State Space Models (SSMs) & Alternatives to Transformers: Deep diving into the math behind Mamba and S4 architectures

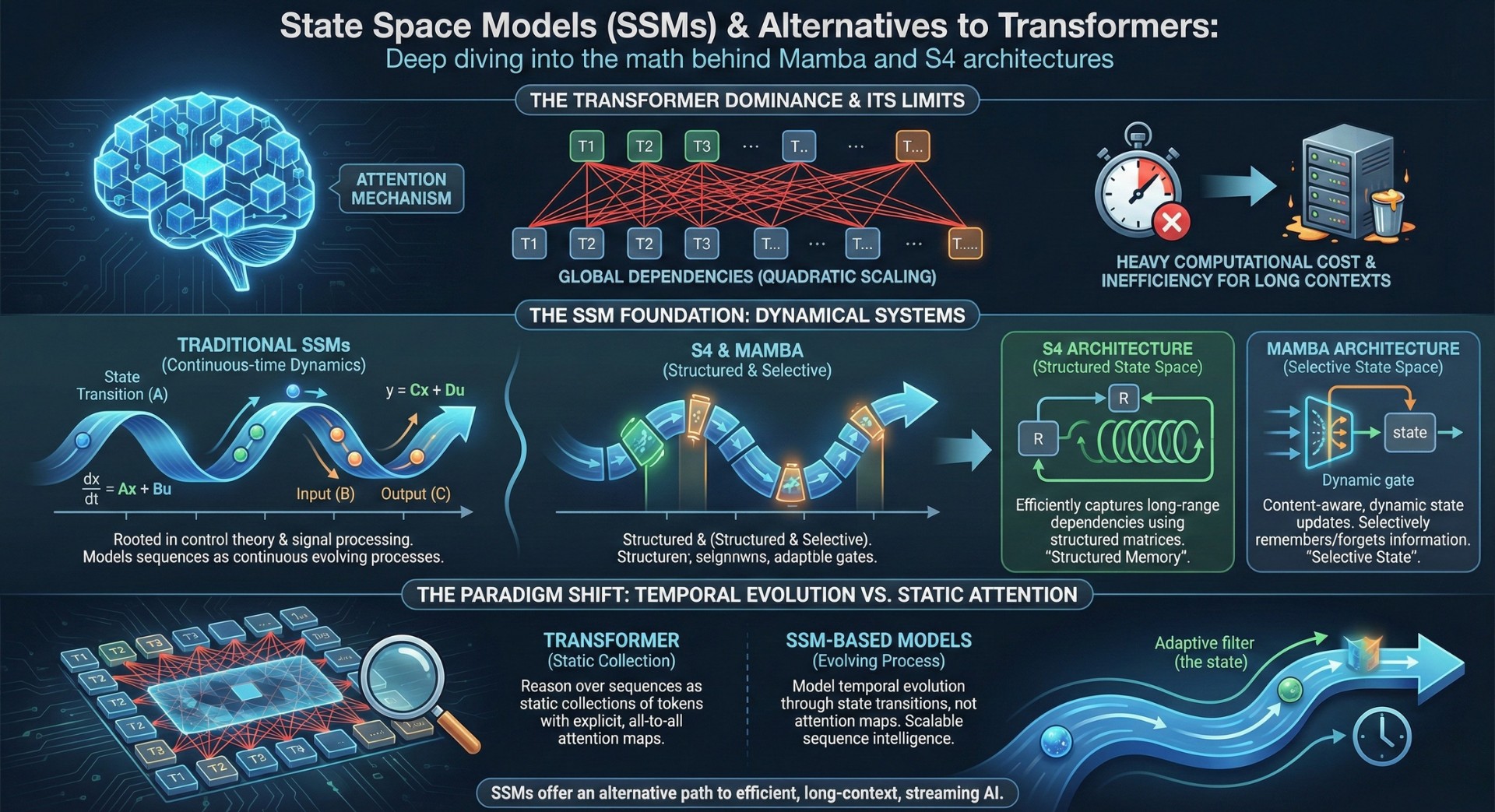
Modern deep learning models for language, vision, and time-series have been dominated by Transformers. Attention mechanisms enabled models to capture global dependencies across sequences, but this power came with heavy computational costs, quadratic scaling, and inefficiencies for long contexts and streaming data.
State Space Models (SSMs) offer a fundamentally different mathematical foundation for sequence modeling, rooted in dynamical systems theory rather than pairwise attention. Architectures like S4 and Mamba extend SSMs into practical, trainable deep learning systems, creating a new class of AI models that process sequences through continuous-time dynamics and structured memory rather than explicit token-to-token attention.
This shift introduces AI systems that model temporal evolution and long-range dependency through state transitions, not attention maps. SSM-based models reason over sequences as evolving processes rather than static collections of tokens, offering an alternative path to scalable sequence intelligence.
1. Why sequence length breaks Transformers
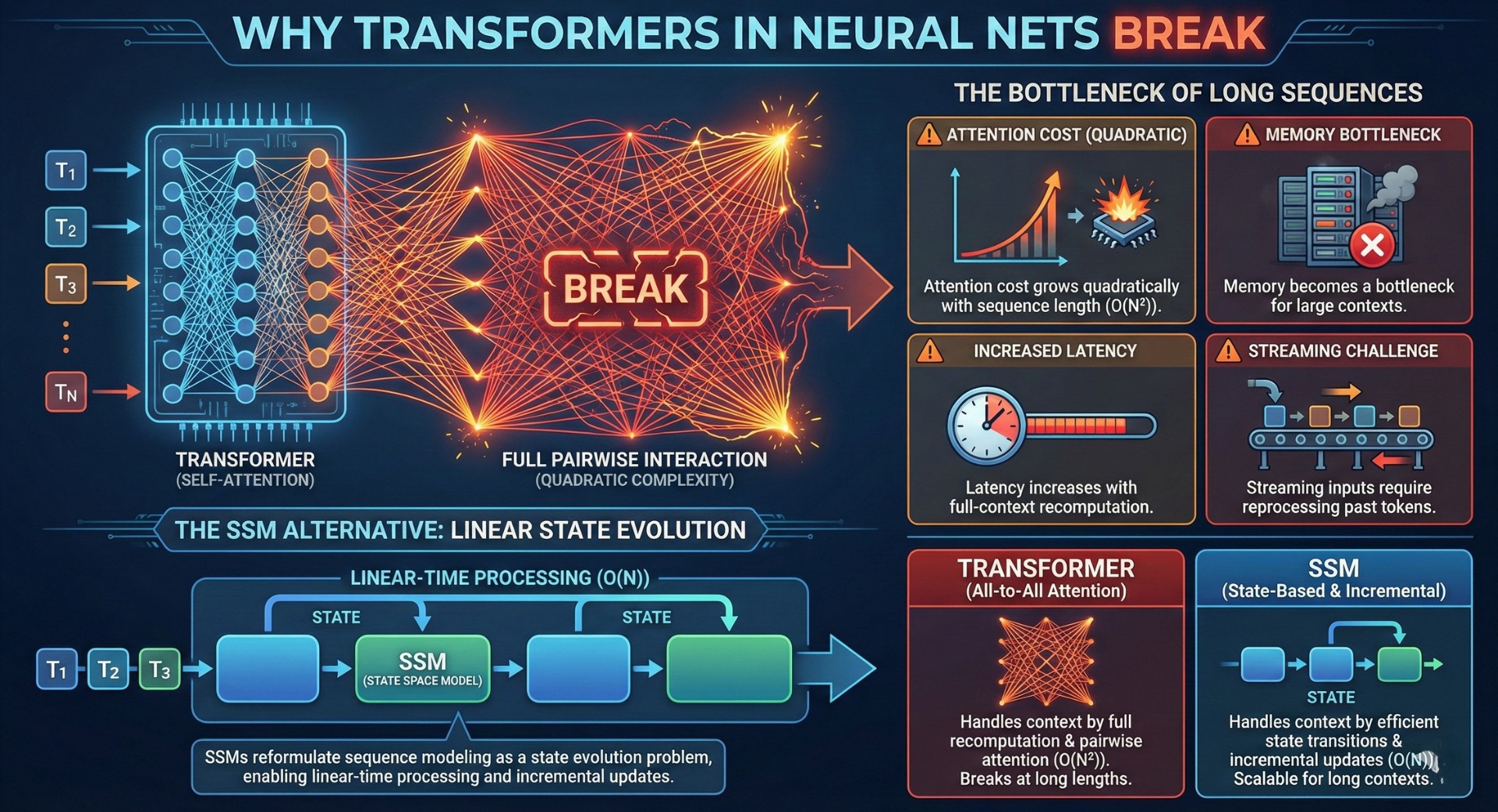
Transformers assume full pairwise interaction between tokens through self-attention. While powerful, this assumption leads to quadratic time and memory complexity, making long sequences computationally expensive and limiting real-time or streaming applications.
In long-context settings:
- Attention cost grows quadratically with sequence length
- Memory becomes a bottleneck for large contexts
- Latency increases with full-context recomputation
- Streaming inputs require reprocessing past tokens
SSMs reformulate sequence modeling as a state evolution problem, enabling linear-time processing and incremental updates. This changes how models handle memory, context, and temporal dependency.
2. From attention-based modeling to dynamical systems
Transformers view sequences as collections of interacting tokens. State Space Models treat sequences as signals evolving over time under learned dynamics.
SSM-based modeling introduces:
- Continuous-time latent state dynamics
- Linear or structured state transition operators
- Input-driven state updates
- Output projections from hidden state
- Convolutional interpretations of sequence memory
This transition marks a shift from explicit token interactions to implicit memory carried through learned dynamical systems. An excellent collection of learning videos awaits you on our Youtube channel.
3. Core building blocks of State Space Models in deep learning
Modern SSM architectures generalize classical control-theoretic models into trainable neural components:
- Hidden state representing compressed memory of the past
- State transition matrix encoding temporal dynamics
- Input projection mapping tokens into state space
- Output projection generating predictions
- Discretization methods for continuous-time dynamics
These components allow information to propagate through time efficiently, enabling long-range dependency modeling without explicit attention.
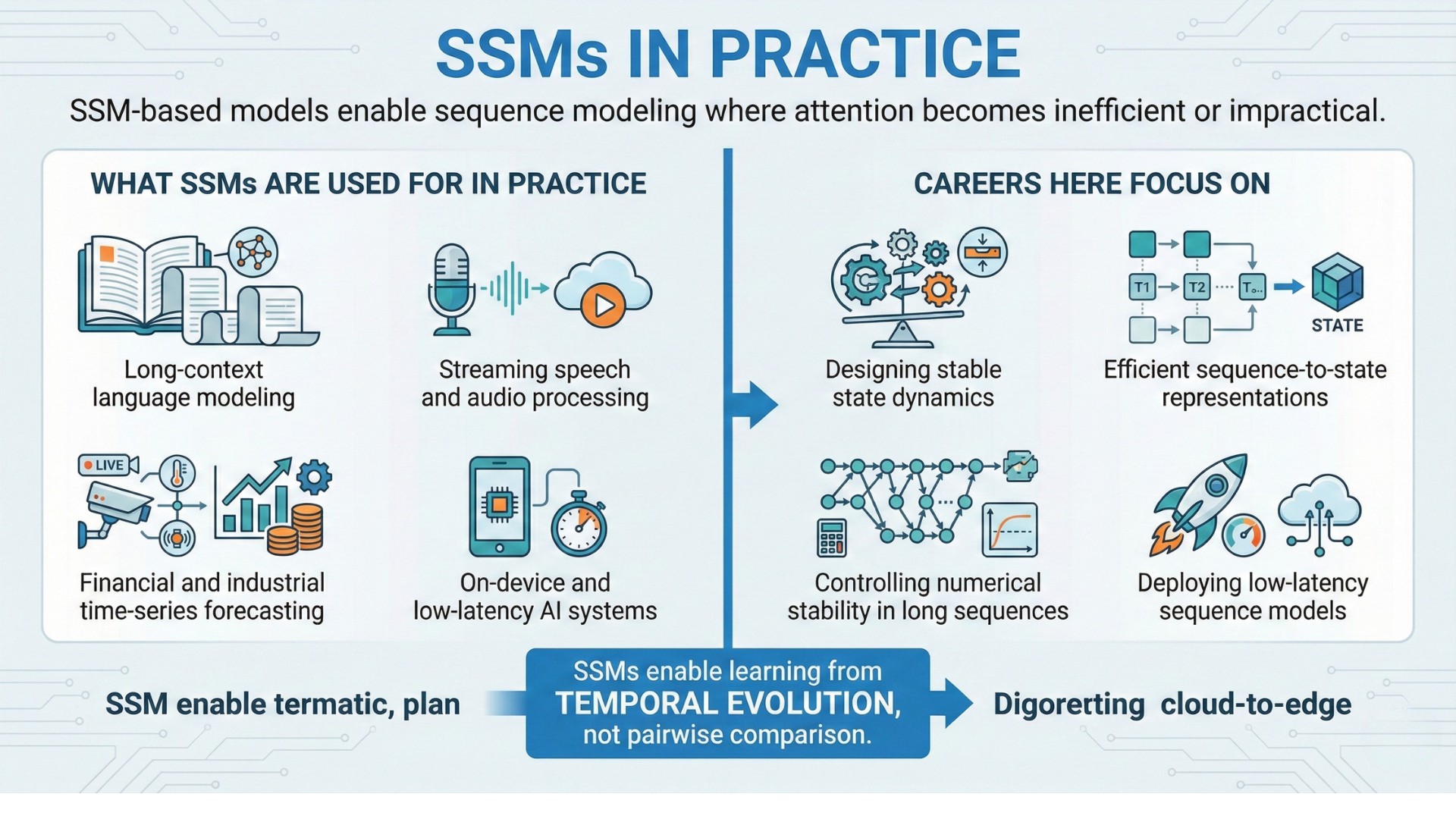
4. What SSMs are used for in practice
SSM-based models enable sequence modeling where attention becomes inefficient or impractical.
Examples include:
- Long-context language modeling
- Streaming speech and audio processing
- Real-time video and sensor data
- Financial and industrial time-series forecasting
- On-device and low-latency AI systems
Careers here focus on:
- Designing stable state dynamics
- Efficient sequence-to-state representations
- Controlling numerical stability in long sequences
- Deploying low-latency sequence models
SSMs enable learning from temporal evolution, not pairwise comparison. A constantly updated Whatsapp channel awaits your participation.
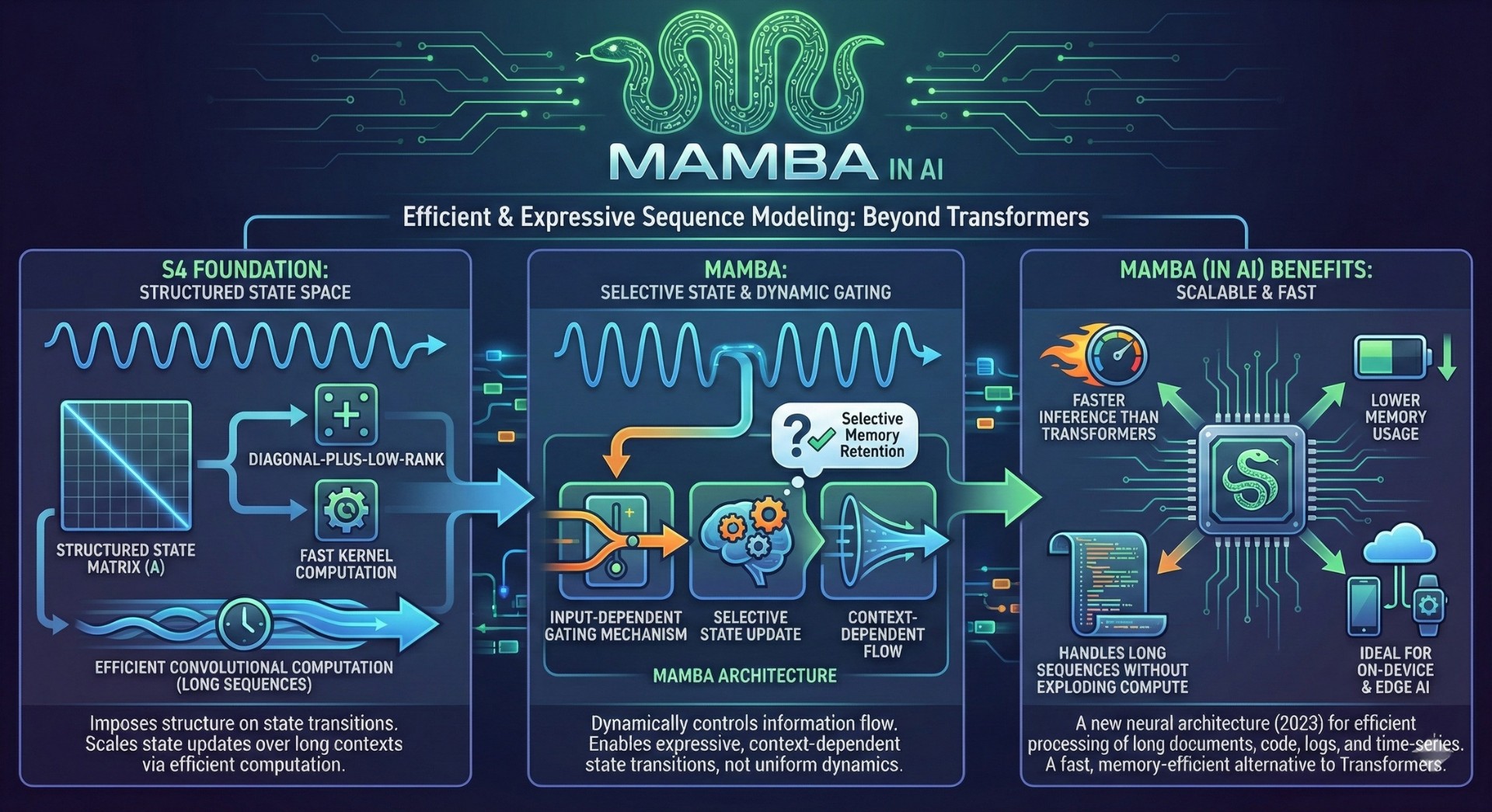
5. The mathematics behind S4 and Mamba
S4 (Structured State Space for Sequence Modeling) makes SSMs practical by imposing structure on the state transition matrix, allowing efficient convolutional computation over long sequences. It leverages diagonal-plus-low-rank parameterizations and fast kernel computation to scale state updates over long contexts.
Mamba introduces selective state updates and input-dependent gating mechanisms, allowing the model to dynamically control how information flows through the state. This makes SSMs more expressive for language modeling, enabling selective memory retention and context-dependent state transitions rather than uniform temporal dynamics.
Together, these architectures translate control theory into scalable neural sequence models.
(In AI, Mamba is a new neural network architecture (2023) designed to process long sequences much more efficiently than Transformers, especially for long documents, code, logs, and time-series. Mamba is a fast, memory-efficient alternative to Transformers for long-context AI tasks. It handles very long sequences without exploding compute, has faster inference than Transformers, has lower memory usage and promises great results for on-device and edge AI)
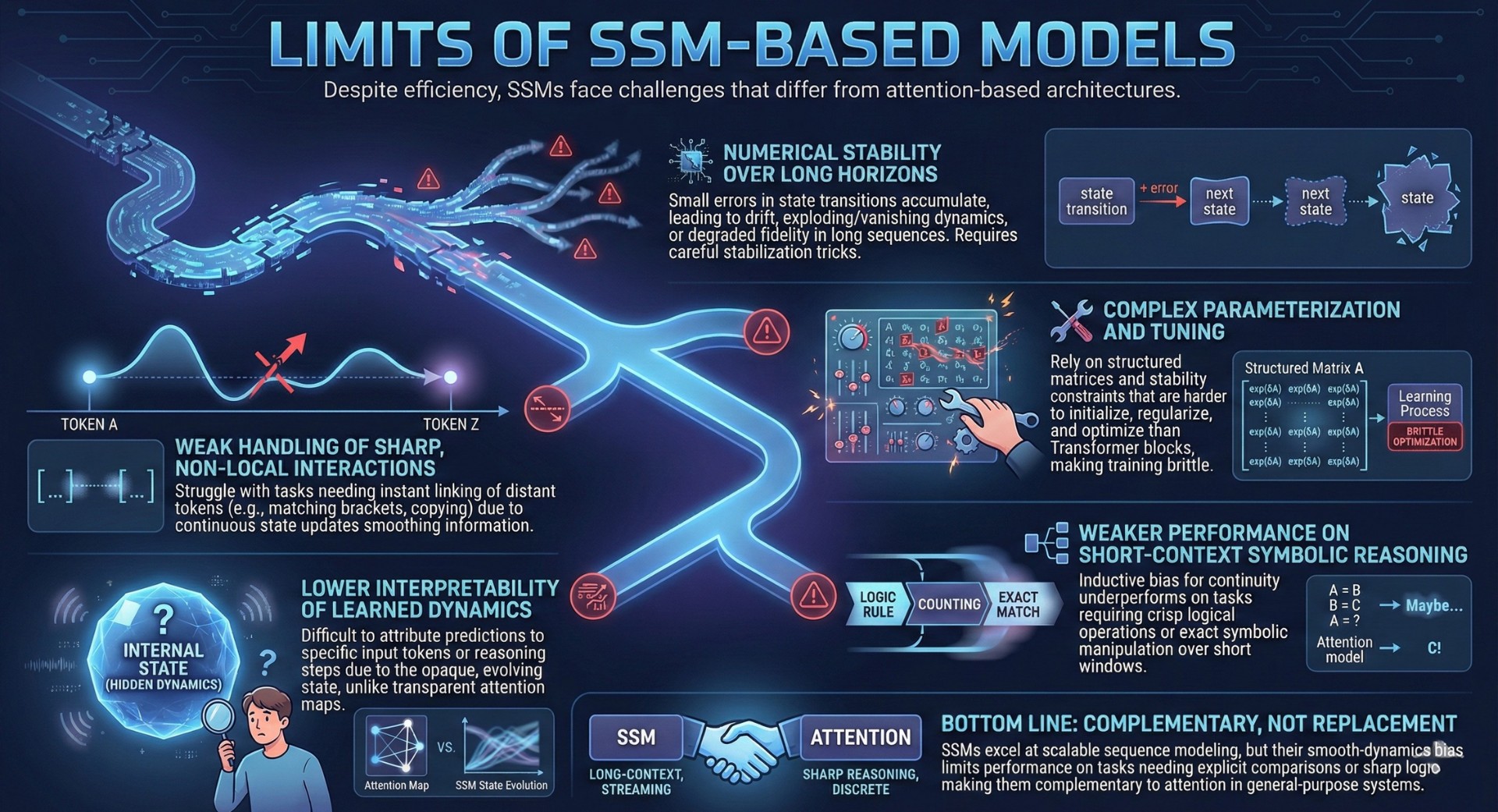
6. Limitations and challenges of SSM-based model
Despite their efficiency, State Space Models (SSMs) introduce a distinct set of constraints and training challenges that differ from attention-based architectures. Their core design favours smooth, continuous temporal dynamics, which is powerful for long sequences but can become a liability in tasks that demand discrete jumps in attention, sharp relational reasoning, or precise token-to-token comparisons.
Key limitations of SSMs include:
- Numerical stability over long horizons – Small errors in state transitions can accumulate across long sequences, leading to drift, exploding/vanishing dynamics, or degraded long-range fidelity unless carefully stabilized through parameterization and normalization tricks.
- Weak handling of sharp, non-local interactions – Because information flows through continuous state updates, SSMs struggle with tasks that require instant linking between distant tokens (e.g., matching brackets, copying patterns, or cross-document references) without intermediary smoothing.
- Complex parameterization and tuning – SSMs rely on structured matrices, discretization schemes, and stability constraints that are harder to initialize, regularize, and optimize than standard Transformer blocks, making training more brittle and architecture-sensitive.
- Lower interpretability of learned dynamics – The internal state evolves through learned linear and nonlinear operators, making it difficult to attribute specific predictions to concrete input tokens or human-readable reasoning steps, unlike attention maps which offer partial transparency.
- Weaker performance on short-context symbolic reasoning – On tasks that rely on crisp logical rules, counting, exact matching, or symbolic manipulation over short windows, SSMs often underperform attention-based models because their inductuctive bias favors continuity over discrete relational operations.
Bottom line: While SSMs scale linearly and excel at long-context, streaming, and memory-efficient sequence modeling, their smooth-dynamics inductive bias can underperform when tasks require explicit pairwise comparison, abrupt context switching, or sharp logical operations. This makes them complementary to, rather than replacements for, attention-based architectures in general-purpose reasoning systems. Excellent individualised mentoring programmes available.
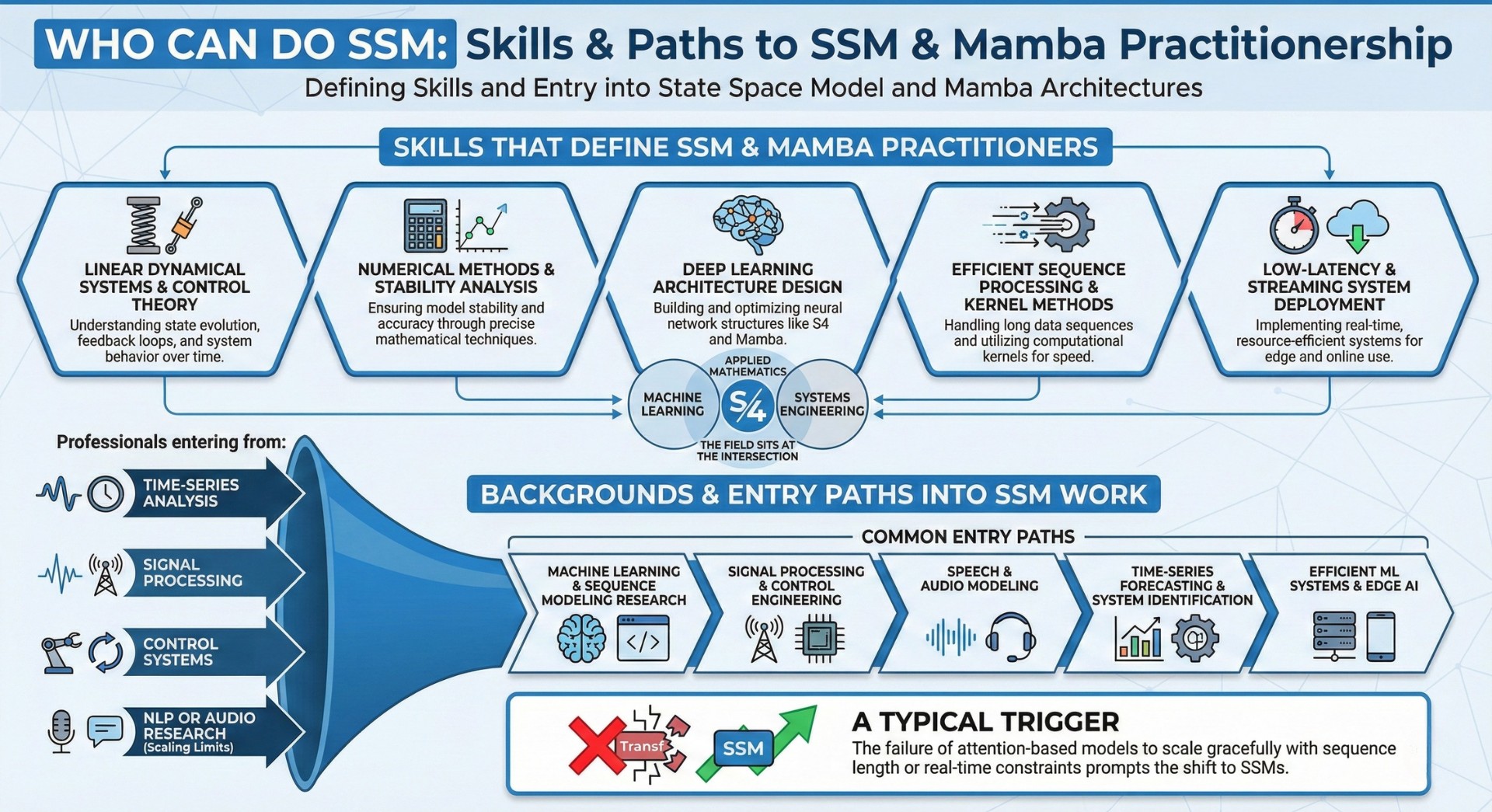
7. Skills that define SSM and Mamba practitioners
Practitioners working with SSM-based architectures require cross-domain expertise:
- Linear dynamical systems and control theory
- Numerical methods and stability analysis
- Deep learning architecture design
- Efficient sequence processing and kernel methods
- Low-latency and streaming system deployment
The field sits at the intersection of machine learning, applied mathematics, and systems engineering.
8. Backgrounds and entry paths into SSM work
Professionals entering SSM-based modeling often come from time-series analysis, signal processing, or control systems, where dynamical systems are core tools. Many arrive from NLP or audio research after encountering the scaling limits of Transformers on long sequences.
Common entry paths include:
- Machine learning and sequence modeling research
- Signal processing and control engineering
- Speech and audio modeling
- Time-series forecasting and system identification
- Efficient ML systems and edge AI
A typical trigger is the failure of attention-based models to scale gracefully with sequence length or real-time constraints. Subscribe to our free AI newsletter now.
9. Tensions and trade-offs in SSM-based sequence modelling
SSM-based systems involve persistent design trade-offs:
- Expressivity versus efficiency
• Stability versus flexibility of dynamics
• Long-range memory versus sharp token interactions
• Interpretability versus performance
• Streaming efficiency versus global context access
These trade-offs shape where SSMs outperform Transformers and where hybrid architectures become necessary.
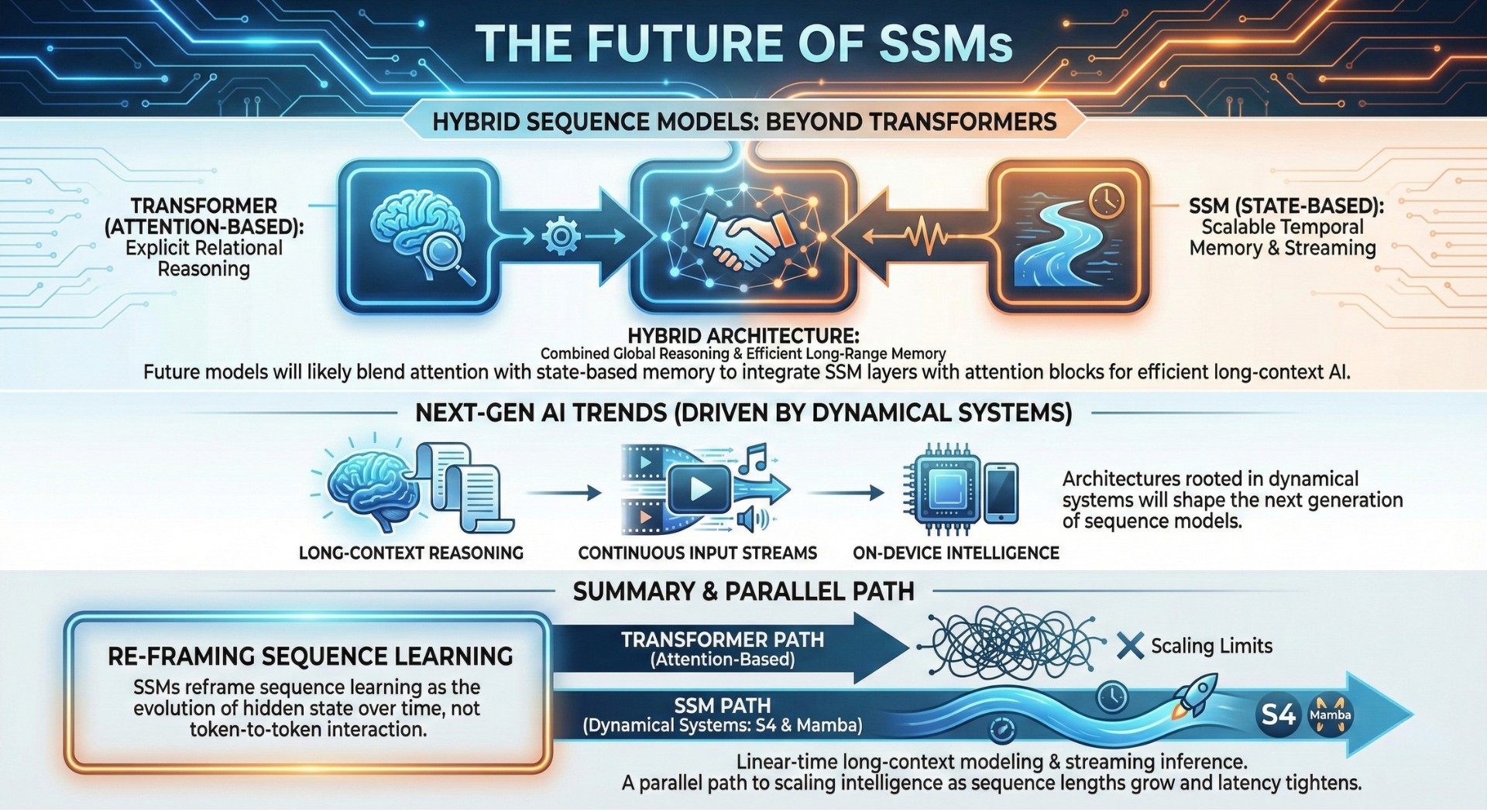
10. The future: Hybrid sequence models beyond Transformers
The future of sequence modeling will likely blend attention with state-based memory. Transformers excel at explicit relational reasoning, while SSMs excel at scalable temporal memory and streaming computation. Hybrid architectures that integrate SSM layers with attention blocks aim to combine global reasoning with efficient long-range memory.
As AI systems expand into long-context reasoning, continuous input streams, and on-device intelligence, architectures rooted in dynamical systems will shape the next generation of sequence models beyond pure attention. Upgrade your AI-readiness with our masterclass.
Summary
State Space Models reframe sequence learning as the evolution of hidden state over time rather than token-to-token interaction. Architectures like S4 and Mamba bring dynamical systems theory into deep learning, enabling linear-time long-context modeling and streaming inference. As sequence lengths grow and latency constraints tighten, SSM-based models will define a parallel path to scaling intelligence beyond Transformers.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



