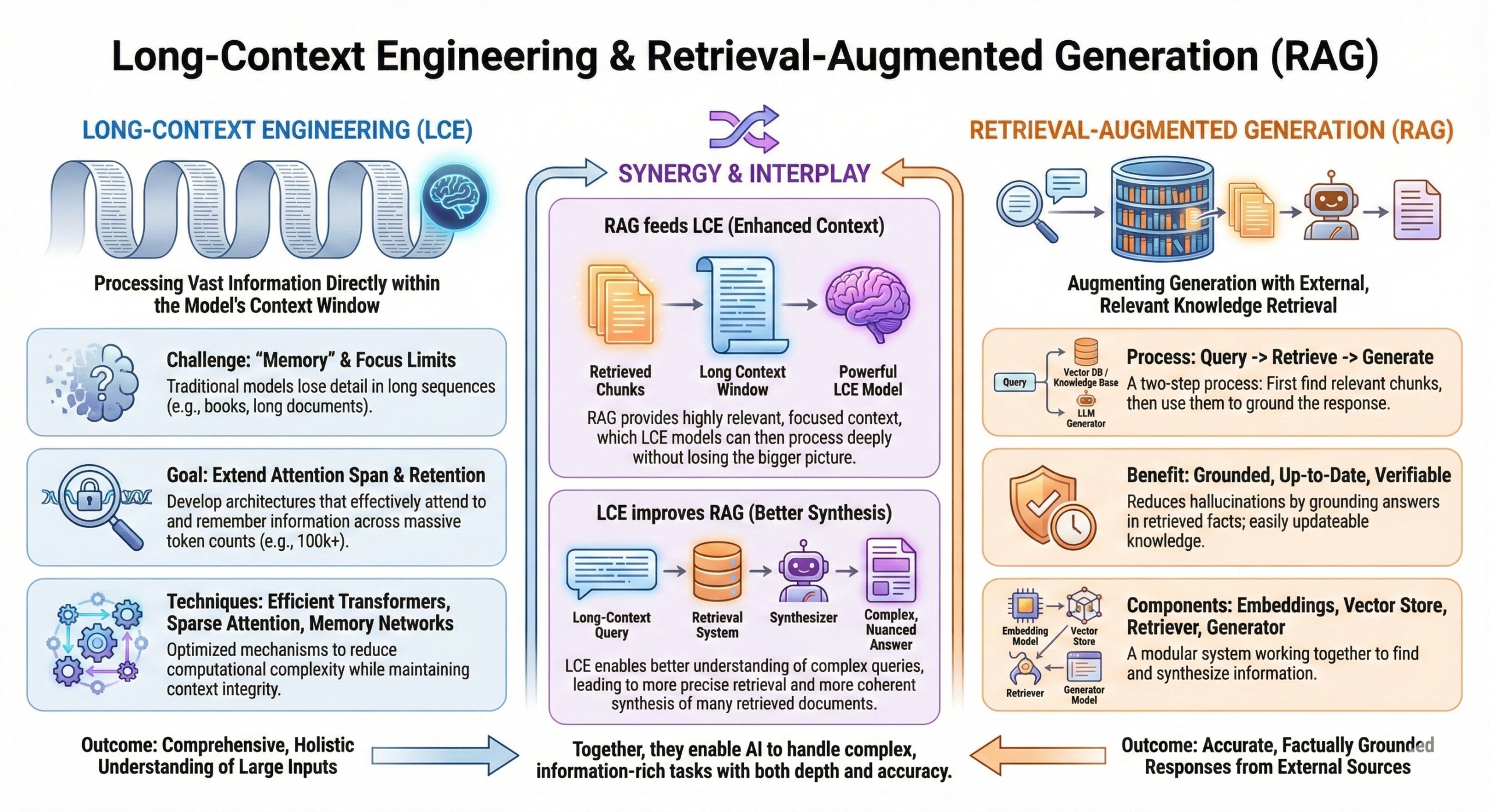
Long-Context Engineering & Retrieval-Augmented Generation (RAG)

Long-Context Engineering & Retrieval-Augmented Generation (RAG)
Technical implementation of vector databases, semantic chunking, and architectural modifications for infinite context windows
Modern LLMs are no longer constrained only by model size or parameter count, but by how much context they can reliably use at inference time. Real-world applications—enterprise search, copilots over large document sets, legal discovery, codebase reasoning, and policy analysis—routinely exceed even million-token windows. This shifts the bottleneck from raw context length to context engineering: how information is selected, compressed, retrieved, and injected into the model without overwhelming attention mechanisms or destroying relevance.
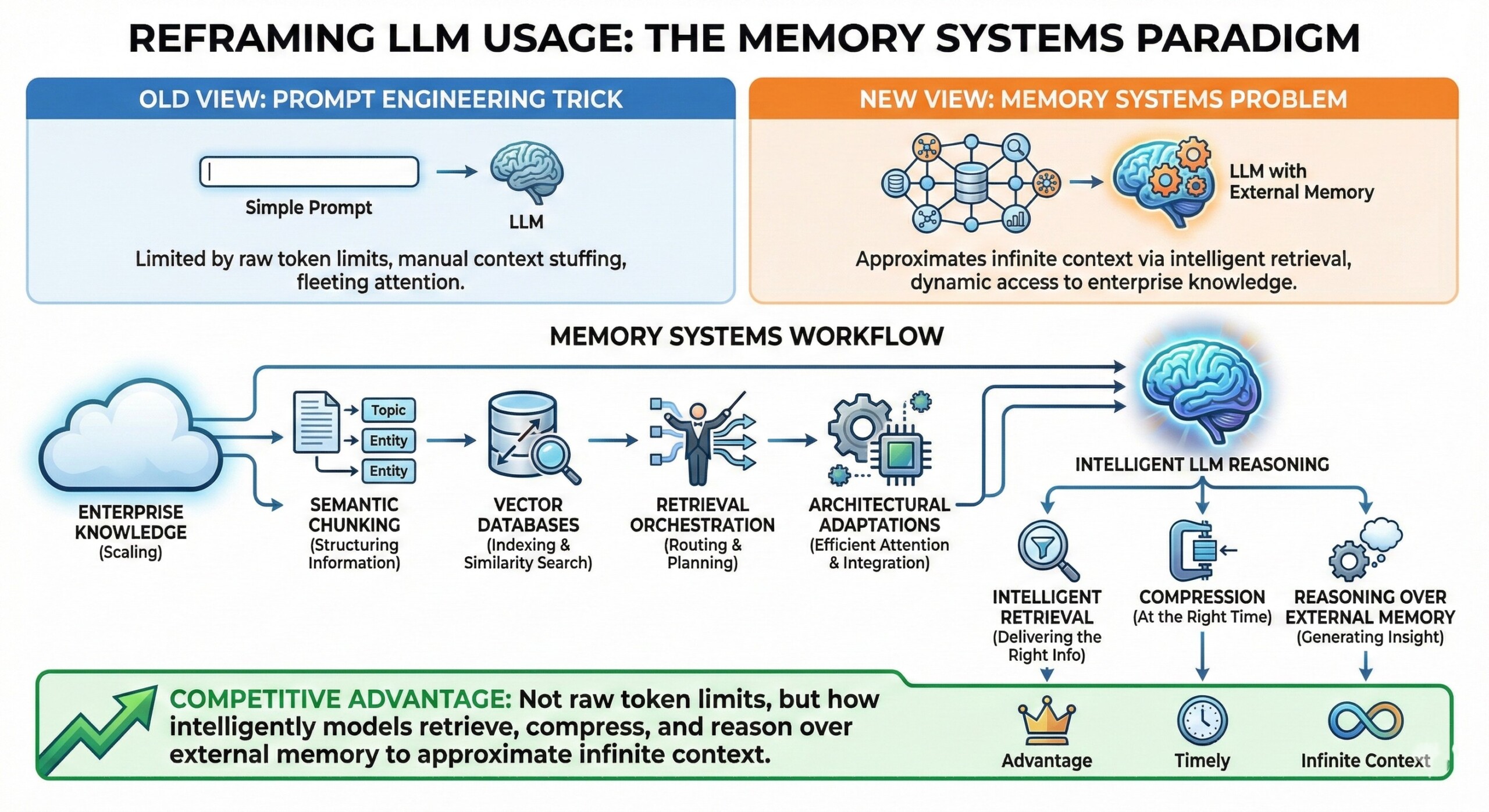
Long-context engineering reframes LLM usage as a systems design problem. Instead of stuffing everything into the prompt, modern stacks combine vector databases, semantic chunking, retrieval orchestration, and architectural adaptations (memory layers, sparse attention, external tools) to approximate “infinite context” while preserving accuracy, latency, and cost. The goal is not to see more tokens—but to see the right tokens at the right time.
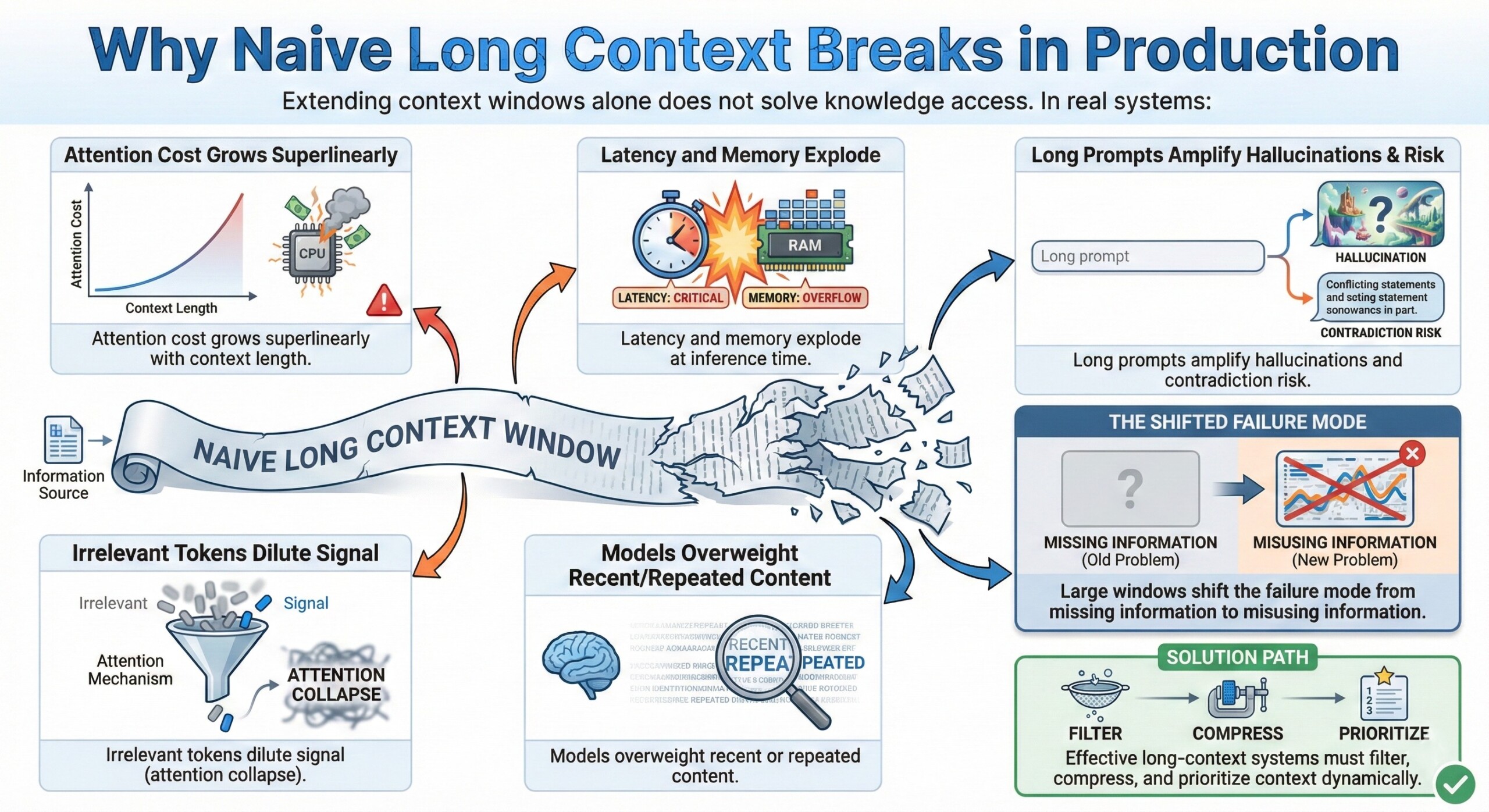
1. Why naive long context breaks in production
Extending context windows alone does not solve knowledge access.
In real systems:
- Attention cost grows superlinearly with context length
- Irrelevant tokens dilute signal (attention collapse)
- Latency and memory explode at inference time
- Models overweight recent or repeated content
- Long prompts amplify hallucinations and contradiction risk
Large windows shift the failure mode from missing information to misusing information. Effective long-context systems must filter, compress, and prioritize context dynamically.
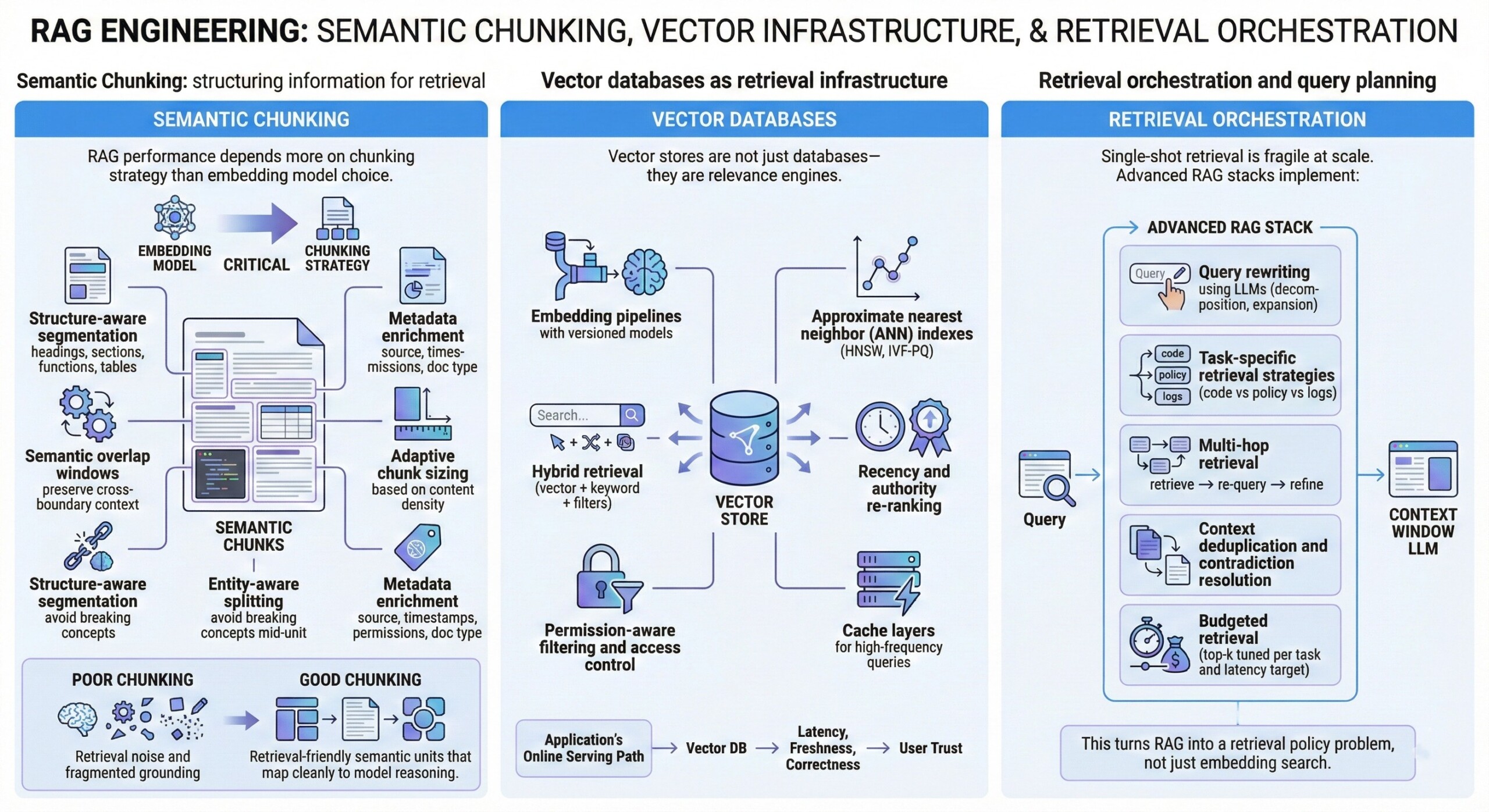
2. Semantic chunking: structuring information for retrieval
RAG performance depends more on chunking strategy than embedding model choice.
Production-grade chunking uses:
- Structure-aware segmentation (headings, sections, functions, tables)
- Semantic overlap windows to preserve cross-boundary context
- Adaptive chunk sizing based on content density
- Entity-aware splitting to avoid breaking concepts mid-unit
- Metadata enrichment (source, timestamps, permissions, doc type)
Poor chunking leads to retrieval noise and fragmented grounding. Good chunking creates retrieval-friendly semantic units that map cleanly to model reasoning. An excellent collection of learning videos awaits you on our Youtube channel.
3. Vector databases as retrieval infrastructure
Vector stores are not just databases—they are relevance engines.
Key engineering components:
- Embedding pipelines with versioned models
- Approximate nearest neighbor (ANN) indexes (HNSW, IVF-PQ)
- Hybrid retrieval (vector + keyword + filters)
- Recency and authority re-ranking
- Permission-aware filtering and access control
- Cache layers for high-frequency queries
Vector DBs become part of the application’s online serving path, so latency, freshness, and correctness directly affect user trust.
4. Retrieval orchestration and query planning
Single-shot retrieval is fragile at scale.
Advanced RAG stacks implement:
- Multi-hop retrieval (retrieve → re-query → refine)
- Query rewriting using LLMs (decomposition, expansion)
- Task-specific retrieval strategies (code vs policy vs logs)
- Context deduplication and contradiction resolution
- Budgeted retrieval (top-k tuned per task and latency target)
This turns RAG into a retrieval policy problem, not just embedding search. A constantly updated Whatsapp channel awaits your participation.
5. Architectural modifications for long-context reasoning
Model architectures increasingly adapt to external memory.
Common approaches:
- Sparse or sliding-window attention to reduce attention cost
- Hierarchical attention (summaries → details)
- Memory tokens / scratchpads for persistent state
- External tool memory (documents, DB queries, APIs)
- Retrieval-aware prompting (grounding formats, citations)
Long-context performance is now a co-design problem between model architecture and memory access patterns.
6. Compression, summarization, and context distillation
Infinite context requires lossy compression.
Production systems use:
- Query-conditioned summarization
- Progressive context distillation (summarize → retrieve → refine)
- Salience filtering (drop low-value tokens)
- Fact tables and structured extracts
- Memory aging policies (what gets forgotten)
This replaces raw recall with relevance-preserving memory. Excellent individualised mentoring programmes available.
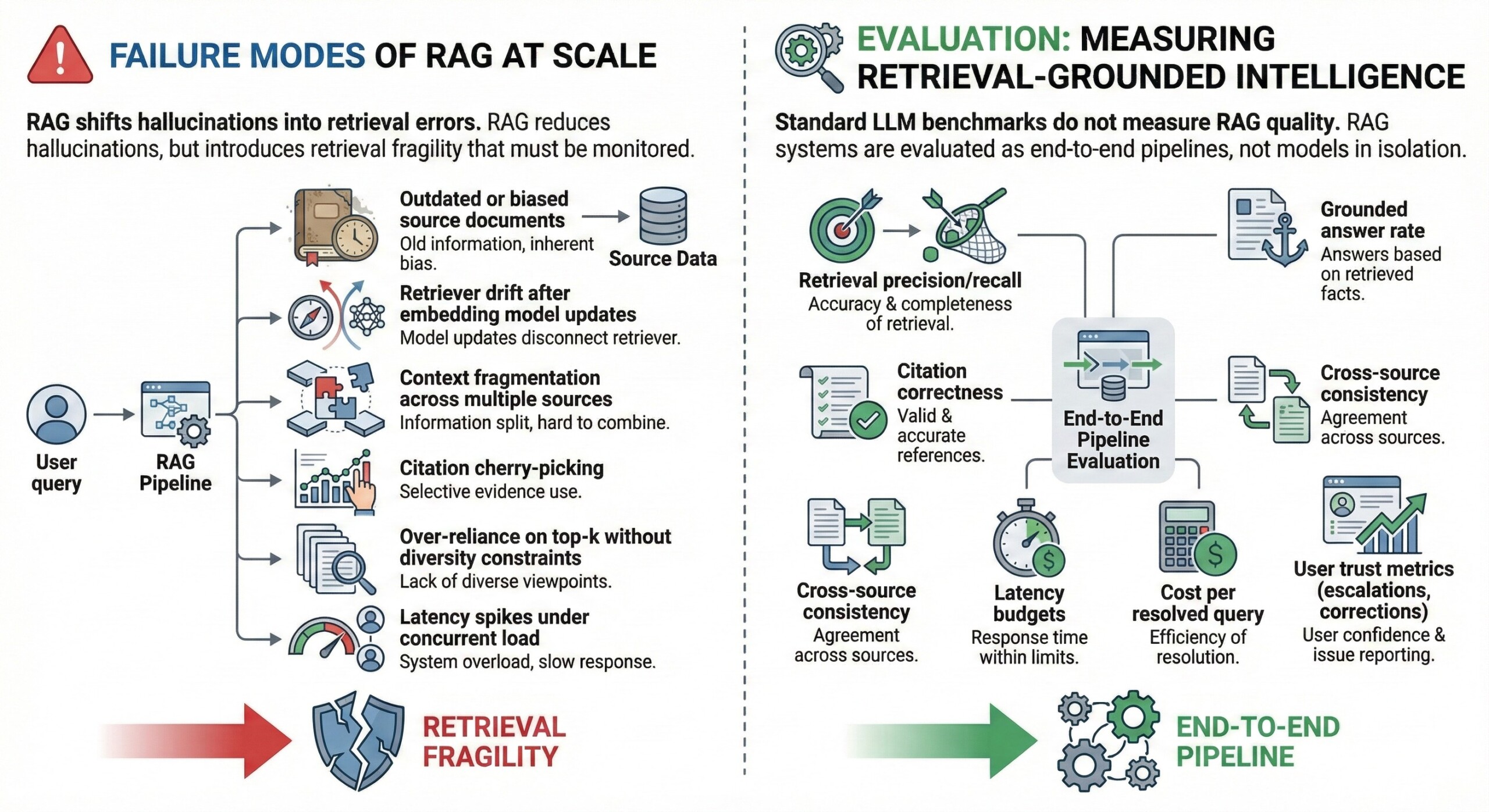
7. Failure modes of RAG at scale
RAG shifts hallucinations into retrieval errors.
Common failure modes:
- Outdated or biased source documents
- Retriever drift after embedding model updates
- Context fragmentation across multiple sources
- Citation cherry-picking
- Over-reliance on top-k without diversity constraints
- Latency spikes under concurrent load
RAG reduces hallucinations, but introduces retrieval fragility that must be monitored.
8. Evaluation: measuring retrieval-grounded intelligence
Standard LLM benchmarks do not measure RAG quality.
Production evaluation focuses on:
- Retrieval precision/recall
- Grounded answer rate
- Citation correctness
- Cross-source consistency
- Latency budgets
- Cost per resolved query
- User trust metrics (escalations, corrections)
RAG systems are evaluated as end-to-end pipelines, not models in isolation. Subscribe to our free AI newsletter now.
9. Engineering trade-offs in long-context systems
Long-context engineering introduces unavoidable trade-offs:
- Recall vs precision
- Latency vs depth of retrieval
- Cost vs retrieval breadth
- Freshness vs caching
- Model context vs external memory
- Simplicity vs orchestration complexity
There is no universal configuration; optimal setups are use-case specific.
10. The future: toward infinite context via system co-design
“Infinite context” will not come from bigger windows alone.
Emerging directions:
- Memory-native model architectures
- Retrieval-aware training objectives
- Sparse MoE routing for context tokens
- On-device retrieval + cloud grounding
- Continual memory refresh pipelines
- Policy-aware memory access layers
Long-context AI is becoming a memory engineering discipline, blending information retrieval, systems design, and model architecture.
Upgrade your AI-readiness with our masterclass.
Summary
Long-context engineering and RAG reframe LLM usage as a memory systems problem rather than a prompt engineering trick. Vector databases, semantic chunking, retrieval orchestration, and architectural adaptations collectively approximate infinite context by delivering the right information at the right time. As context windows grow and enterprise knowledge scales, competitive advantage will come not from raw token limits, but from how intelligently models retrieve, compress, and reason over external memory.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



