On-Device AI & Hardware-Aware Optimization Compilation techniques

On-Device AI & Hardware-Aware Optimization Compilation techniques
TVMXLA, 4-bitNF4 quantization, and designing models specifically for NPU (Neural Processing Unit) architectures
Introduction
Artificial Intelligence is rapidly moving from large cloud data centers to devices at the edge –smartphones, laptops, wearables, drones, autonomous vehicles, and IoT devices. This shift toward on-device AI is driven by several practical needs: lower latency, better privacy, reduced bandwidth costs, and the ability to operate even without continuous internet connectivity.
However, deploying powerful AI models directly on devices introduces new challenges. Traditional deep learning models are often large, memory-intensive, and computationally expensive, making them unsuitable for edge hardware. A modern large language model or vision model may require gigabytes of memory and powerful GPUs – resources that mobile devices typically lack.
To solve this challenge, the AI ecosystem has evolved techniques that make models smaller, faster, and hardware-efficient. Three key developments are transforming on-device AI deployment:
- Hardware-aware compilation frameworks such as TVM and XLA, which optimize models for specific hardware architectures.
- Advanced quantization techniques like 4-bit NF4 quantization, which drastically reduce model size while preserving accuracy.
- Model architectures designed specifically for NPUs (Neural Processing Units), the specialized AI accelerators now embedded in modern devices.
Together, these innovations allow sophisticated AI capabilities to run efficiently on devices ranging from smartphones to edge servers.
Key concepts and developments
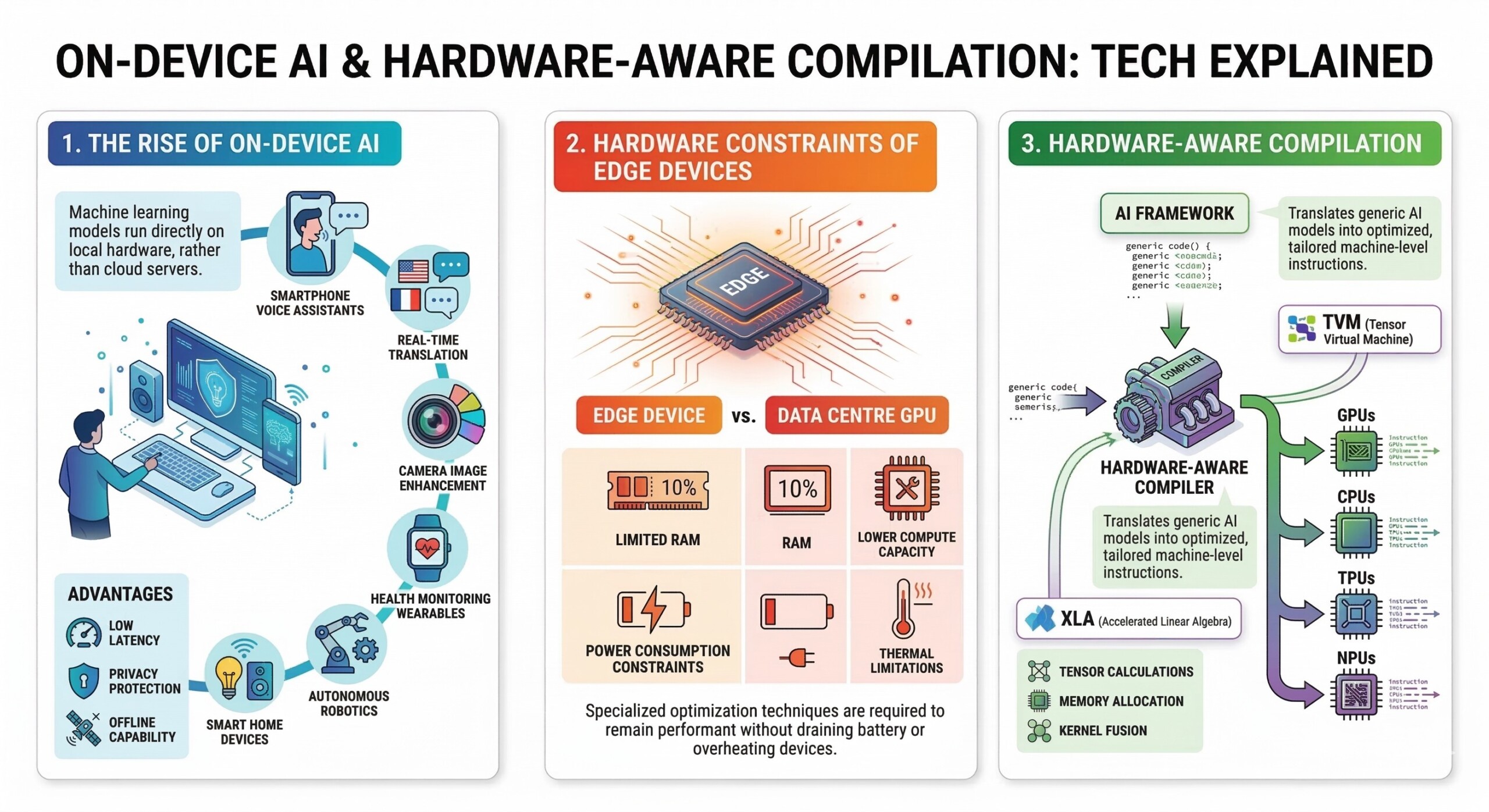
1. The rise of On-Device AI
On-device AI refers to running machine learning models directly on local hardware rather than relying entirely on cloud servers. Applications include:
- Smartphone voice assistants
- Real-time translation
- Camera image enhancement
- Health monitoring wearables
- Autonomous robotics
- Smart home devices
The biggest advantages include low latency, privacy protection, and offline capability.
2. Hardware constraints of edge devices
Edge devices have strict limitations compared to data centre GPUs:
- Limited RAM
- Lower compute capacity
- Power consumption constraints
- Thermal limitations
These constraints require specialized optimization techniques so that models remain performant without draining battery or overheating devices. An excellent collection of learning videos awaits you on our Youtube channel.
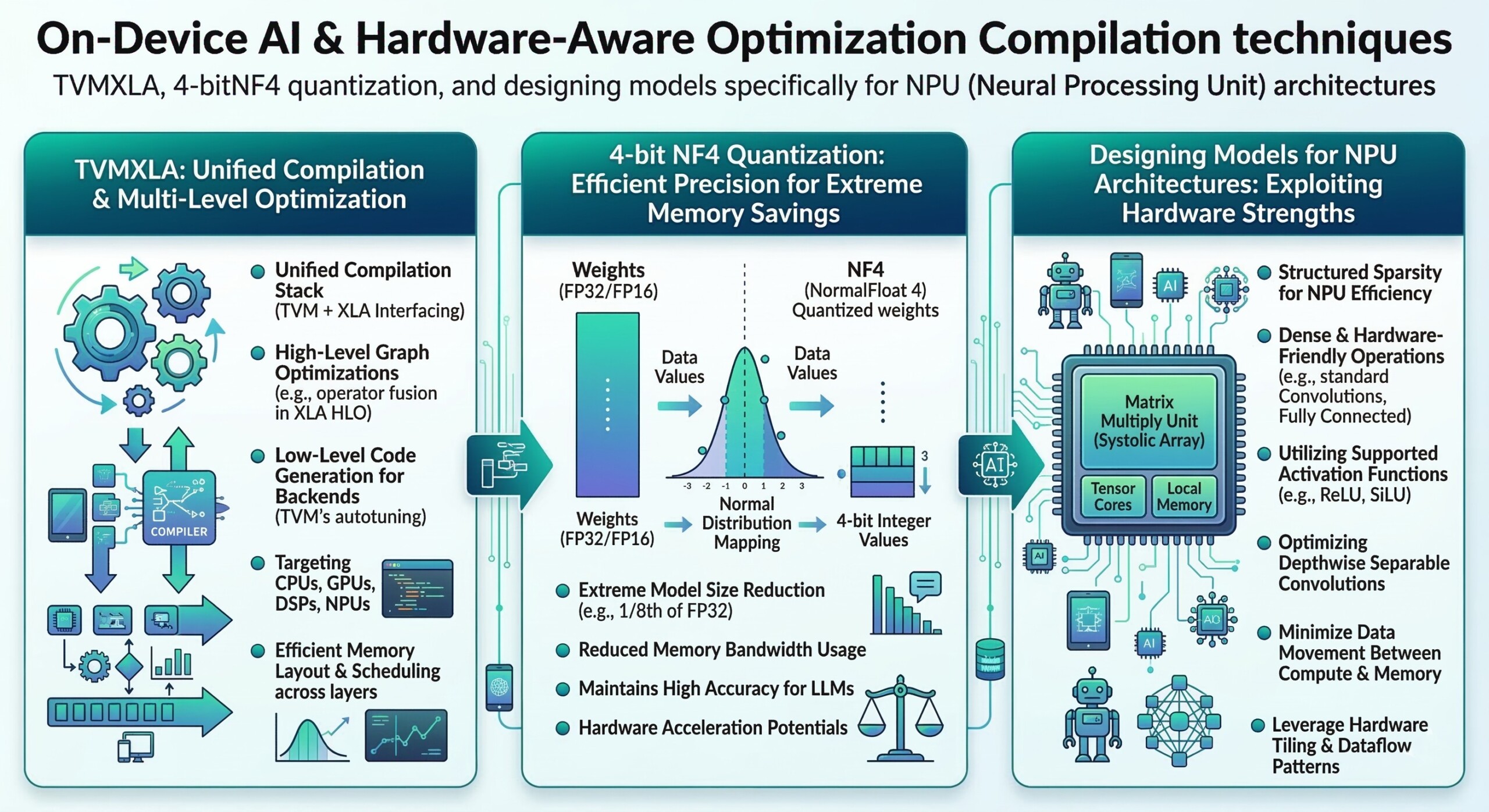
3. Hardware-aware compilation
Modern AI frameworks often produce generic computation graphs. However, different hardware platforms – GPUs, CPUs, TPUs, and NPUs – require different execution strategies.
Hardware-aware compilers translate AI models into optimized machine-level instructions tailored for specific hardware architectures.
Two important systems are:
TVM (Tensor Virtual Machine)
XLA (Accelerated Linear Algebra)
These compilers optimize operations such as tensor calculations, memory allocation, and kernel fusion.
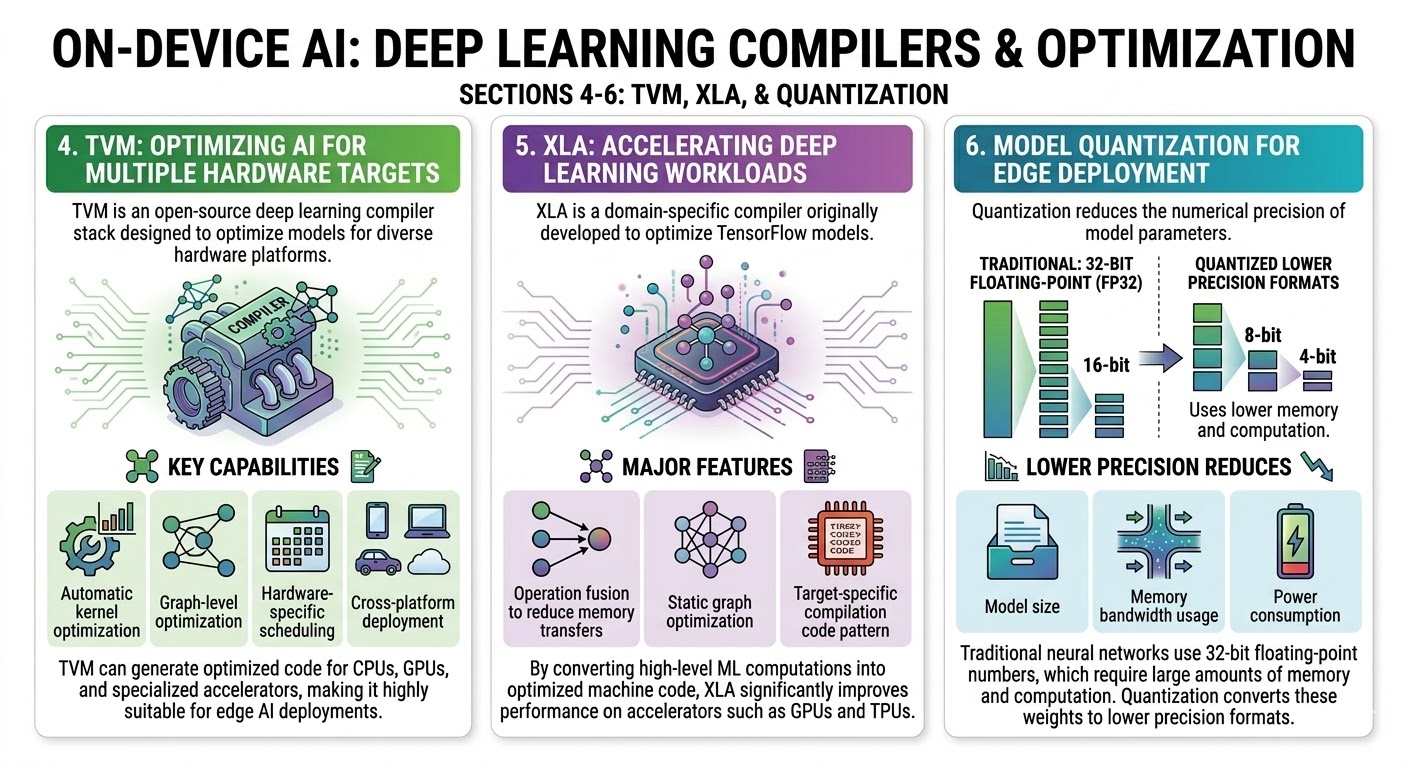
4. TVM: Optimizing AI for multiple hardware targets
TVM is an open-source deep learning compiler stack designed to optimize models for diverse hardware platforms.
Key capabilities include:
- Automatic kernel optimization
- Graph-level optimization
- Hardware-specific scheduling
- Cross-platform deployment
TVM can generate optimized code for CPUs, GPUs, and specialized accelerators, making it highly suitable for edge AI deployments. A constantly updated Whatsapp channel awaits your participation.
5. XLA: Accelerating deep learning workloads
XLA is a domain-specific compiler originally developed to optimize TensorFlow models.
Its major features include:
- Operation fusion to reduce memory transfers
- Static graph optimization
- Target-specific compilation
By converting high-level ML computations into optimized machine code, XLA significantly improves performance on accelerators such as GPUs and TPUs.
6. Model Quantization for edge deployment
Quantization reduces the numerical precision of model parameters.
Traditional neural networks use 32-bit floating-point numbers, which require large amounts of memory and computation.
Quantization converts these weights to lower precision formats such as:
- 16-bit
- 8-bit
- 4-bit
Lower precision reduces:
- Model size
- Memory bandwidth usage
- Power consumption
Excellent individualised mentoring programmes available.
7. 4-bit NF4 Quantization
One of the most advanced techniques for efficient models is 4-bit NormalFloat (NF4) quantization.
NF4 is specifically designed for neural network weight distributions.
Key characteristics include:
- Uses only 4 bits per weight
- Maintains high accuracy compared to standard quantization
- Works well with transformer architectures
- Reduces memory requirements dramatically
For example, a model that normally requires 16 GB memory may run within 4–6 GB after NF4 quantization.
This technique has become essential for running large language models on consumer hardware.
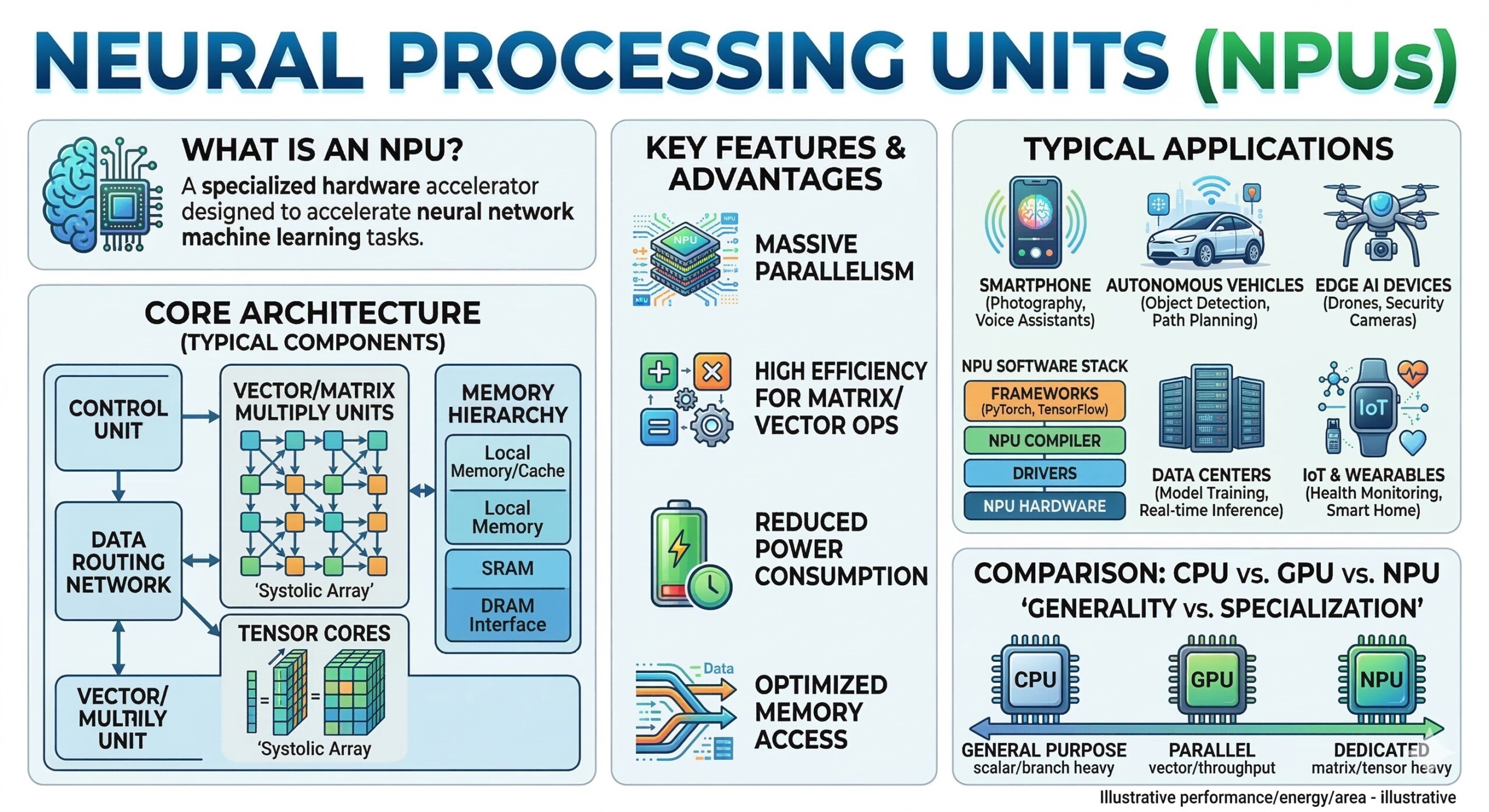
8. Neural Processing Units (NPUs)
Neural Processing Units (NPUs) are specialized hardware accelerators designed specifically to execute artificial intelligence workloads efficiently. As AI applications increasingly move to edge devices—such as smartphones, smart cameras, and autonomous vehicles – general-purpose processors like CPUs and even GPUs are often not the most efficient option. NPUs are built from the ground up to handle the mathematical operations used in neural networks, allowing devices to perform AI inference quickly while consuming much less power.
Modern AI workloads involve large numbers of matrix multiplications, tensor operations, and parallel computations, which form the core of deep learning algorithms. NPUs are designed to execute these operations with massive parallelism, optimized memory access, and specialized instruction sets. As a result, they can process neural networks much faster and with significantly lower energy consumption than traditional processors.
Many modern devices now include NPUs as dedicated AI engines. These are found in a wide range of consumer and industrial hardware, including:
- Smartphones – Modern mobile processors include NPUs to power features like real-time image enhancement, speech recognition, and AI assistants.
• Edge computing devices – Edge servers and embedded systems use NPUs to perform local inference for applications such as industrial monitoring and smart retail.
• Automotive AI systems – Autonomous driving systems rely on NPUs to process sensor data, perform object detection, and make real-time driving decisions.
• Smart cameras and IoT devices – Surveillance cameras and smart home devices use NPUs for tasks like face recognition, motion detection, and anomaly detection.
One of the major advantages of NPUs is their energy efficiency. AI tasks executed on CPUs often consume large amounts of power and generate heat. GPUs improve parallel performance but can still be power-hungry. NPUs, on the other hand, are optimized for low-power AI inference, making them ideal for battery-powered devices such as smartphones and wearable electronics.
In practice, NPUs act as the AI engine of modern devices, allowing complex neural network models to run directly on hardware without sending data to cloud servers. This enables applications such as:
- Real-time translation on smartphones
- Voice assistants that work offline
- Instant photo and video enhancement
- Smart security cameras that detect people or objects
- Driver assistance systems in vehicles
Subscribe to our free AI newsletter now.
9. Designing models for NPU architectures
Instead of adapting large cloud models to edge devices, researchers increasingly design NPU-friendly models from the start.
These models emphasize:
- Efficient tensor operations
- Reduced memory movement
- Parallel computation
- Low precision arithmetic
Examples of NPU-optimized architectures include lightweight models such as:
- MobileNet
- EfficientNet
- TinyML architectures
10. The Future: Co-design of models and hardware
The most promising direction for on-device AI is hardware–software co-design.
Instead of treating hardware and AI models separately, engineers design them together so that:
- AI models exploit hardware strengths
- Hardware accelerates common AI operations
- Compilation frameworks automatically optimize execution
This integrated approach is enabling increasingly powerful AI capabilities on small devices. Upgrade your AI-readiness with our masterclass.
Conclusion
The movement toward on-device AI represents a major shift in the artificial intelligence landscape. As AI becomes embedded in everyday devices – from smartphones to smart homes – efficiency and hardware compatibility become critical.
Techniques such as hardware-aware compilation frameworks like TVM and XLA, advanced quantization methods such as 4-bit NF4, and models designed specifically for NPU architectures are making this transformation possible. These innovations allow sophisticated AI systems to run with limited memory, lower power consumption, and minimal latency.
In the coming years, the integration of model architecture design, compiler optimization, and specialized AI hardware will continue to advance. This convergence will enable powerful AI capabilities directly on edge devices, reducing dependence on cloud infrastructure while improving speed, privacy, and accessibility.
On-device AI is therefore not merely an optimization trend – it represents a fundamental evolution toward ubiquitous, efficient, and locally intelligent computing systems.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



