NLP to LLMs

1. What is NLP and why it matters
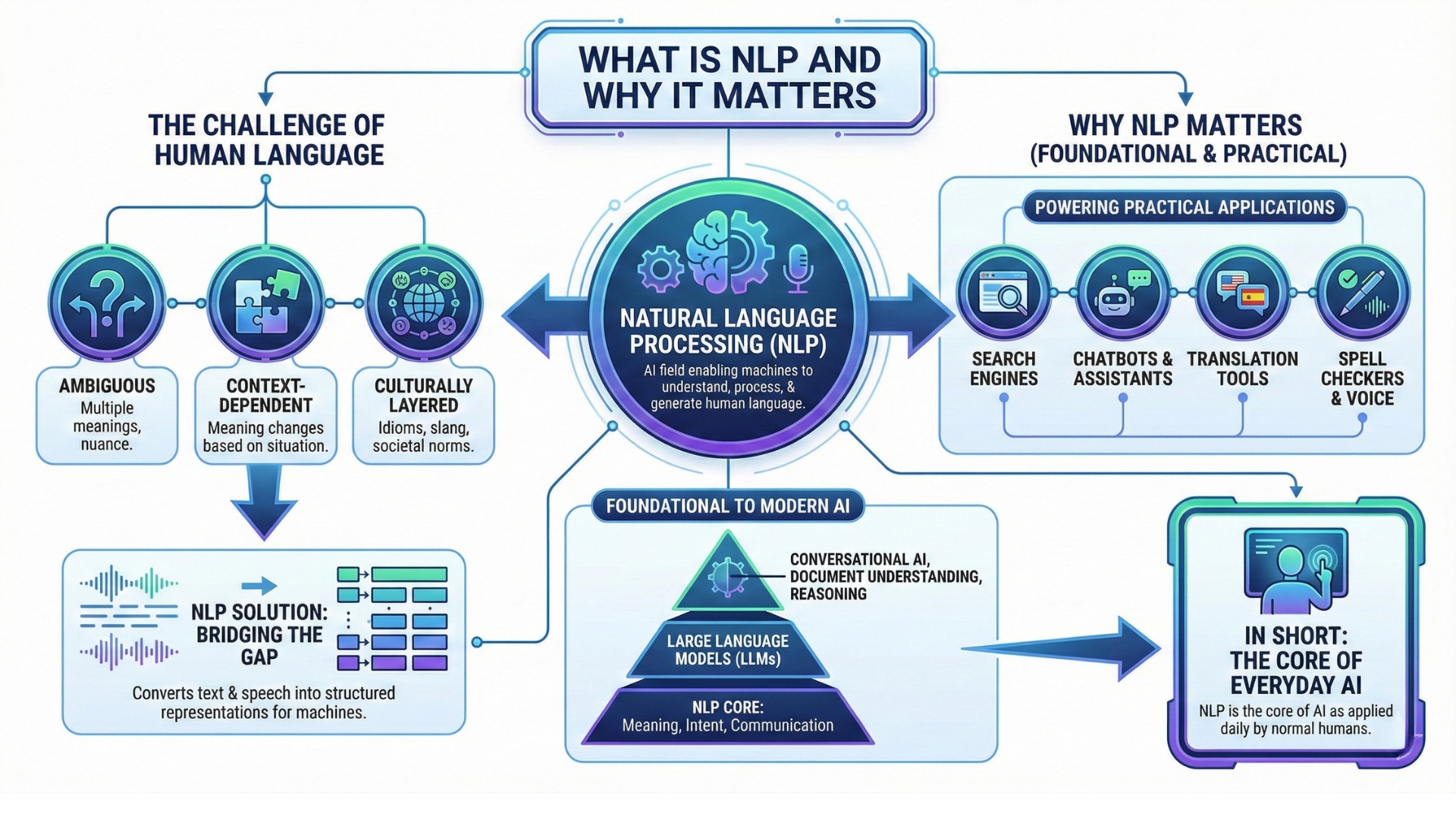
Natural Language Processing, or NLP, is the field of artificial intelligence focused on enabling machines to understand, process, and generate human language. Language is the most natural interface for humans, but it is highly ambiguous, context-dependent, and culturally layered. NLP attempts to bridge this gap by converting text and speech into structured representations that machines can work with.
For decades, NLP powered practical applications such as search engines, spell checkers, chatbots, translation tools, and voice assistants. What makes NLP foundational is that it deals directly with meaning, intent, and communication. Modern AI systems, including large language models, are built on top of NLP. Without NLP, there would be no conversational AI, document understanding, or reasoning over text.
In short, NLP is the core of AI as applied daily by normal humans.
2. Early NLP: Rules, statistics, and limitations
The earliest NLP systems relied on hand-written rules created by linguists and engineers. These systems used grammar trees, dictionaries, and if-then logic to parse sentences. While precise, they were brittle and failed when language deviated from expected patterns.
In the 1990s and early 2000s, statistical NLP emerged. Models learned probabilities from text corpora, enabling tasks like part-of-speech tagging and basic translation. However, these systems struggled with context, long-range dependencies, and semantic understanding. They treated language as surface-level patterns rather than meaning-rich structures.
This phase revealed a core challenge: language understanding cannot be fully captured by rigid rules or shallow statistics alone. Another breakthrough was needed for it to go mainstream. An excellent collection of learning videos awaits you on our Youtube channel.
3. Word embeddings and the shift toward meaning
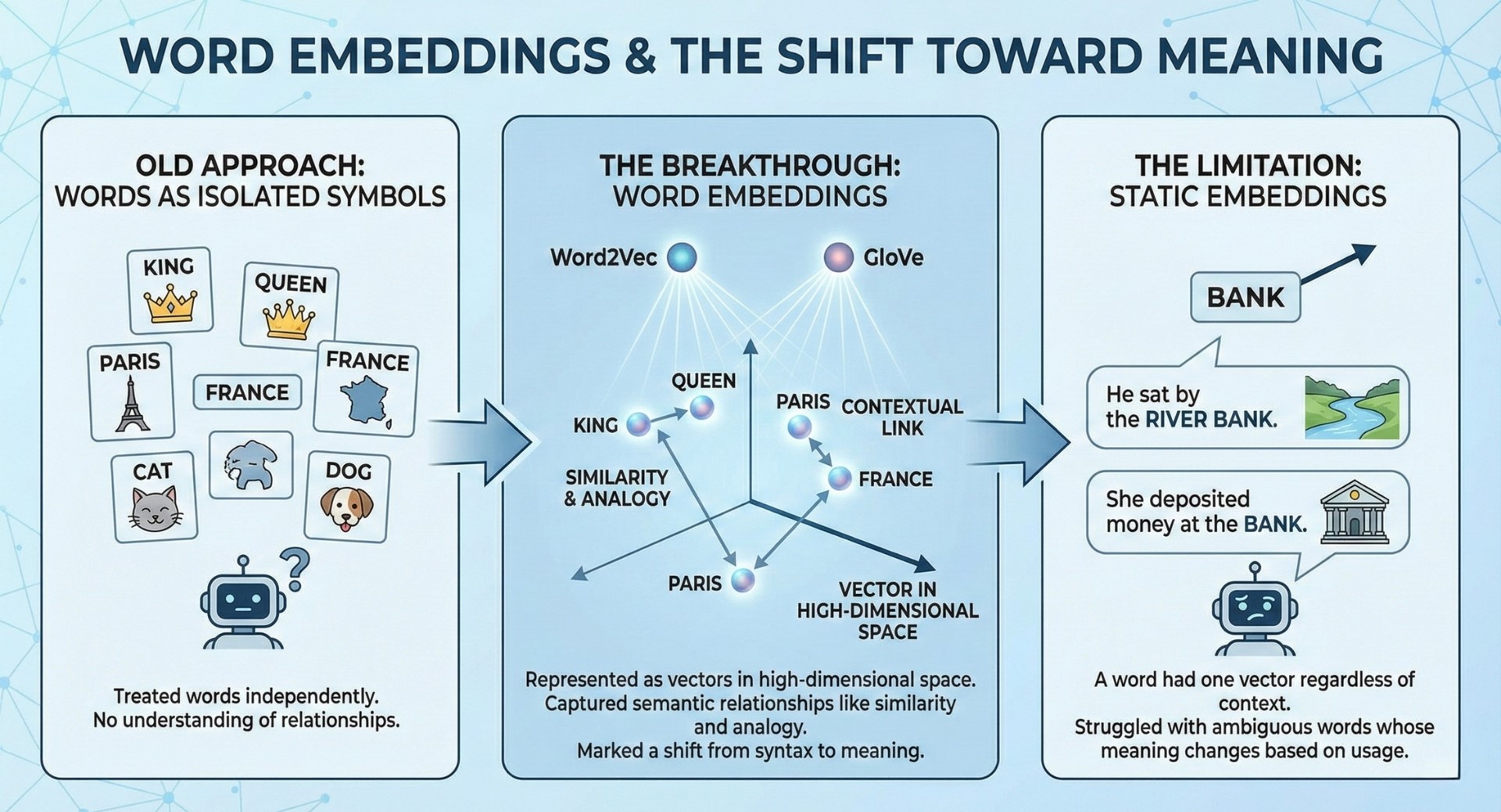
A major breakthrough came with word embeddings, which allowed words to be represented as vectors in high-dimensional space. Techniques such as Word2Vec and GloVe enabled models to capture semantic relationships like similarity and analogy.
Instead of treating words as isolated symbols, embeddings allowed machines to learn that “king” and “queen” are related, or that “Paris” and “France” share a contextual link. This marked a shift from syntax-focused NLP to meaning-aware representations.
However, early embeddings were static. A word had one vector regardless of context. This limitation became clear with ambiguous words whose meaning changes based on usage.
4. From contextual NLP to Transformers
Contextual models addressed the limitations of static embeddings by generating word representations based on surrounding text. This approach allowed machines to interpret meaning dynamically within sentences and paragraphs.
The Transformer architecture, introduced in 2017, became the defining moment in this transition. Transformers replaced sequential processing with attention mechanisms, allowing models to understand long-range dependencies efficiently. This architecture scaled exceptionally well with data and compute.
Transformers laid the foundation for large language models by enabling deep contextual understanding at scale, something earlier NLP architectures could not achieve. A constantly updated Whatsapp channel awaits your participation.
5. What are Large Language Models (LLMs)
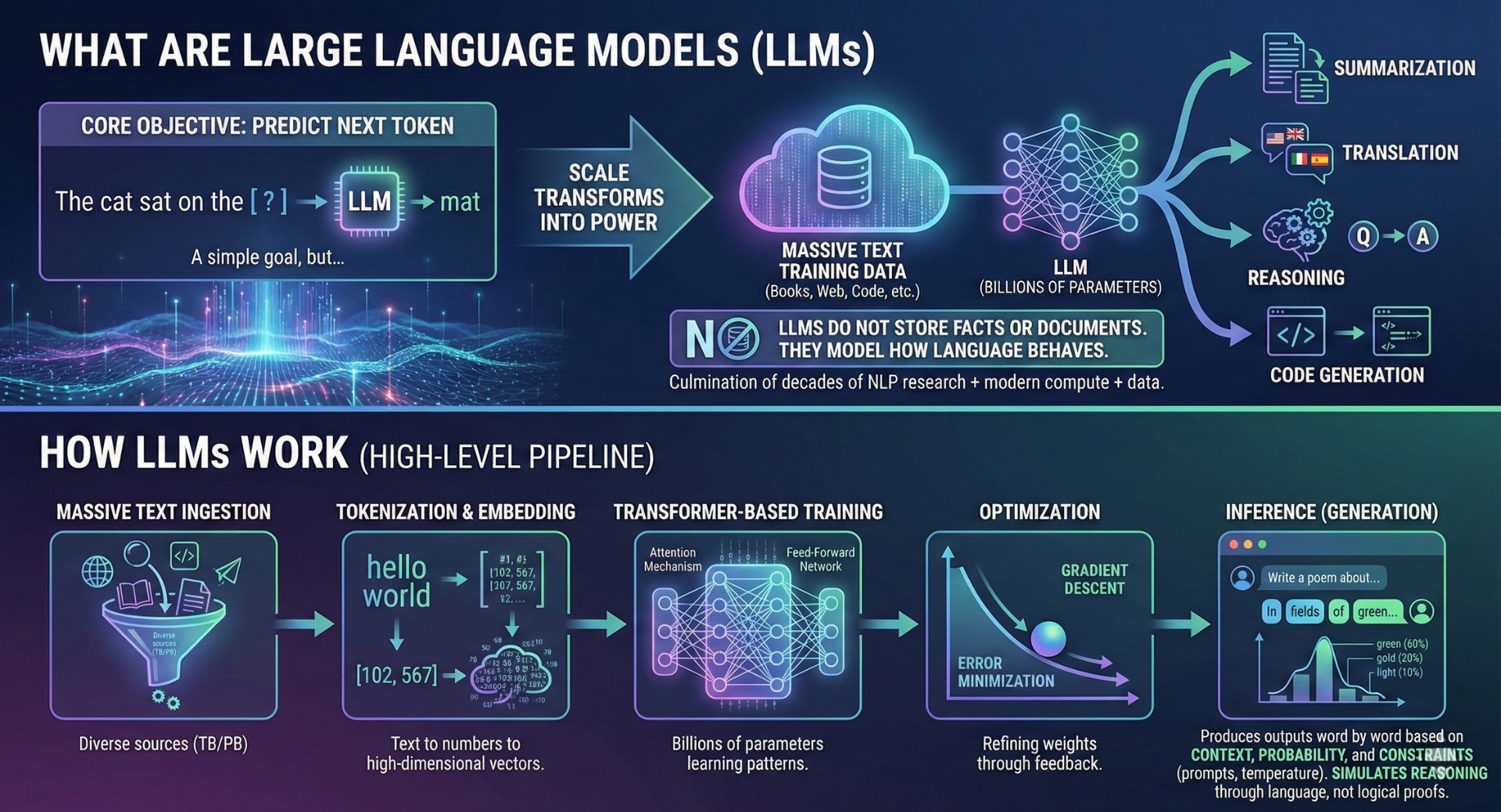
Large Language Models, or LLMs, are NLP systems trained on massive amounts of text to predict the next token in a sequence. While the objective sounds simple, scale transforms it into a powerful capability.
By learning statistical patterns across languages, domains, and writing styles, LLMs develop emergent abilities such as summarization, translation, reasoning, and code generation. Importantly, LLMs do not store facts or documents. They model how language behaves.
LLMs represent the culmination of decades of NLP research combined with modern compute, data, and architecture advances.
6. How LLMs work at a high level
Although implementations vary, most LLMs follow a common pipeline:
- Massive text ingestion from diverse sources
- Tokenization and embedding into numerical representations
- Transformer-based training with billions of parameters
- Optimization through gradient descent
- Inference through probabilistic token sampling
During generation, LLMs produce outputs word by word based on context, probability distributions, and constraints such as prompts or temperature settings. They simulate reasoning through language rather than executing logical proofs.
This explains both their power and their limitations. Excellent individualised mentoring programmes available.
7. Why LLMs feel intelligent
LLMs feel intelligent because they operate in the domain where humans perceive intelligence most strongly: language. They produce fluent sentences, maintain context across conversations, and generalize across topics.
However, this fluency can be misleading. LLMs do not understand language in the human sense. They do not possess beliefs, intent, or awareness. They predict plausible continuations, not truth.
This distinction is critical. LLMs are sophisticated pattern engines, not thinking entities. Treating them as authoritative sources rather than tools leads to misuse and overtrust.
8. Key NLP tasks transformed by LLMs
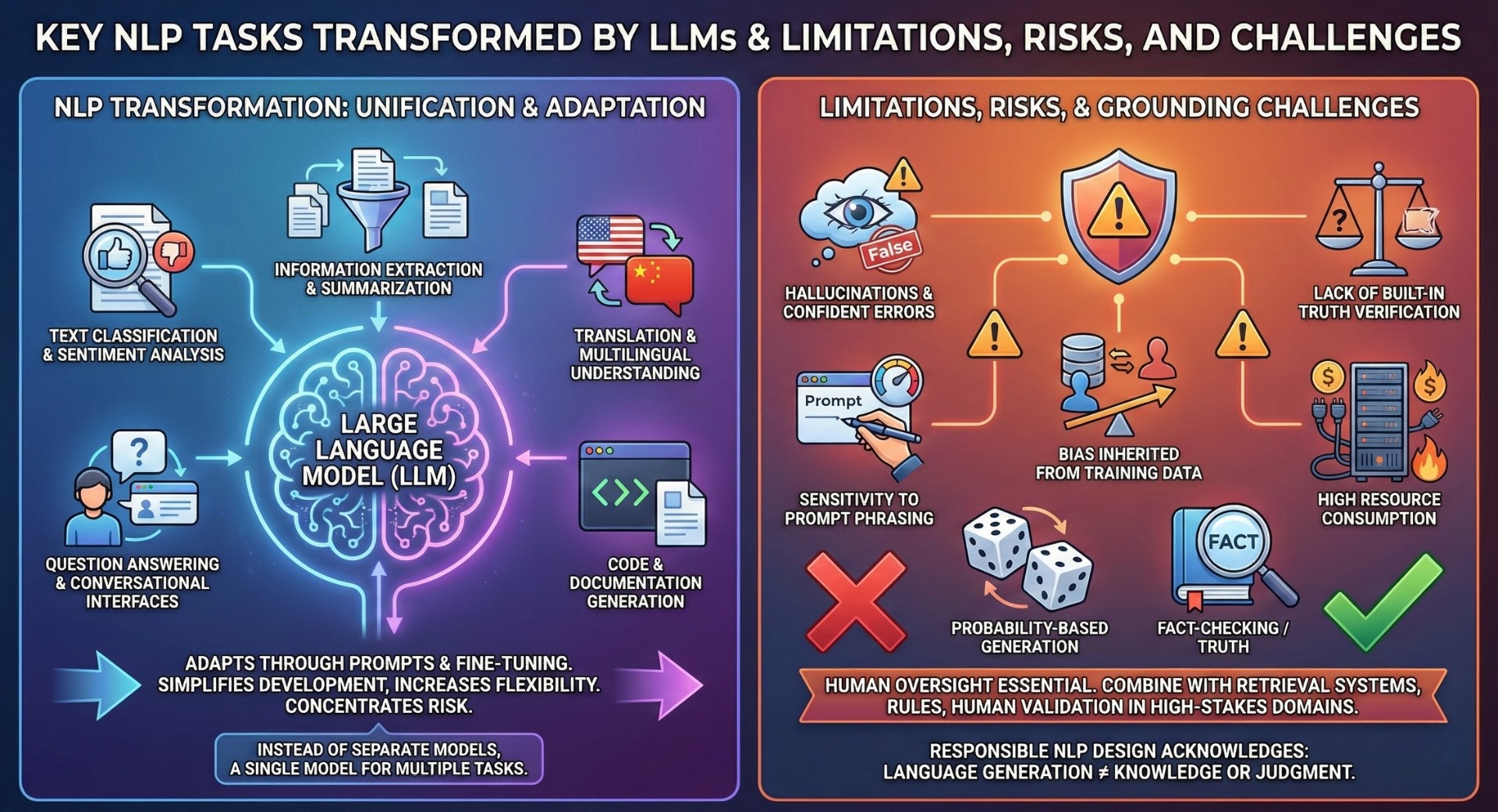
LLMs have unified many traditional NLP tasks into a single model:
- Text classification and sentiment analysis
- Information extraction and summarization
- Translation and multilingual understanding
- Question answering and conversational interfaces
- Code and documentation generation
Instead of training separate models for each task, LLMs adapt through prompts and fine-tuning. This shift simplifies development while increasing flexibility, but it also concentrates risk into fewer systems. Subscribe to our free AI newsletter now.
9. Limitations, risks, and grounding challenges
Despite their capabilities, LLMs have fundamental weaknesses:
- Hallucinations and confident errors
- Lack of built-in truth verification
- Sensitivity to prompt phrasing
- Bias inherited from training data
- High resource consumption
Because LLMs generate based on probability rather than fact-checking, human oversight remains essential. In high-stakes domains, LLMs must be combined with retrieval systems, rules, and human validation.
Responsible NLP design acknowledges that language generation is not the same as knowledge or judgment.
10. The future: From NLP models to language systems
The evolution from NLP to LLMs is still ongoing. The next phase involves integrating language models with tools, memory, reasoning frameworks, and real-world actions.
Future systems will move toward agentic language models, real-time multimodal understanding, and personalized assistants embedded into workflows. Language will become an interface to systems, not just information.
The goal is not to replace human thinking, but to augment it. As NLP evolves into language-driven intelligence, the real skill will be learning how to think with machines, not surrender thinking to them. Upgrade your AI-readiness with our masterclass.
Summary
The journey from NLP to LLMs is a story of increasing scale, abstraction, and capability. What began as rule-based text processing has evolved into powerful language systems that can assist, explain, and generate across domains. Yet these systems remain tools, not minds. Understanding their strengths, limits, and design principles is essential for anyone working with modern AI. Language models can generate words. Humans must still provide meaning, judgment, and responsibility.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



