Neural Architecture Search (NAS) & Hyperparameter Optimization

Neural Architecture Search (NAS) & Hyperparameter Optimization
Automating the design of neural networks using reinforcement learning and Bayesian optimization.
Designing high-performance neural networks is no longer just about picking a known architecture and tuning a few knobs. Modern AI systems increasingly rely on automation to discover architectures and hyperparameters that outperform human-designed models for specific tasks and constraints.
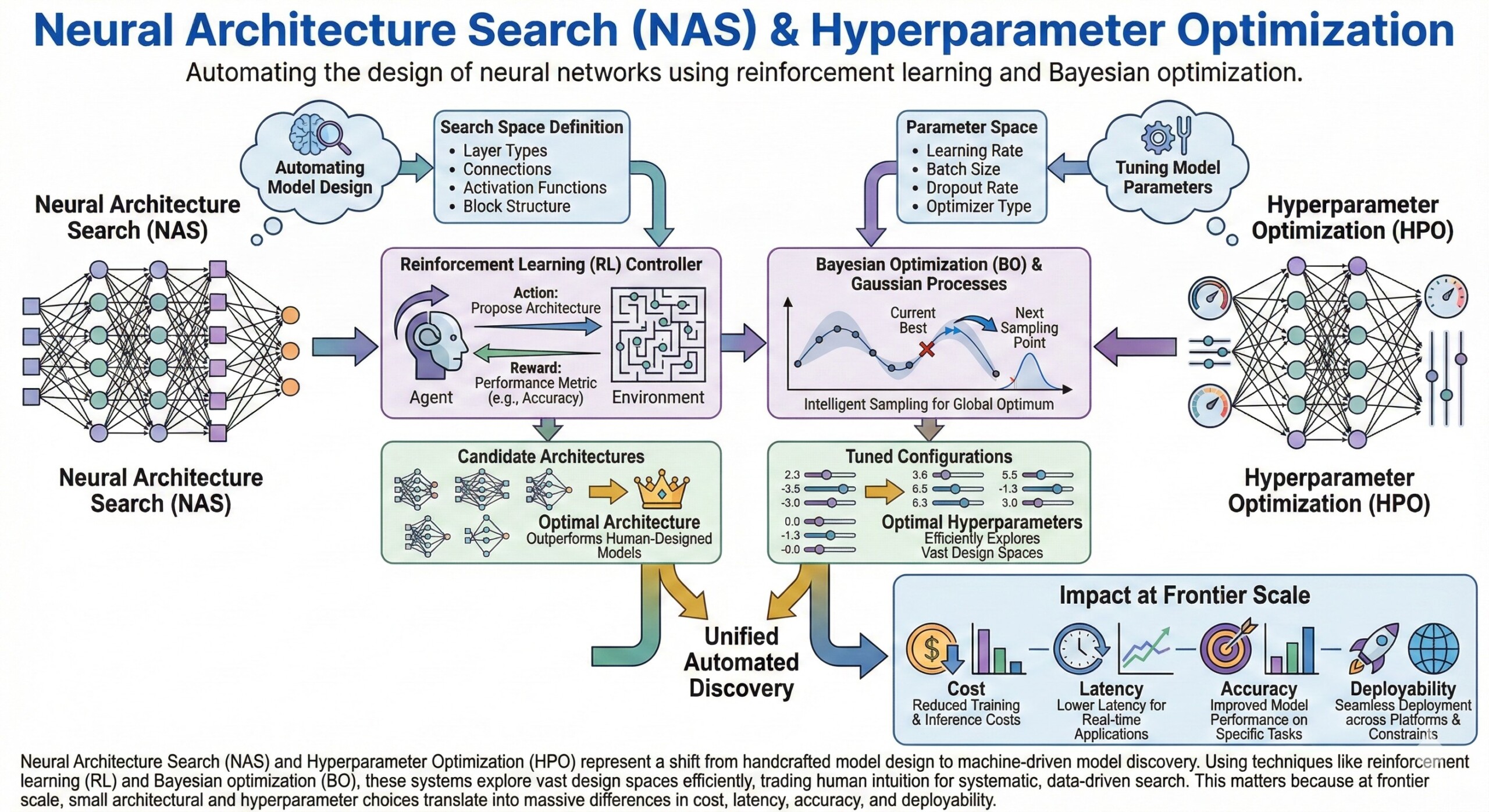
Neural Architecture Search (NAS) and Hyperparameter Optimization (HPO) represent a shift from handcrafted model design to machine-driven model discovery. Using techniques like reinforcement learning (RL) and Bayesian optimization (BO), these systems explore vast design spaces efficiently, trading human intuition for systematic, data-driven search.
This matters because at frontier scale, small architectural and hyperparameter choices translate into massive differences in cost, latency, accuracy, and deployability.
1. NAS formalizes architecture design as a search problem
Instead of manually choosing layers, widths, depths, and connections, NAS defines a search space of possible architectures and an objective function such as accuracy, latency, or cost. The system then explores this space automatically.
This reframes neural network design from art into a computational optimization problem over discrete and continuous design variables.
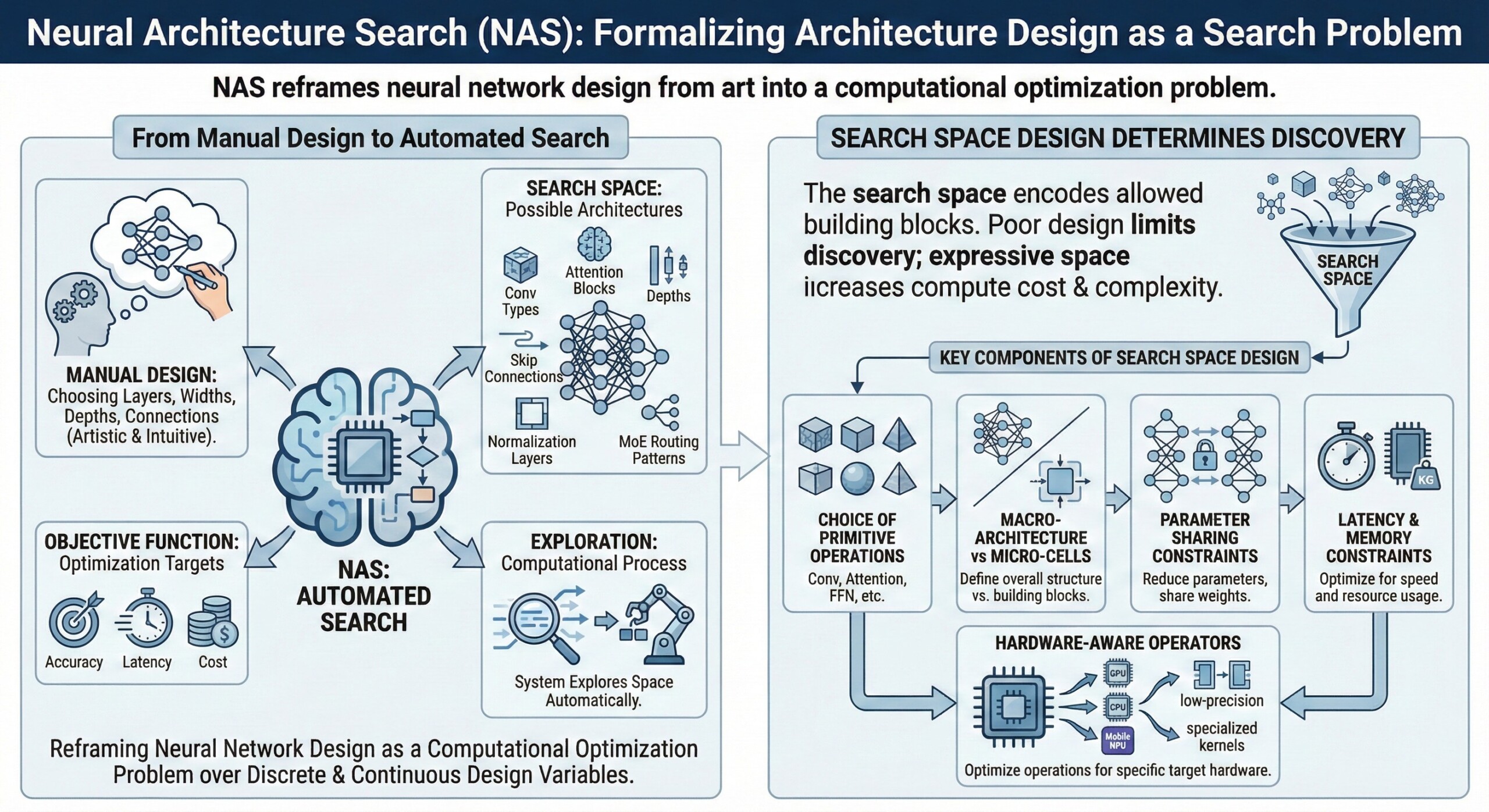
2. Search space design determines what NAS can discover
The search space encodes which building blocks are allowed: convolution types, attention blocks, depth options, skip connections, normalization layers, and even routing patterns in MoE models.
A poorly designed space limits discovery, while an expressive space increases compute cost and search complexity.
Key components of search space design:
- Choice of primitive operations (Conv, Attention, FFN, etc.)
- Macro-architecture vs micro-cells
- Parameter sharing constraints
- Latency and memory constraints
- Hardware-aware operators
An excellent collection of learning videos awaits you on our Youtube channel.
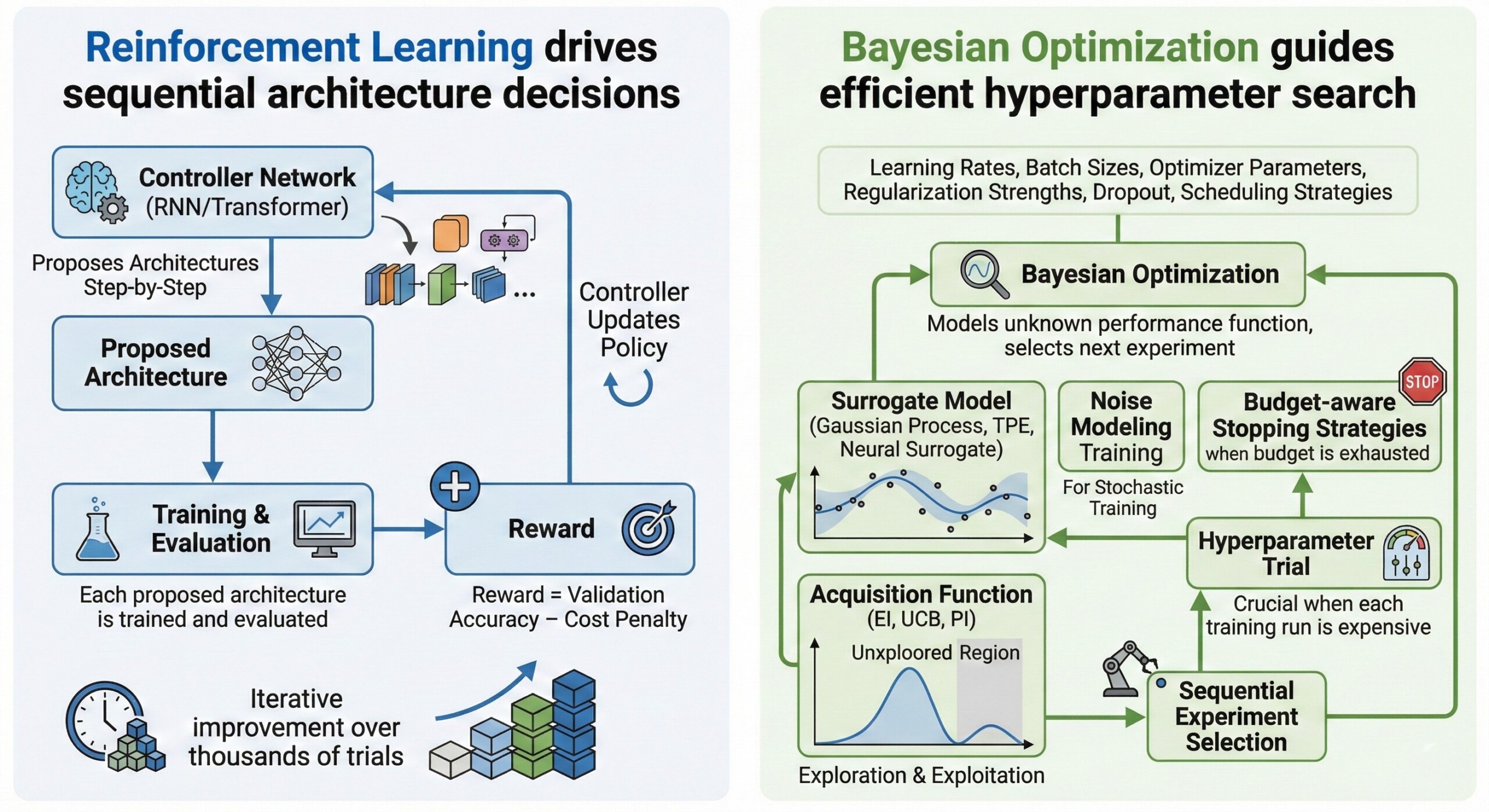
3. Reinforcement Learning drives sequential architecture decisions
In RL-based NAS, a controller network (often an RNN or Transformer) proposes architectures step-by-step. Each proposed architecture is trained and evaluated, and the controller receives a reward based on performance.
Over time, the controller learns to sample better architectures, effectively learning how to design neural networks.
Typical RL loop in NAS:
- Controller proposes architecture
- Model is trained/evaluated
- Reward = validation accuracy – cost penalty
- Controller updates policy
- Iterative improvement over thousands of trials
4. Bayesian Optimization guides efficient hyperparameter search
HPO deals with tuning learning rates, batch sizes, optimizer parameters, regularization strengths, dropout, and scheduling strategies.
Bayesian Optimization models the unknown performance function and selects the next experiment using an acquisition function that balances exploration and exploitation. This is crucial when each model training run is expensive.
Common BO components:
- Surrogate model (Gaussian Process, TPE, Neural surrogate)
- Acquisition function (EI, UCB, PI)
- Sequential experiment selection
- Noise modeling for stochastic training
- Budget-aware stopping strategies
A constantly updated Whatsapp channel awaits your participation.
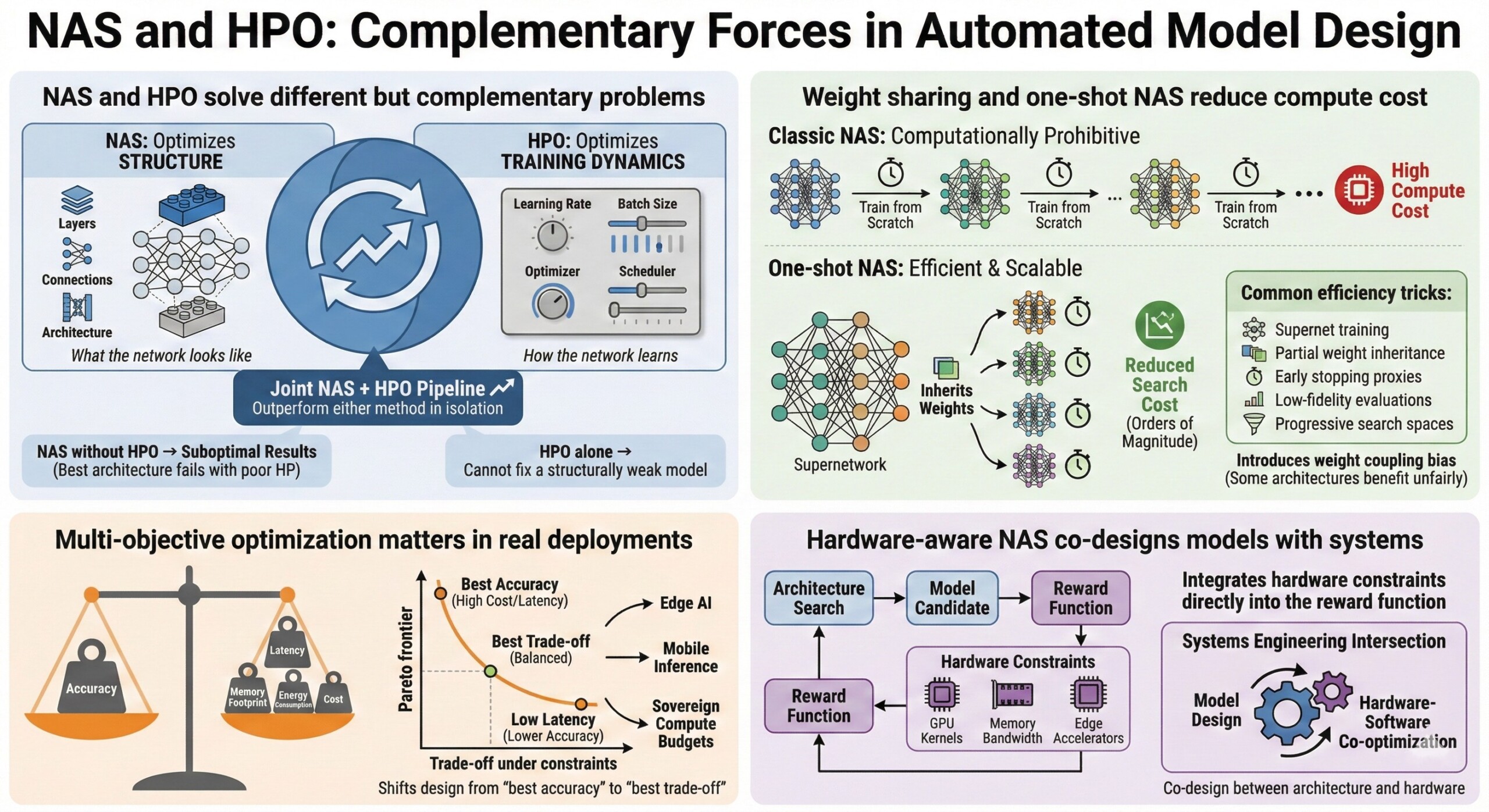
5. NAS and HPO solve different but complementary problems
NAS optimizes structure (what the network looks like), while HPO optimizes training dynamics (how the network learns).
Using NAS without HPO can yield suboptimal results because even the best architecture can fail with poor hyperparameters. Conversely, HPO alone cannot fix a structurally weak model.
In practice, joint NAS + HPO pipelines outperform either method in isolation.
6. Weight sharing and one-shot NAS reduce compute cost
Classic NAS is computationally prohibitive because each candidate model must be trained from scratch. One-shot NAS trains a supernetwork that contains all sub-architectures, allowing candidates to inherit weights.
This reduces search cost by orders of magnitude, but introduces weight coupling bias, where some architectures benefit unfairly from shared training dynamics.
Common efficiency tricks:
- Supernet training
- Partial weight inheritance
- Early stopping proxies
- Low-fidelity evaluations
- Progressive search spaces
Excellent individualised mentoring programmes available.
7. Multi-objective optimization matters in real deployments
Real systems must balance accuracy, latency, memory footprint, energy consumption, and cost. NAS and HPO increasingly operate under Pareto-optimal objectives rather than single-metric accuracy.
This shifts model design from “best accuracy” to “best trade-off under constraints,” especially for edge AI, mobile inference, and sovereign compute budgets.
8. Hardware-aware NAS co-designs models with systems
Modern NAS pipelines integrate hardware constraints directly into the reward function. This enables co-design between architecture and hardware, optimizing for GPU kernels, memory bandwidth, or edge accelerators.
This is where NAS intersects with systems engineering, turning model design into a hardware-software co-optimization problem.
Subscribe to our free AI newsletter now.
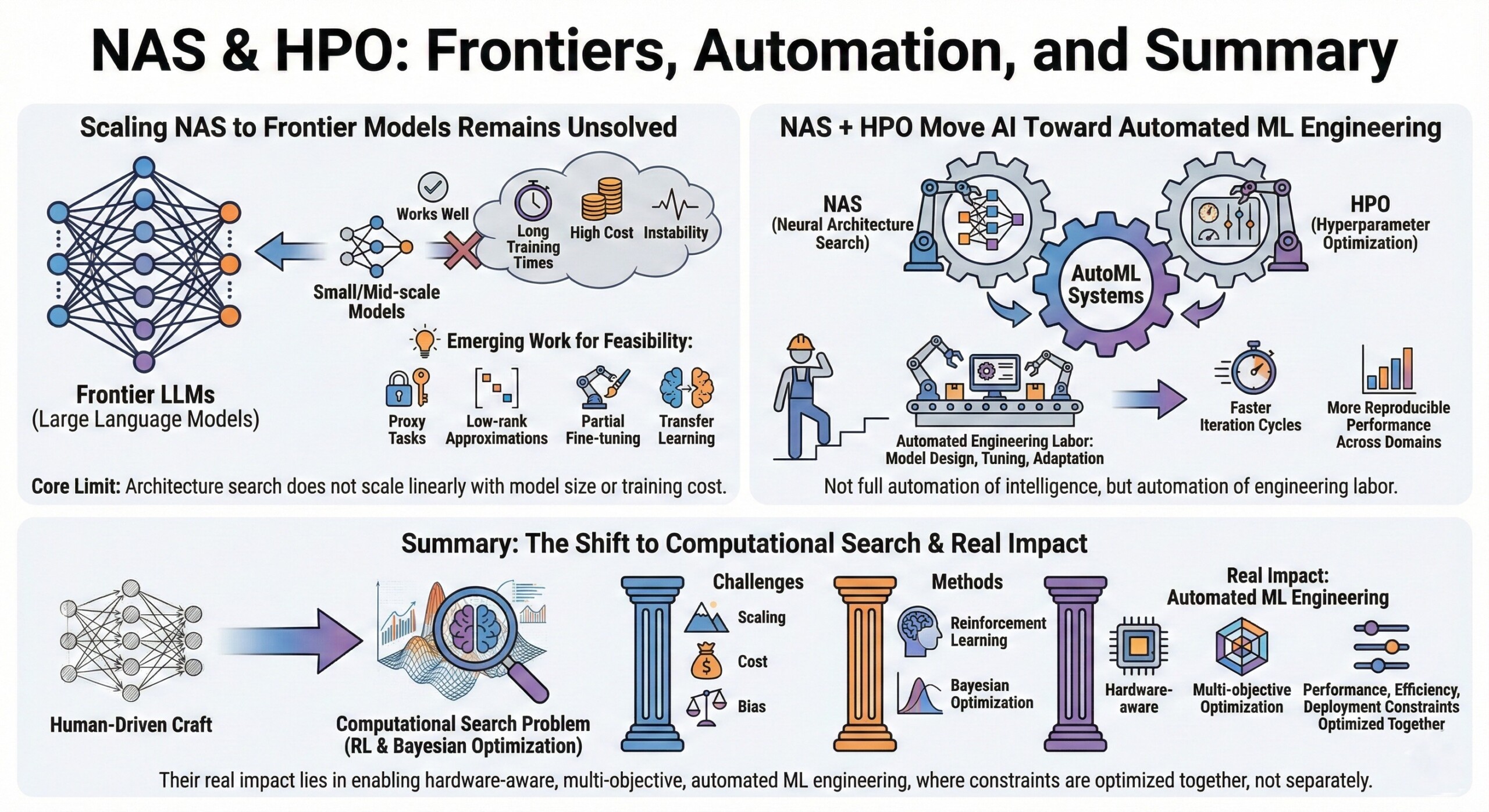
9. Scaling NAS to frontier models remains unsolved
NAS works well for small and mid-scale models, but scaling it to frontier LLMs is difficult due to cost, instability, and long training times.
Emerging work uses proxy tasks, low-rank approximations, partial fine-tuning, and transfer learning to make NAS feasible at large scale.
This highlights a core limit: architecture search does not scale linearly with model size or training cost.
10. NAS + HPO move AI toward automated ML engineering
Together, NAS and HPO represent a shift toward AutoML systems that automate much of what ML engineers currently do manually.
This is not full automation of intelligence, but automation of engineering labor—model design, tuning, and adaptation to constraints. The result is faster iteration cycles and more reproducible performance improvements across domains. Upgrade your AI-readiness with our masterclass.
Summary
Neural Architecture Search and Hyperparameter Optimization convert model design from a human-driven craft into a computational search problem guided by reinforcement learning and Bayesian optimization. While powerful, these methods face scaling, cost, and bias challenges. Their real impact lies in enabling hardware-aware, multi-objective, automated ML engineering – where performance, efficiency, and deployment constraints are optimized together, not separately.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



