Multimodal learning – basics

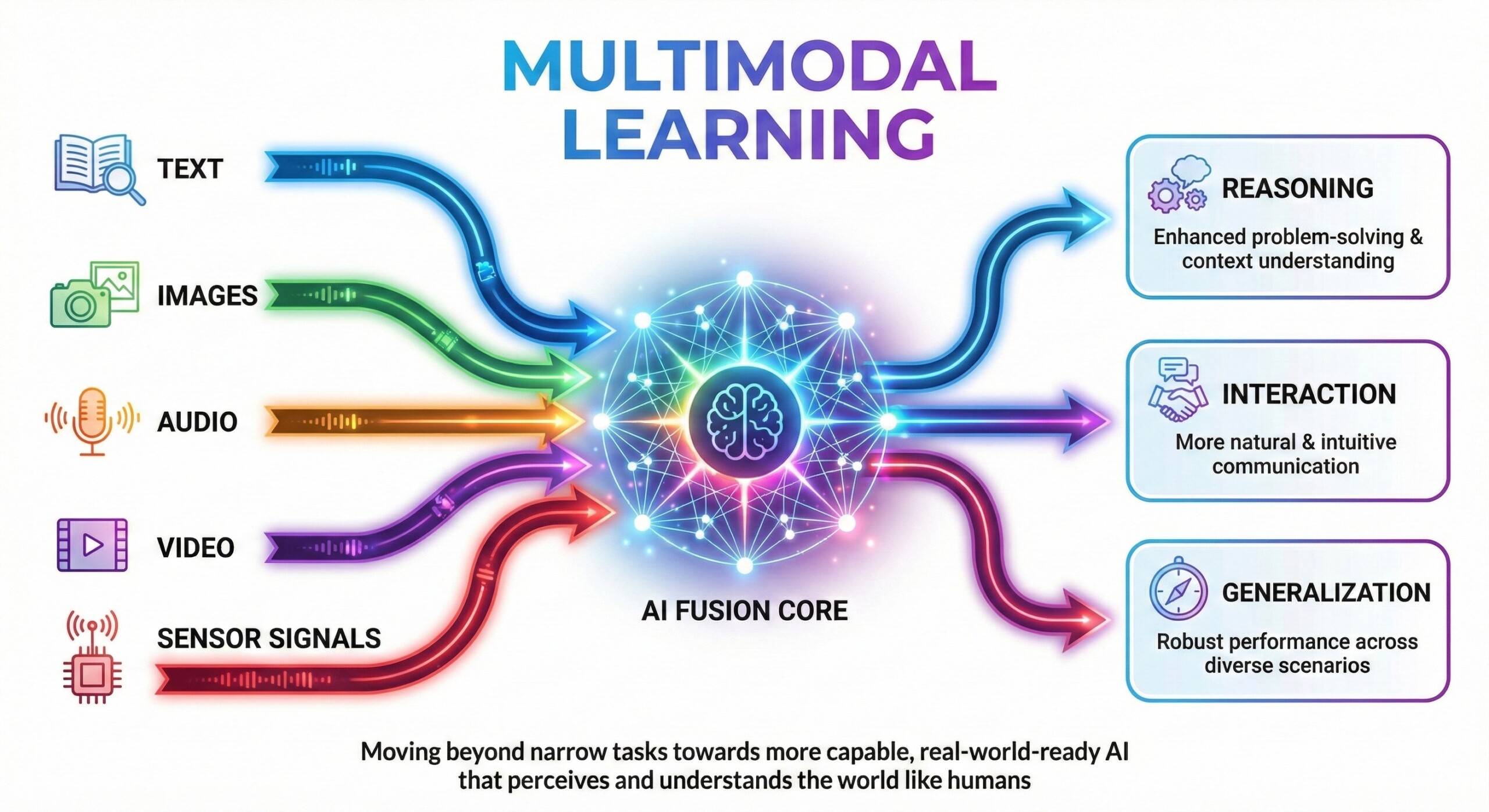
Multimodal learning represents a fundamental shift in how artificial intelligence systems perceive and understand the world. Humans naturally integrate information from multiple senses such as sight, sound, and language to form coherent understanding. Multimodal AI aims to replicate this capability by learning jointly from diverse data types like text, images, audio, video, and sensor signals. As AI systems move beyond narrow tasks, multimodal learning becomes essential for building models that can reason, interact, and generalize more effectively in complex real-world environments.
1. Why multimodal learning matters
Real-world information is rarely isolated to a single modality. A conversation includes words, tone, facial expressions, and context. A medical diagnosis may involve imaging, patient history, lab reports, and clinician notes. Single-modality AI systems struggle to capture this richness. Multimodal learning allows AI to combine complementary signals, improving robustness, context awareness, and decision quality.
As AI systems are deployed in domains like healthcare, robotics, education, and human–computer interaction, the ability to integrate multiple modalities becomes critical. Multimodal learning enables systems to handle ambiguity better, compensate for missing or noisy data, and align more closely with how humans naturally process information.
2. What multimodal learning means in AI
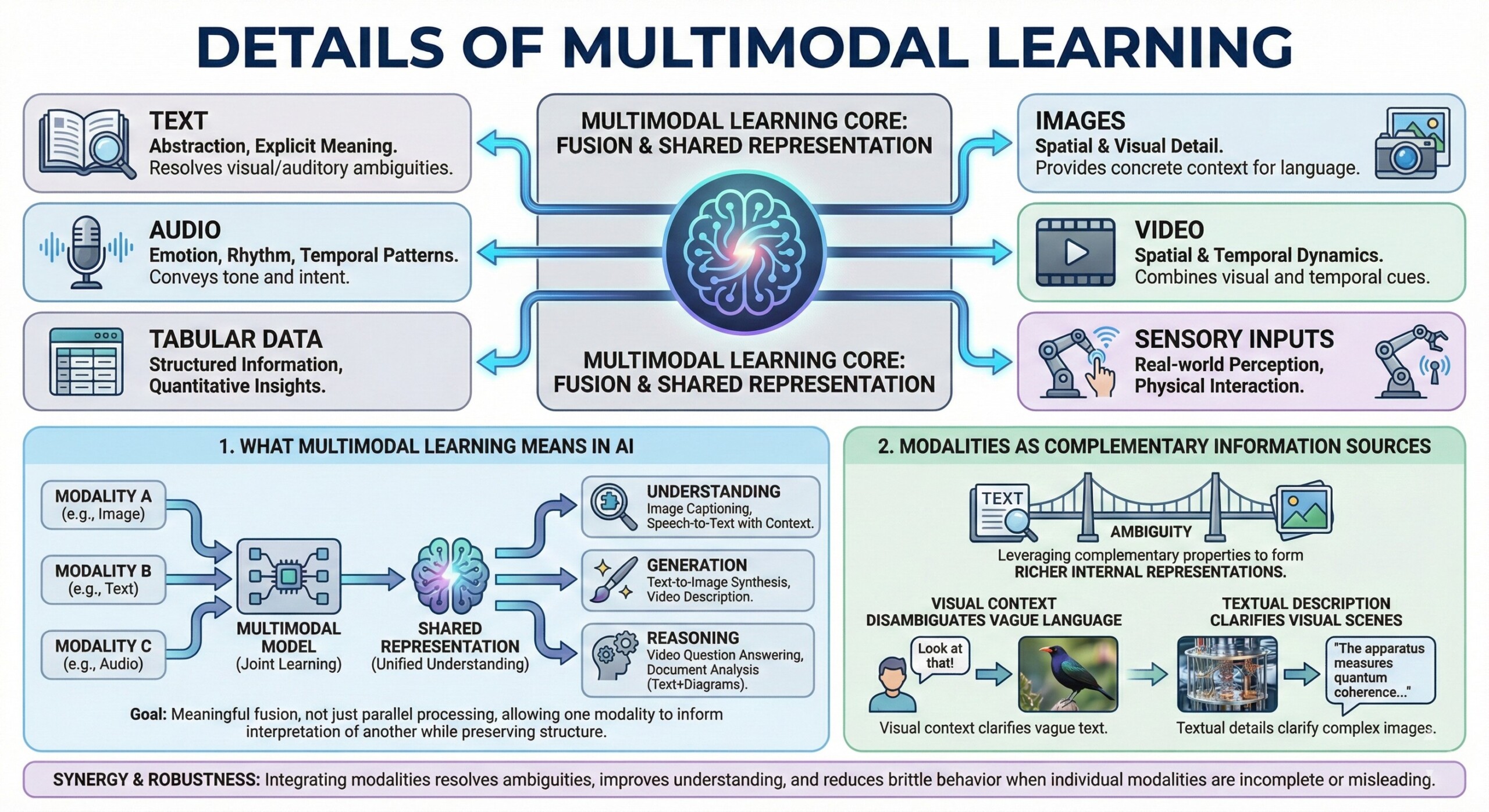
In artificial intelligence, multimodal learning refers to training models on two or more distinct data modalities and enabling them to learn shared representations across those modalities. These modalities may include text, images, audio, video, tabular data, or sensory inputs. The goal is not merely parallel processing, but meaningful fusion that allows one modality to inform interpretation of another.
Multimodal learning tasks may involve understanding, generation, or reasoning. Examples include image captioning, video question answering, speech-to-text with contextual grounding, or models that can read documents combining text and diagrams. Effective multimodal systems must align information across modalities while preserving modality-specific structure. An excellent collection of learning videos awaits you on our Youtube channel.
3. Modalities as complementary information sources
Each modality carries different strengths and limitations. Text excels at abstraction and explicit meaning. Images capture spatial and visual detail. Audio conveys emotion, rhythm, and temporal patterns. Video combines spatial and temporal dynamics. Multimodal learning leverages these complementary properties to form richer internal representations.
By integrating modalities, AI systems can resolve ambiguities that would confuse unimodal models. For example, visual context can disambiguate vague language, while textual descriptions can clarify visual scenes. This synergy improves understanding and reduces brittle behavior when one modality is incomplete or misleading.
4. Fusion strategies in multimodal learning
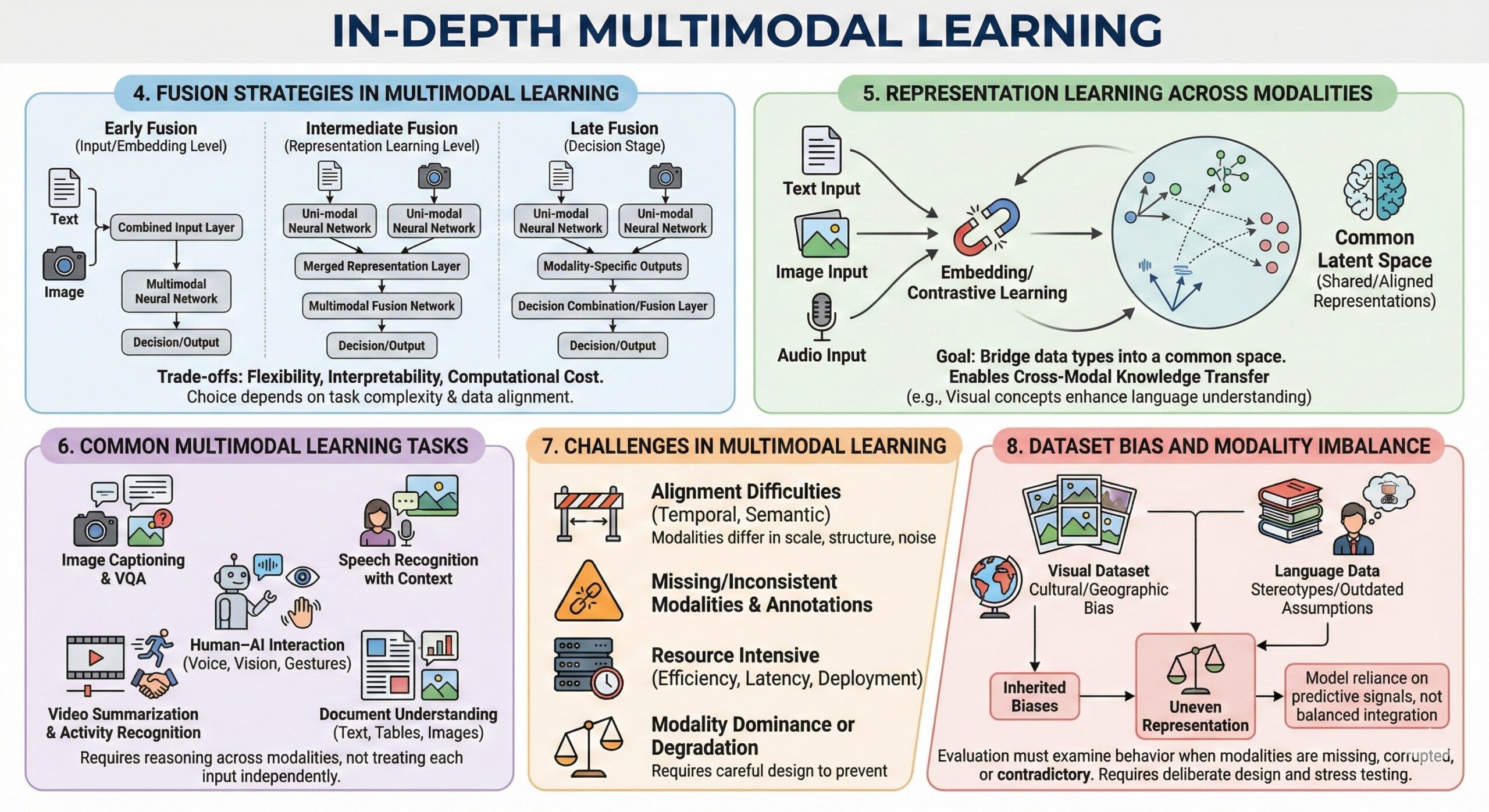
A core challenge in multimodal learning is how and when to combine modalities. Fusion strategies typically fall into three categories:
- Early fusion – modalities are combined at the input or embedding level
- Intermediate fusion – modalities are processed separately, then merged during representation learning
- Late fusion – modality-specific models produce outputs that are combined at the decision stage
Each approach involves trade-offs between flexibility, interpretability, and computational cost. Choosing the right fusion strategy depends on task complexity, data alignment, and performance requirements. A constantly updated Whatsapp channel awaits your participation.
5. Representation learning across modalities
Multimodal systems aim to learn shared or aligned representations that bridge different data types. This often involves embedding text, images, or audio into a common latent space where semantic similarity can be measured across modalities. Contrastive learning techniques are frequently used to align related inputs, such as matching images with their captions.
Learning such representations allows models to transfer knowledge between modalities. For example, visual concepts learned from images can enhance language understanding, and linguistic structure can guide visual reasoning. This cross-modal transfer is a key advantage of multimodal learning.
6. Common multimodal learning tasks
Multimodal learning supports a wide range of tasks that go beyond traditional single-input problems. Examples include:
- Image captioning and visual question answering
• Speech recognition with contextual understanding
• Video summarization and activity recognition
• Document understanding with text, tables, and images
• Human–AI interaction using voice, vision, and gestures
These tasks require models to reason across modalities rather than treating each input independently. Excellent individualised mentoring programmes available.
7. Challenges in multimodal learning
Despite its promise, multimodal learning introduces significant technical challenges. Modalities often differ in scale, structure, and noise characteristics. Aligning them temporally or semantically can be difficult. Missing modalities, inconsistent annotations, and data imbalance further complicate training.
Additionally, multimodal models tend to be larger and more resource-intensive. This raises concerns around efficiency, latency, and deployment feasibility. Careful model design and training strategies are required to prevent one modality from dominating or degrading overall performance.
8. Dataset bias and modality imbalance
Multimodal datasets inherit biases from each modality and from how they are combined. Visual datasets may reflect cultural or geographic biases, while language data may encode stereotypes or outdated assumptions. When modalities are unevenly represented, models may rely too heavily on the most predictive signal rather than learning balanced integration.
Evaluation must therefore examine how models behave when certain modalities are missing, corrupted, or contradictory. Robust multimodal learning requires deliberate dataset design and stress testing across modality combinations.
Subscribe to our free AI newsletter now.
9. Evaluation of multimodal systems
Evaluating multimodal models is more complex than evaluating unimodal ones. Performance must be assessed not only on task accuracy, but also on cross-modal reasoning, robustness, and generalization. Metrics may vary by modality and task, making comparison difficult.
Effective evaluation includes ablation studies, modality drop tests, and scenario-based assessments. These approaches help reveal whether a model truly integrates information or merely exploits shortcuts in one dominant modality.
10. Multimodal learning and the future of AI
Multimodal learning is a stepping stone toward more general and interactive AI systems. By integrating diverse inputs, AI can move closer to human-like perception and reasoning. This capability is essential for embodied AI, assistive technologies, scientific discovery, and rich human–machine collaboration.
As models grow more capable, multimodal learning will increasingly shape how AI systems understand context, communicate meaning, and act responsibly in the world. Its development will influence not only technical performance, but also usability, safety, and trust. Upgrade your AI-readiness with our masterclass.
Summary
Multimodal learning enables AI systems to combine text, vision, audio, and other data types into coherent understanding. By integrating complementary modalities, these systems achieve greater robustness, context awareness, and generalization than single-modality models. However, multimodal learning also introduces challenges in representation, fusion, evaluation, and bias management. As AI continues to evolve toward real-world deployment, multimodal learning will remain a foundational capability for building systems that interact meaningfully with complex environments.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



