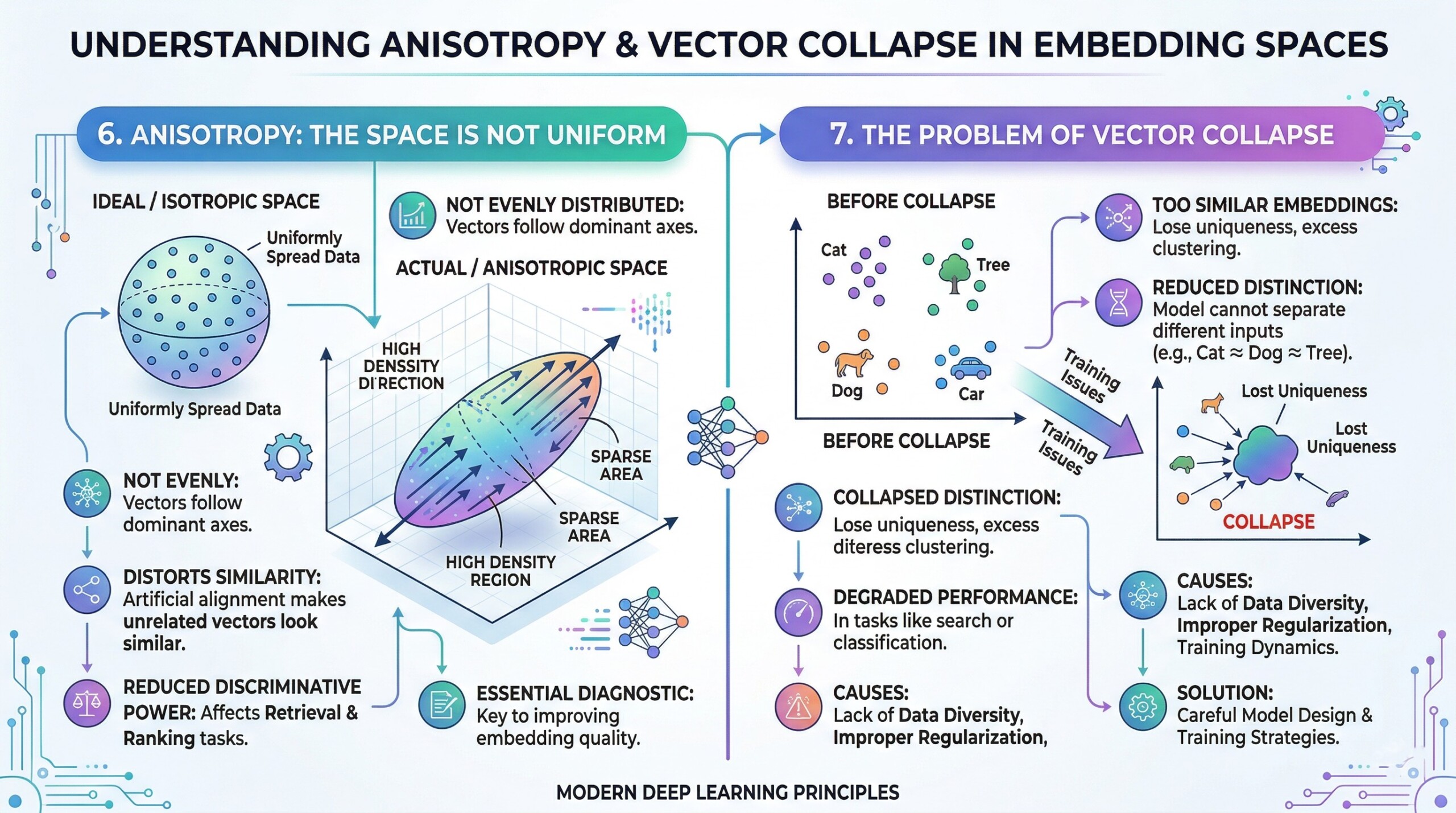
6. Anisotropy: The space is not uniform
A critical but often overlooked property of embedding spaces is anisotropy, meaning the space is not evenly distributed in all directions. Instead of being uniformly spread out, vectors tend to cluster along certain dominant directions. This creates regions of high density and areas that are relatively sparse.
Anisotropy can distort similarity calculations because many vectors may appear artificially similar due to their alignment along these dominant directions. This can reduce the discriminative power of embeddings and affect tasks like retrieval and ranking. Understanding anisotropy is essential for diagnosing and improving embedding quality. Excellent individualised mentoring programmes available.
7. The problem of vector collapse
Closely related to anisotropy is the phenomenon of vector collapse, where many embeddings become too similar to each other. In such cases, vectors lose their uniqueness and cluster excessively in a narrow region of the space. This reduces the model’s ability to distinguish between different inputs.
Vector collapse can occur due to training dynamics, lack of diversity in data, or improper regularization. When it happens, the embedding space becomes less informative, leading to degraded performance in tasks like search or classification. Addressing this issue requires careful model design and training strategies.
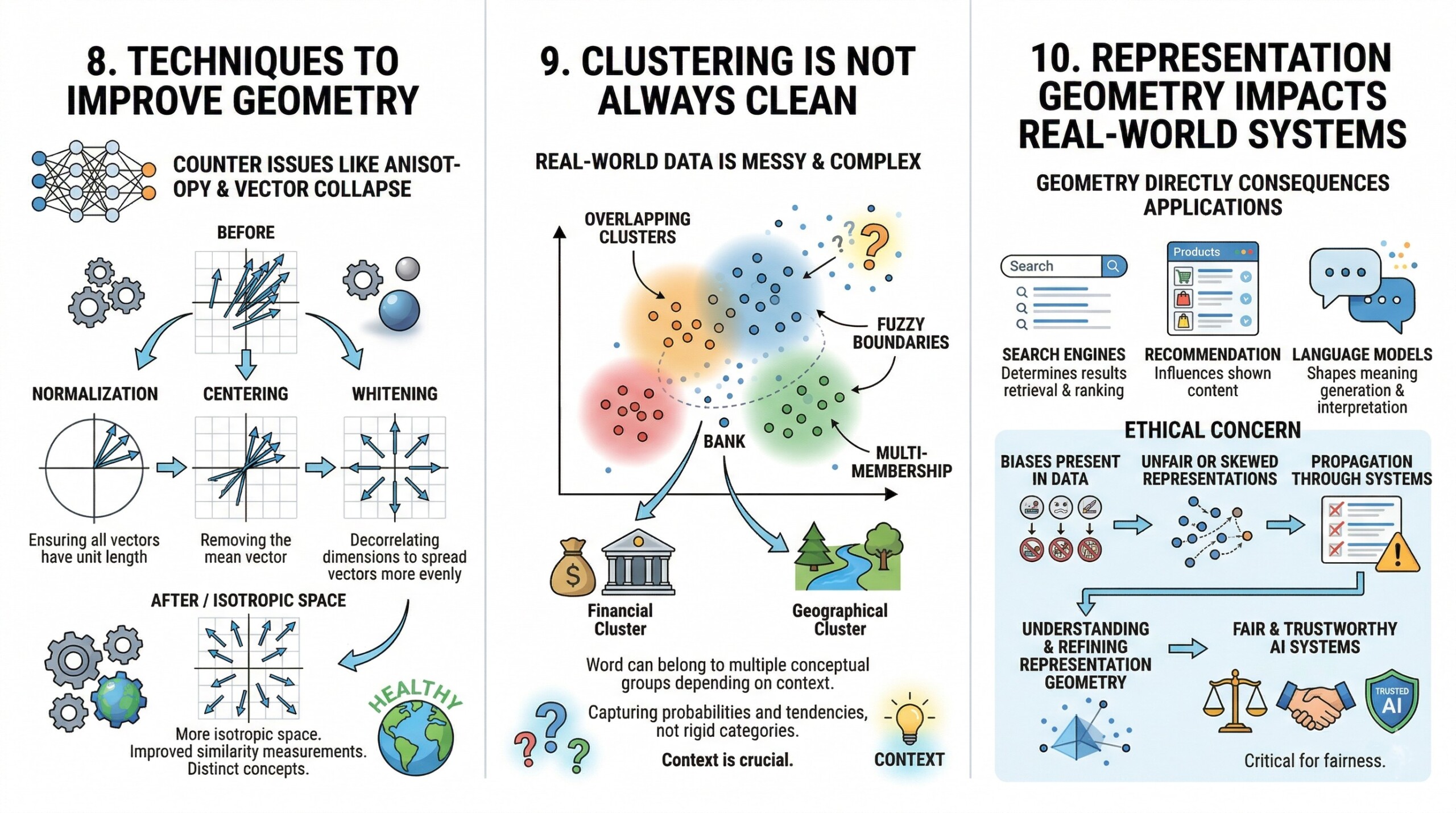
8. Techniques to improve geometry
To counter issues like anisotropy and vector collapse, researchers have developed techniques to improve the geometry of embedding spaces. These include normalization (ensuring all vectors have unit length), centering (removing the mean vector), and whitening (decorrelating dimensions to spread vectors more evenly).
Such techniques aim to make the embedding space more isotropic, meaning evenly distributed in all directions. This improves the quality of similarity measurements and enhances the model’s ability to differentiate between concepts. Better geometry leads to more robust and reliable AI systems. Subscribe to our free AI newsletter now.
9. Clustering is not always clean
While clustering provides valuable insights, it is rarely perfect. Real-world data is messy, and embedding spaces reflect this complexity. Clusters may overlap, boundaries may be fuzzy, and some data points may belong to multiple conceptual groups depending on context.
For example, a word like “bank” can belong to both financial and geographical clusters depending on usage. This ambiguity highlights the importance of context in interpreting embeddings. It also shows that embedding spaces capture probabilities and tendencies rather than rigid categories.
10. Representation Geometry impacts real world systems
The geometry of embedding spaces has direct consequences for real-world AI applications. In search engines, it determines which results are retrieved and how they are ranked. In recommendation systems, it influences what content users are shown. In language models, it shapes how meaning is generated and interpreted.
Importantly, biases present in the data can also be encoded in the geometry of the space. This means that unfair or skewed representations can propagate through AI systems. Therefore, understanding and refining representation geometry is not just a technical concern – it is also an ethical one, critical for building fair and trustworthy AI systems. Upgrade your AI-readiness with our masterclass.
Conclusion
Embedding spaces are more than just numerical representations—they are geometric maps of meaning. Through distances, directions, and clusters, they encode how machines interpret relationships between concepts. However, these spaces are not perfectly balanced. Phenomena like anisotropy reveal that embeddings carry structural biases that can influence outcomes in subtle but significant ways.
As AI systems become more central to decision-making, understanding representation geometry is no longer optional – it is essential. By studying how meaning is shaped in these vector spaces, we gain the ability not only to build better models but also to make them more interpretable, fair, and aligned with human expectations.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



