Tokenization Algorithms & their impact on Learning

Tokenization Algorithms & their impact on Learning
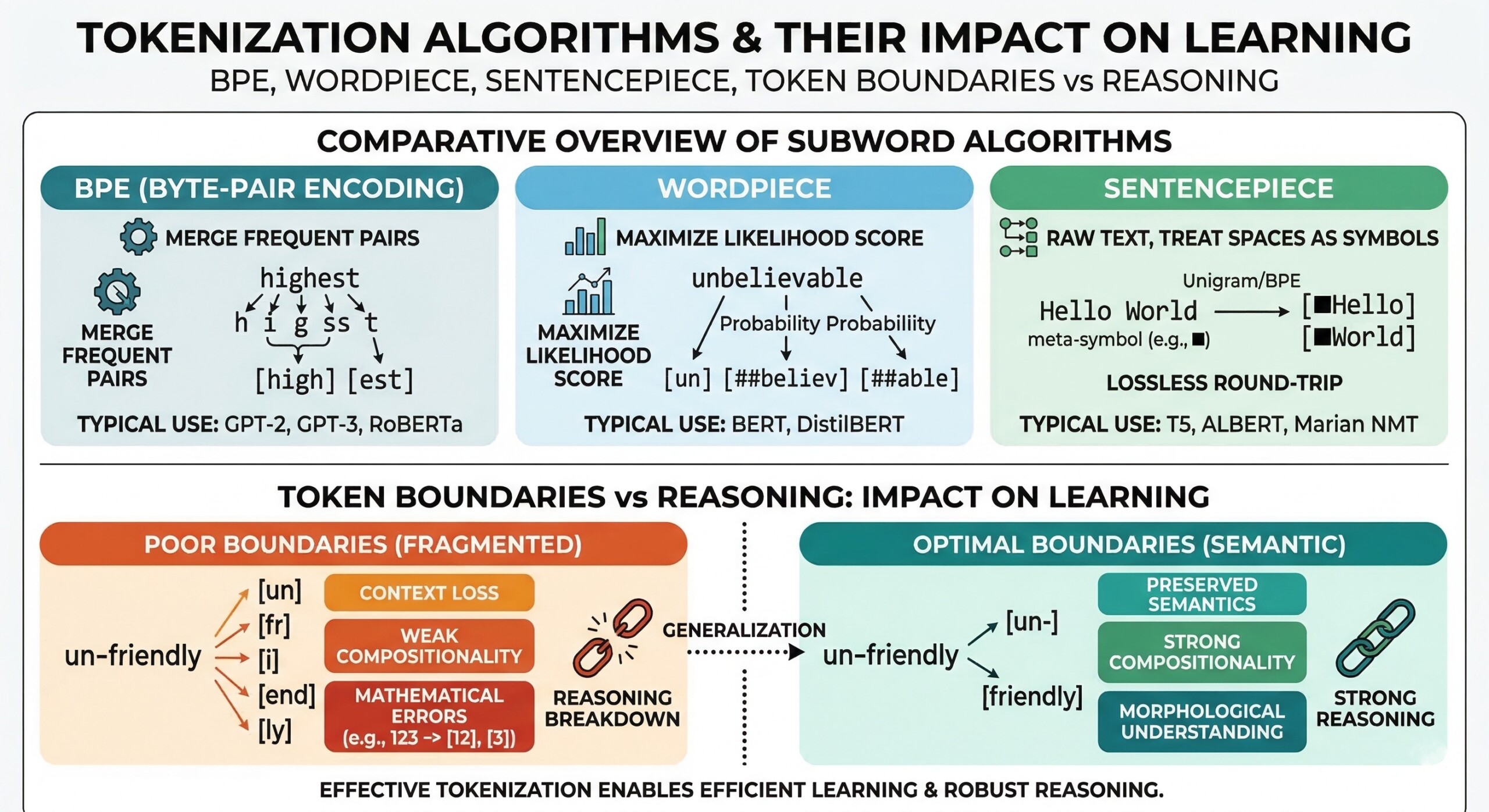
BPE, WordPiece, SentencePiece, Token boundaries vs reasoning
Introduction
In the world of modern AI and language models, the journey from raw text to meaningful understanding begins with a deceptively simple step: tokenization. Before a model based on the Transformer architecture can process language, it must first convert words, phrases, or even characters into tokens – structured units that machines can interpret. This foundational step influences not only how efficiently a model learns but also how well it generalizes, reasons, and generates language.
Tokenization is not merely a preprocessing trick; it shapes the very “thinking space” of a model. Algorithms like Byte Pair Encoding (BPE), WordPiece, and SentencePiece define how text is split and represented. These decisions affect vocabulary size, semantic coherence, and ultimately the model’s ability to learn patterns. Subtle differences in token boundaries can lead to significant variations in reasoning capability, especially in tasks involving logic, mathematics, or multi-step inference.
Let’s dive deep into the topic.
1. Tokenization defines the learning units
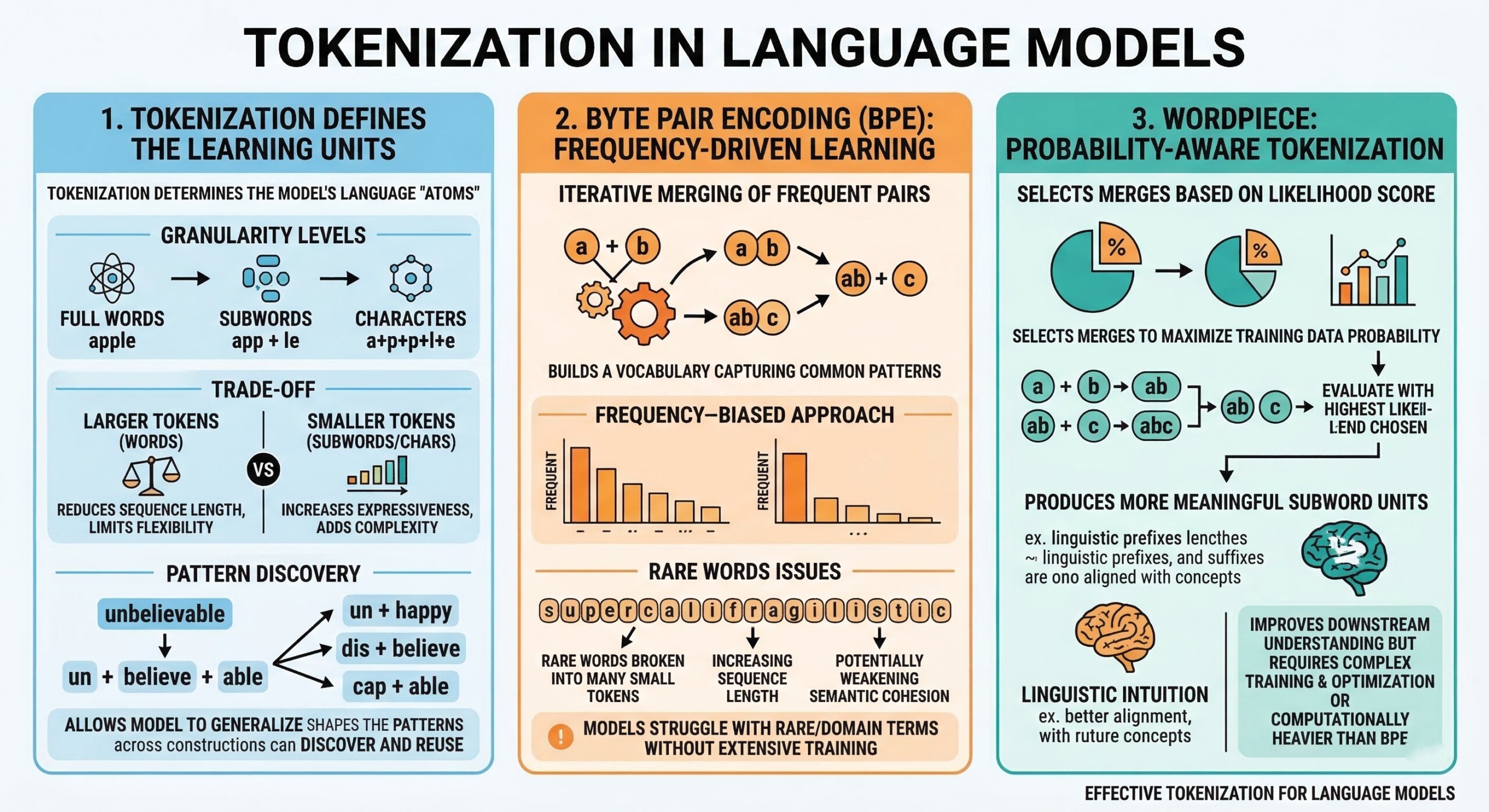
At its core, tokenization determines what a model sees as its “atoms” of language. Whether tokens represent full words, subwords, or characters, they define the granularity of learning. Larger tokens (like whole words) reduce sequence length but limit flexibility, while smaller tokens increase expressiveness but add computational complexity.
This trade-off directly impacts how models learn relationships. For example, splitting “unbelievable” into “un + believe + able” allows the model to generalize across similar constructions. Thus, tokenization is not neutral but actively shapes the patterns the model can discover and reuse.
2. Byte Pair Encoding (BPE): Frequency-driven learning
Byte Pair Encoding works by iteratively merging the most frequent pairs of characters or subwords. Over time, it builds a vocabulary that captures common patterns in the training data.
This approach is efficient and widely used, but it is inherently frequency-biased. Rare words may be broken into many small tokens, increasing sequence length and potentially weakening semantic cohesion. As a result, models using BPE may struggle slightly with rare or domain-specific terms unless extensively trained. An excellent collection of learning videos awaits you on our Youtube channel.
3. WordPiece: Probability-aware tokenization
WordPiece improves upon BPE by selecting merges based on likelihood rather than raw frequency. It aims to maximize the probability of the training data under a language model.
This subtle shift leads to more meaningful subword units. WordPiece tends to produce tokens that align better with linguistic intuition, improving downstream understanding. However, it requires more complex training and optimization, making it computationally heavier than BPE.
4. Sentence Piece: Language independence and flexibility
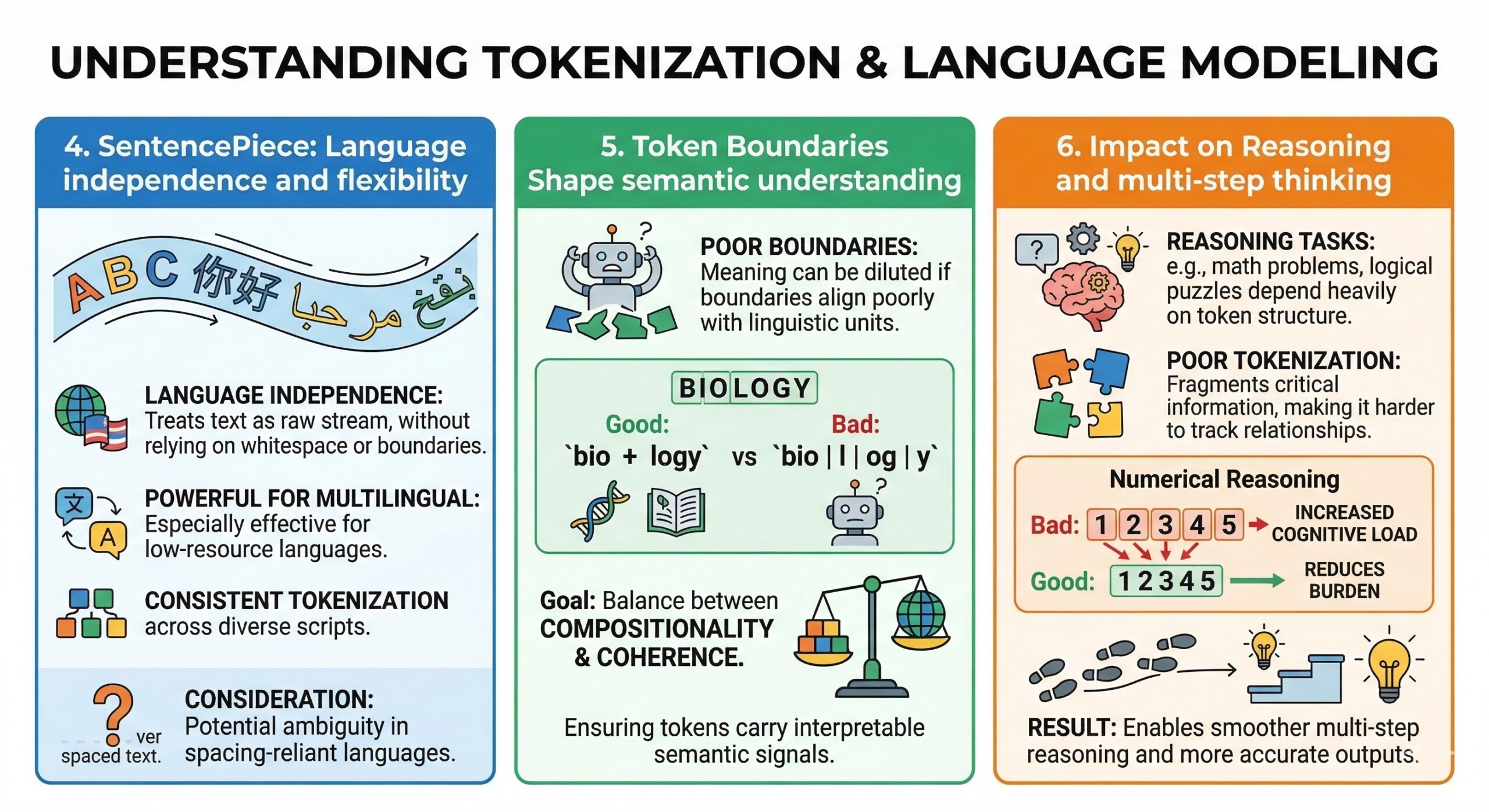
SentencePiece takes a different approach by treating text as a raw stream of characters, without relying on whitespace or predefined word boundaries.
This makes it especially powerful for multilingual and low-resource languages. It also enables consistent tokenization across diverse scripts. However, the lack of explicit word boundaries can sometimes introduce ambiguity, especially in languages where spacing carries meaning. A constantly updated Whatsapp channel awaits your participation.
5. Token Boundaries Shape semantic understanding
Token boundaries determine how meaning is segmented. If boundaries align poorly with linguistic units, the model may struggle to capture semantics effectively.
For instance, splitting “biology” into “bio + logy” may help generalization, but splitting it into arbitrary fragments can dilute meaning. Good tokenization strikes a balance between compositionality and coherence, ensuring that tokens carry interpretable semantic signals.
6. Impact on Reasoning and multi-step thinking
Reasoning tasks – such as solving math problems or logical puzzles – depend heavily on how information is structured in tokens. Poor tokenization can fragment critical information, making it harder for the model to track relationships.
Consider numerical reasoning: if numbers are split inconsistently, the model must reconstruct them internally, adding cognitive load. Well-designed tokenization reduces this burden, enabling smoother multi-step reasoning and more accurate outputs. Excellent individualised mentoring programmes available.
7. Vocabulary size vs sequence length trade-off
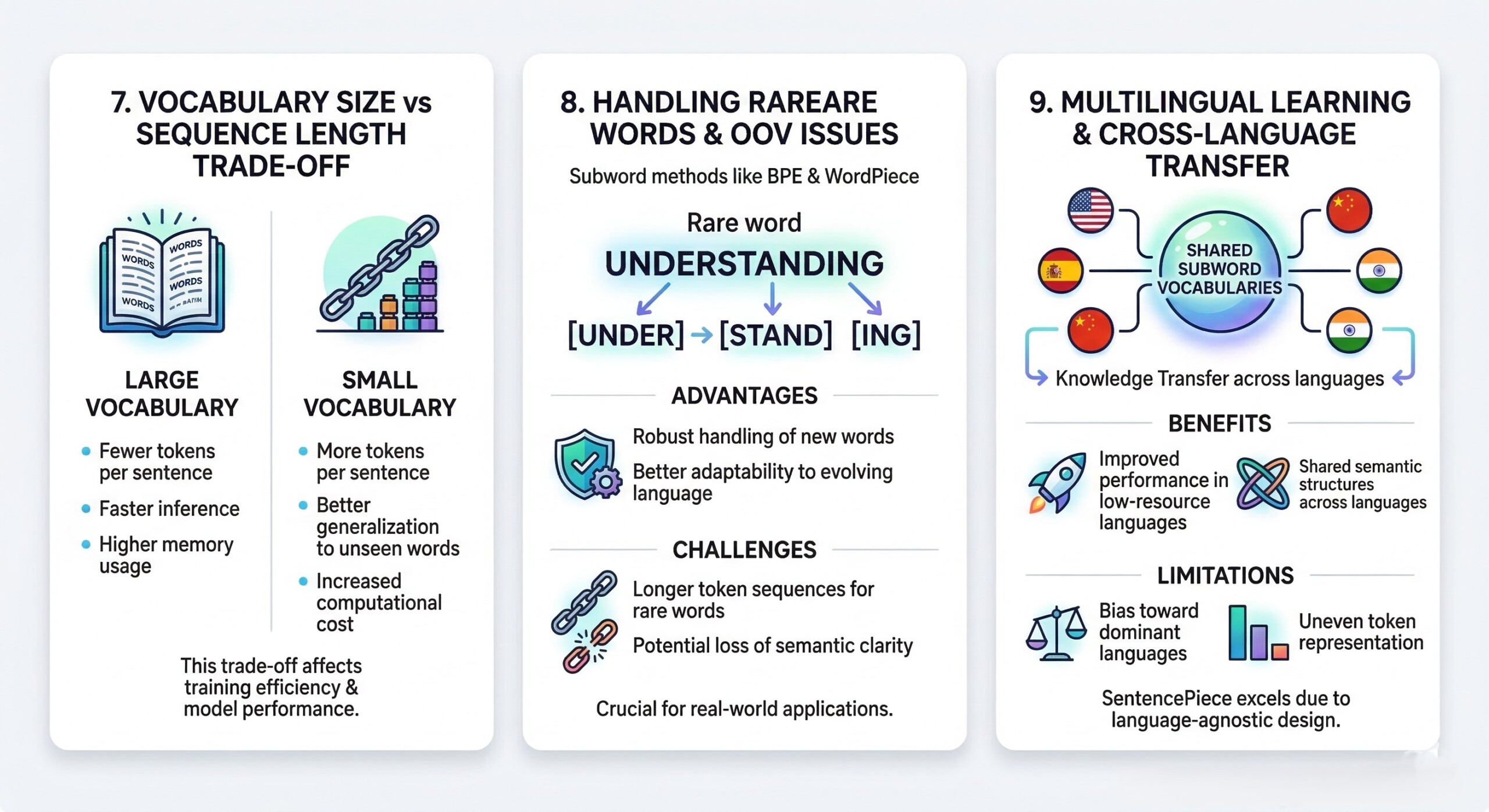
One of the central design decisions in tokenization is choosing between a large vocabulary and shorter sequences, or a smaller vocabulary with longer sequences.
- Large vocabulary
- Fewer tokens per sentence
- Faster inference
- Higher memory usage
- Small vocabulary
- More tokens per sentence
- Better generalization to unseen words
- Increased computational cost
This trade-off directly affects training efficiency and model performance, especially in large-scale systems.
8. Handling rare words and Out-of-Vocabulary (OOV) issues
Subword tokenization methods like BPE and WordPiece are designed to address the classic OOV problem. Instead of failing on unseen words, they decompose them into known subunits.
- Advantages
- Robust handling of new words
- Better adaptability to evolving language
- Challenges
- Longer token sequences for rare words
- Potential loss of semantic clarity
This balance is crucial for real-world applications where language is constantly changing. Subscribe to our free AI newsletter now.
9. Multilingual learning and cross-language transfer
Tokenization plays a pivotal role in multilingual models. Shared subword vocabularies allow models to transfer knowledge across languages.
- Benefits
- Improved performance in low-resource languages
- Shared semantic structures across languages
- Limitations
- Bias toward dominant languages
- Uneven token representation
SentencePiece, in particular, excels in this domain due to its language-agnostic design.
10. Tokenization and model efficiency
Efficient tokenization reduces computational load and speeds up both training and inference. Shorter sequences mean fewer operations in attention mechanisms, which are central to the Transformer architecture.
However, efficiency should not come at the cost of understanding. Over-compression of tokens can obscure meaning, while overly fine-grained tokenization can slow down processing. The ideal tokenizer balances efficiency with representational richness. Upgrade your AI-readiness with our masterclass.
Conclusion
Tokenization is often overlooked in discussions about AI, yet it fundamentally shapes how models learn, reason, and perform. Algorithms like BPE, WordPiece, and SentencePiece are not just technical choices – they are design decisions that influence the cognitive structure of machine learning systems. From vocabulary construction to semantic representation, tokenization defines the building blocks of intelligence in language models.
As AI systems continue to evolve, the importance of token boundaries and their alignment with reasoning will only grow. Future innovations may move beyond static tokenization toward more dynamic, context-aware approaches. But even then, the core insight remains: how we break language apart determines how machines learn to put meaning back together.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



