Why Sarvam AI’s success isn’t trivial
")
Why Sarvam AI’s success isn’t trivial
And why it’s neither a DeepSeek moment, not a guaranteed success for future
Introduction
In a world totally dominated by American and Chinese AI models, an Indian company building a self-dependent stack of AI technology, and launching commercially available suite of AI products, deserves compliments. The Indian AI ecosystem is currently structurally optimized for adoption and integration, not frontier creation. Indian AI companies are limited not by intelligence or ambition, but by six factors: Compute access, Data moats, Research depth, Product-first incentives, Platform dependency, and weak institutional AI infrastructure.
Sarvam’s new 105-Billion parameter Mixture-of-Experts model (MoE) has a 128K context window but only activates 9B parameters at a time. That is a high technological performance. Unlike other US/Chinese models, it processes Hindi, Tamil, or Bengali just as fast and cheaply as English. Sarvam claims its latest releases are genuine foundation models, pretrained from first principles instead of being distilled, adapted, or transfer-learned from existing frontier models.
Sarvam’s success in rolling out a full suite of products in light of these weaknesses is creditable! If built well over the next few years, Sarvam AI can become a true template for national sovereign AI for India. But miles to go before we sleep! Let’s dive deep now.
1. What is Sarvam
Sarvam is an India-first, full-stack AI platform building sovereign large language, speech, translation, vision, and edge models. It is optimized for Indic languages, code-mixed speech, low-latency deployment, and governance. Sarvam integrates training, inference, tooling, and deployment for population-scale applications. It operates under data-sovereignty, privacy, and cost constraints across public and enterprise systems now.
What makes Sarvam non-trivial is not that it matches GPT or Gemini on generic benchmarks but it doesn’t need to. Sarvam is solving a problem global labs structurally ignore: token inefficiency, code-mixed speech, dialect noise, OCR over messy Indian documents, and edge deployment across unreliable networks.
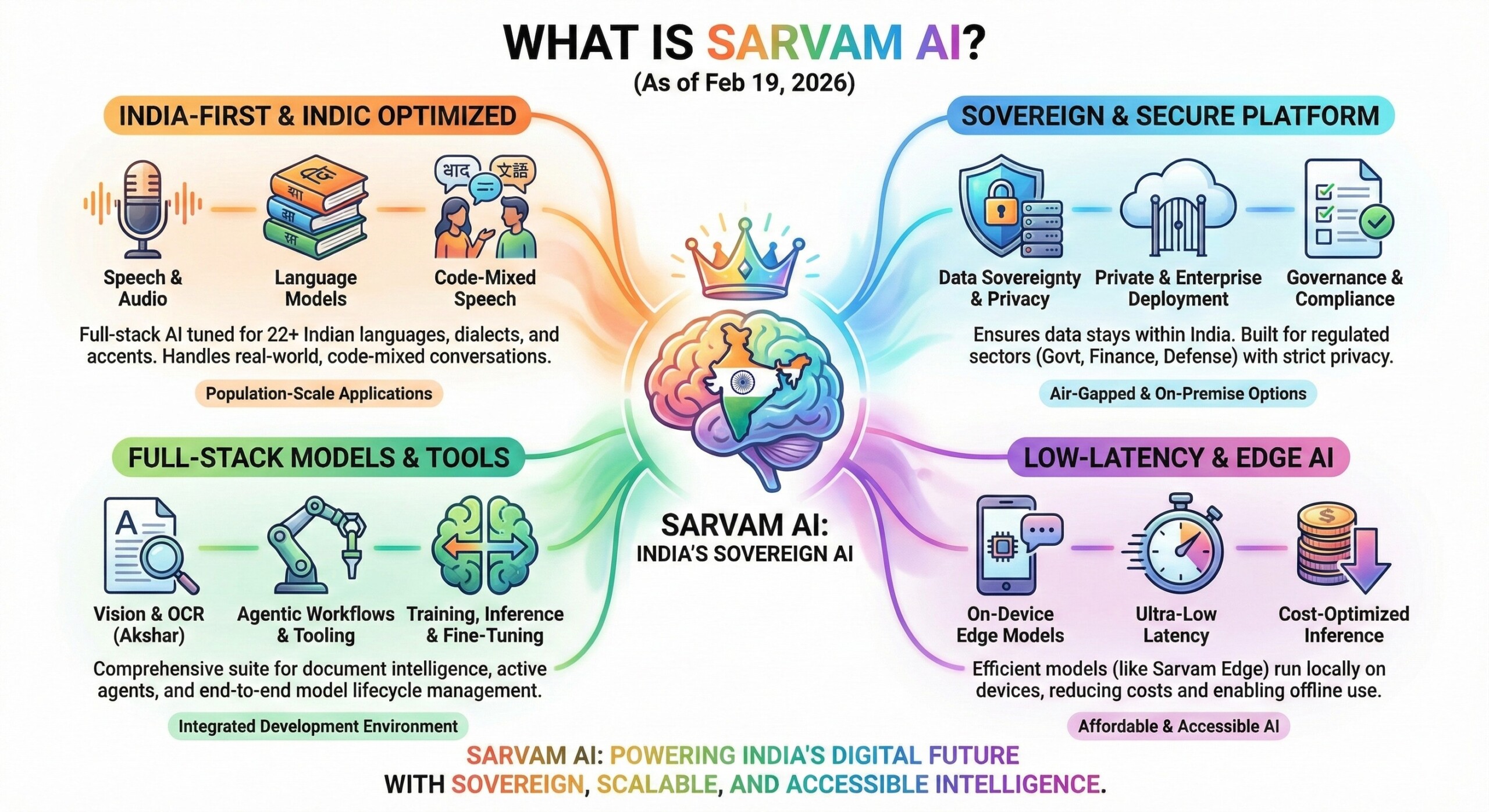
2. What a Sovereign AI means
A Sovereign AI Stack aligns national compute, data sovereignty, foundation models, secure platforms, and citizen-facing applications into one trusted ecosystem. It ensures local control over infrastructure. It follows compliant data governance, culturally grounded models, safe deployment across cloud and edge. Its goal is real-world impact for public services, enterprises, and strategic national priorities.
If you are not a sovereign AI stack, you are a dependency stack: models, data, compute, and platforms controlled by external providers. You assemble capabilities from global clouds and APIs, inherit foreign governance, pricing, and policy constraints, and remain exposed to outages, sanctions, data residency conflicts, and shifting terms of access. An excellent collection of learning videos awaits you on our Youtube channel.
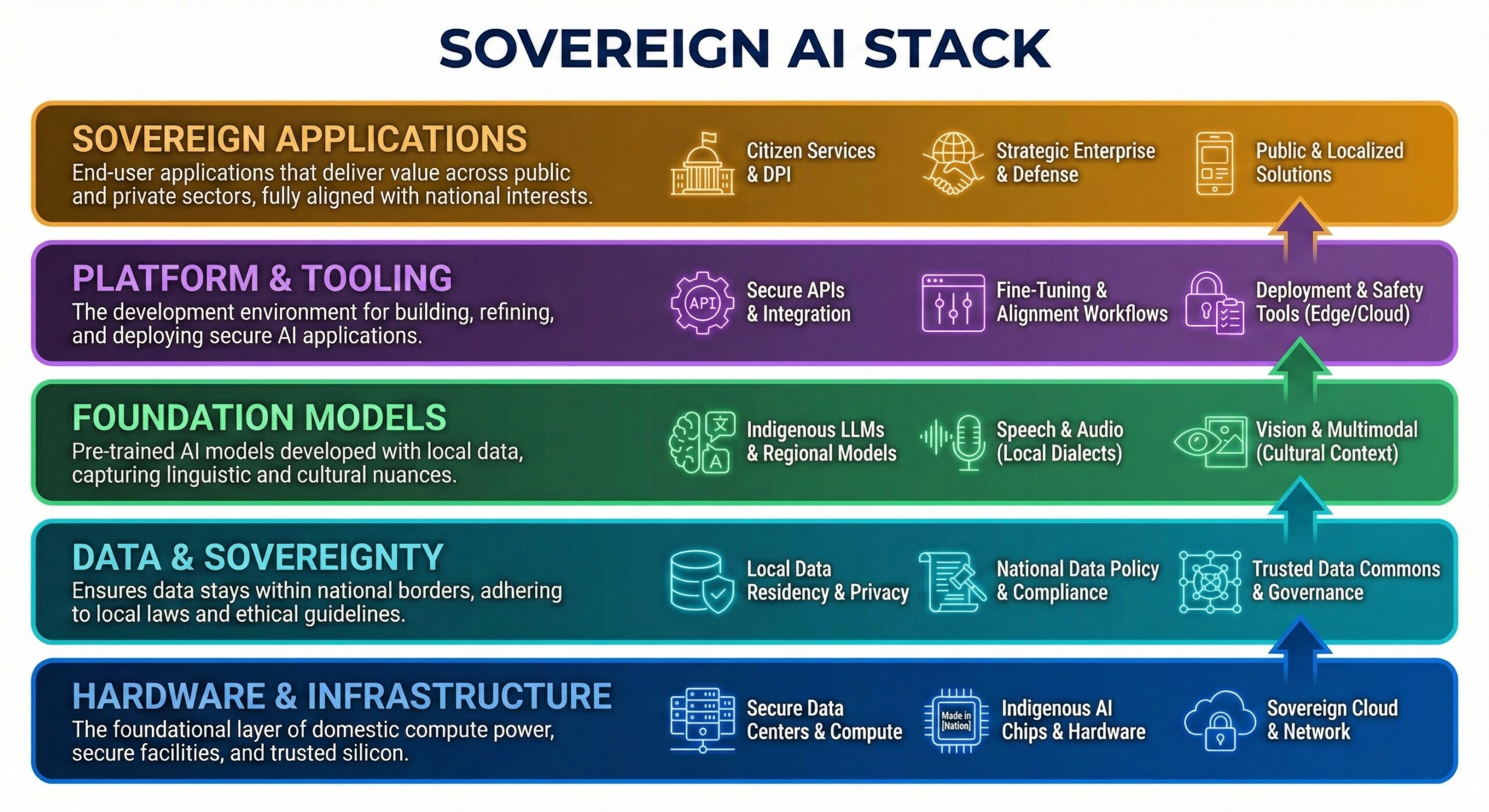
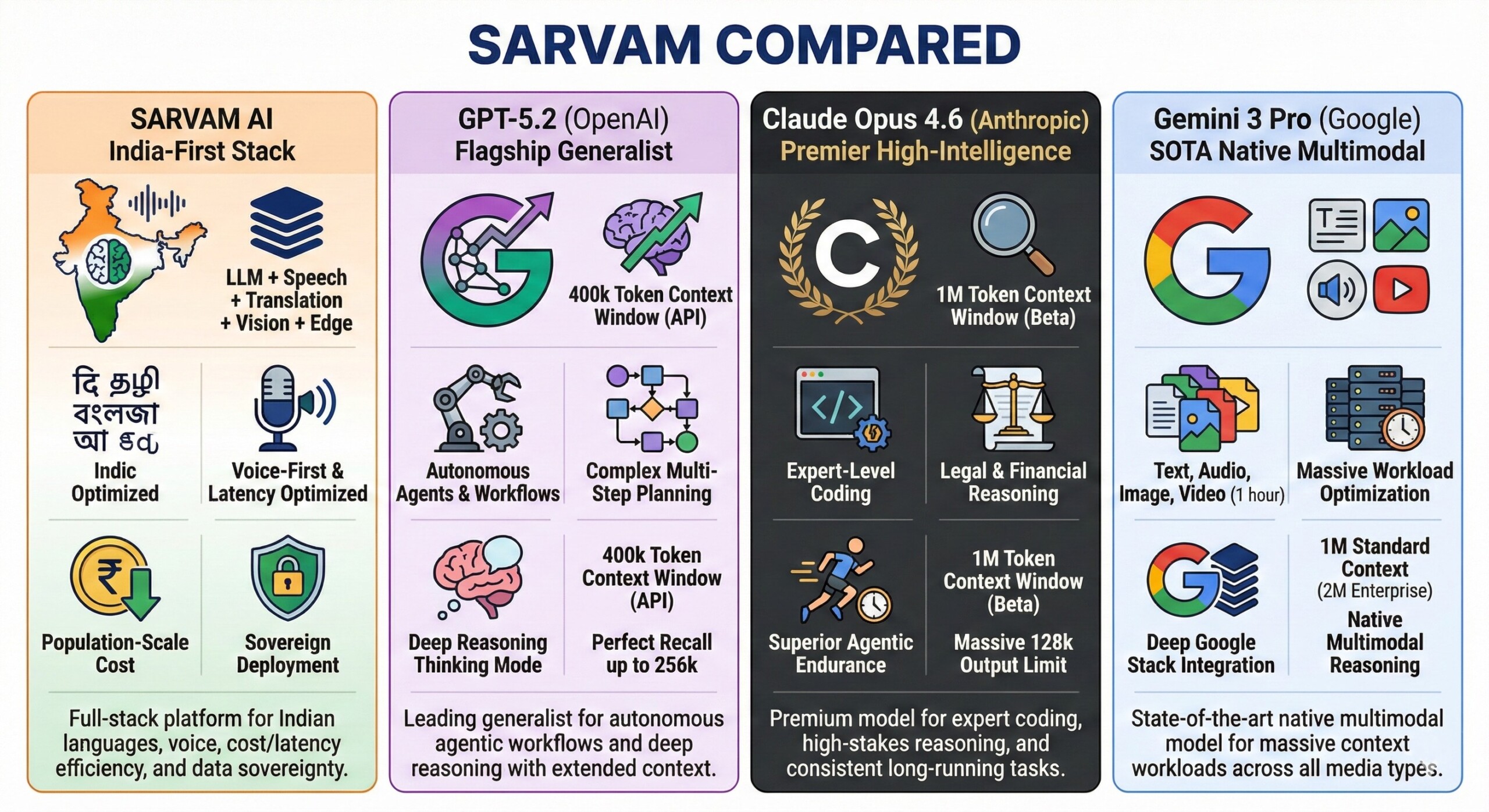
3. A quick definition of leading models
- Sarvam: India-first stack (LLM + speech + translation + vision + edge) optimized for Indic languages, voice, population-scale cost/latency, and sovereign deployment.
- GPT-5.2 (OpenAI): Flagship generalist “frontier” model family; leads in autonomous agentic workflows and complex multi-step planning. Features a dedicated Thinking mode for deep reasoning and a 400k token context window in the API (with perfect recall up to 256k).
- Claude Opus 4.6 (Anthropic): Premier high-intelligence model for expert-level coding and legal/financial reasoning. Known for superior “agentic endurance” and consistency in long-running tasks. Features a 1M token context window (currently in beta) and a massive 128k output limit.
- Gemini 3 Pro (Google): State-of-the-art native multimodal model; reasons across text, audio, image, and video (up to 1 hour) in a single prompt. Optimized for massive workloads with a 1M token standard context (2M available for Enterprise) and deep integration into the Google Antigravity agentic stack.
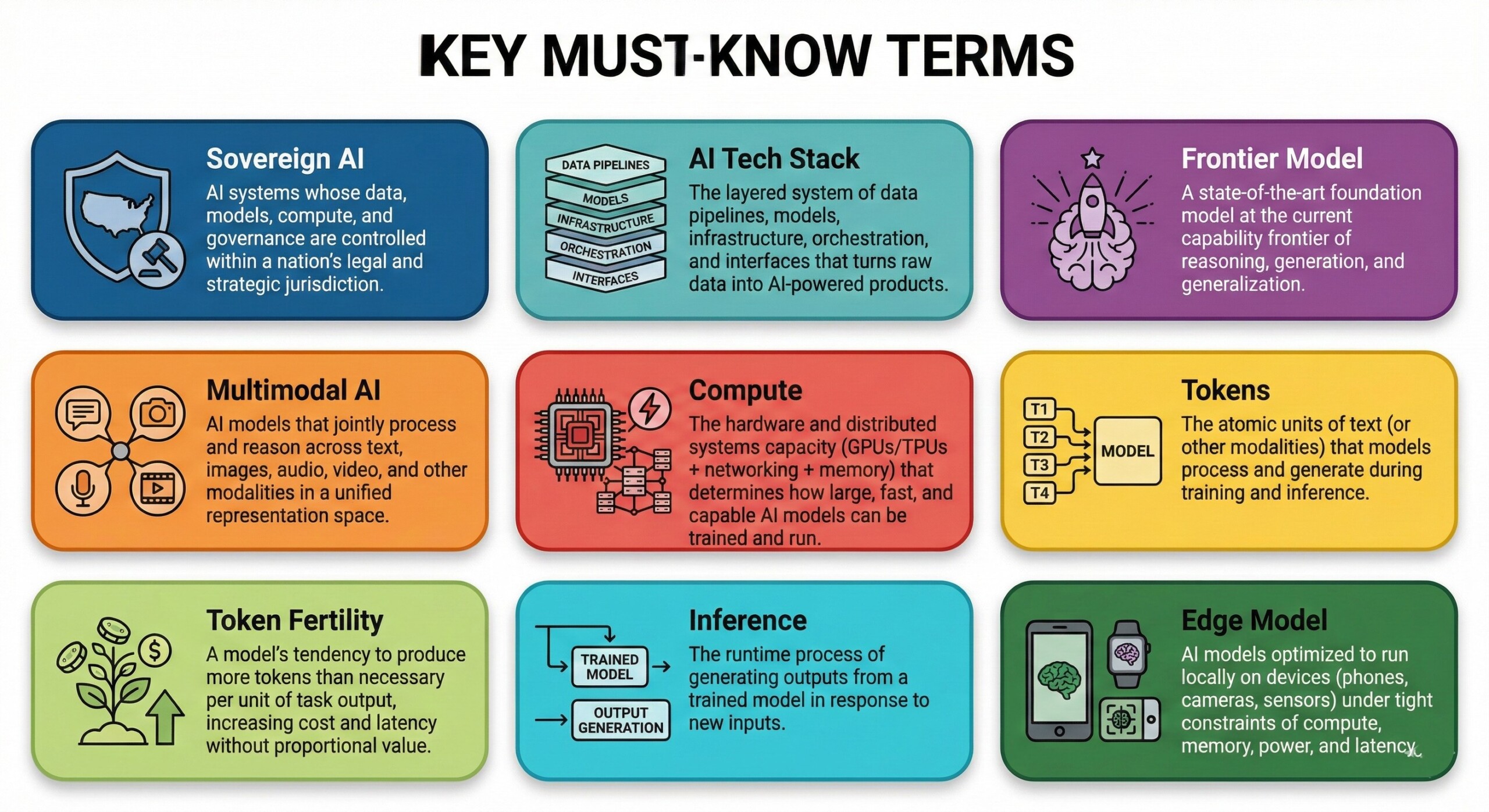
4. Some terms you must know
- Sovereign AI: AI systems whose data, models, compute, and governance are controlled within a nation’s legal and strategic jurisdiction.
- AI Tech Stack: The layered system of data pipelines, models, infrastructure, orchestration, and interfaces that turns raw data into AI-powered products.
- Frontier Model: A state-of-the-art foundation model at the current capability frontier of reasoning, generation, and generalization.
- Multimodal AI: AI models that jointly process and reason across text, images, audio, video, and other modalities in a unified representation space.
- Compute: The hardware and distributed systems capacity (GPUs/TPUs + networking + memory) that determines how large, fast, and capable AI models can be trained and run.
- Tokens: The atomic units of text (or other modalities) that models process and generate during training and inference.
- Token Fertility: A model’s tendency to produce more tokens than necessary per unit of task output, increasing cost and latency without proportional value.
- Inference: The runtime process of generating outputs from a trained model in response to new inputs.
- Edge Model: AI models optimized to run locally on devices (phones, cameras, sensors) under tight constraints of compute, memory, power, and latency. A constantly updated Whatsapp channel awaits your participation.
5. Quick “which should I choose” guide
- Choose Sarvam if your core problem is India language + voice + cost/latency + sovereignty/edge deployment.
- Choose GPT-5.2 if you want a top-tier generalist for coding + tool-using agents + long-context across enterprise knowledge work.
- Choose Claude Opus 4.6 if you want deep reasoning + huge context and strong “careful planning” for complex workflows.
- Choose Gemini 3 Pro if you need native multimodal + massive context and you’re already in Google’s ecosystem (Vertex, Workspace, etc.).
6. Details on Sarvam
As of February 19, 2026, Sarvam AI has solidified its position as the cornerstone of India’s “Sovereign AI” movement.
- Day 1 (Founding): Aug 2023 – Sarvam AI was founded in August 2023 by Dr. Vivek Raghavan (ex-Aadhaar/Nilekani) and Dr. Pratyush Kumar (ex-Microsoft Research/AI4Bharat) in Bengaluru, with the stated mission of building “AI for all from India” and a full-stack AI platform developed, deployed, and governed in India.
- Early positioning (2023): “Full-stack” + India-first – From the start, Sarvam framed itself as building both (a) sovereign models (Indic + voice-first) and (b) deployment/platform layers for enterprises and public-good use cases.
- Major funding milestone: Dec 7, 2023 – Sarvam announced a $41M Series A led by Lightspeed, with Peak XV Partners and Khosla Ventures participating.
- “Platform era” begins: Aug 13, 2024 – Sarvam launched its full-stack GenAI platform for India, positioned as voice-enabled + multilingual, initially supporting 10 Indian languages for productized deployments.
- Agents go live (Aug 2024): At launch, Sarvam highlighted voice-enabled, action-oriented “Sarvam Agents” deployable via telephone, WhatsApp, or in-app, and even stated a starting cost point of ~₹1/min (their claim).
- Sarvam 2B (Aug 2024): foundational model claim – Sarvam’s launch post described “Sarvam 2B” as India’s first open-source 2B Indic LLM trained “from scratch” on an internal dataset of 4T tokens, with compute in India, optimized for 10 Indian languages.
- Shuka 1.0 (Aug 2024): audio language model – The same launch post introduced Shuka 1.0 as an open-source AudioLM (audio-in, text-out) aimed at Indian-language voice use.
- Mayura (Sep 6, 2024): translation tuned for real India – Sarvam introduced Mayura as a translation model built to handle colloquial language, dialect variation, and code-mixing, addressing common failures of “formal-only” translation systems.
- Sarvam-1 (Oct 24, 2024): first “Indian language LLM” milestone – Sarvam published Sarvam-1 as a 2B-parameter model optimized for Indian languages, emphasizing tokenizer efficiency and a curated corpus.
- Tokenizer efficiency as a differentiator (Sarvam-1): Sarvam claims Indic scripts often need 4–8 tokens/word in many multilingual tokenizers, while Sarvam-1’s tokenizer targets ~1.4–2.1 fertility across supported Indic languages.
- Training-data scale claim (Sarvam-1): Sarvam describes building an Indic-focused pretraining corpus (they call it “Sarvam 2T”) with ~2 trillion tokens for 10 Indic languages (plus English).
- Sovereign AI dream begins via Government selection: Apr 26, 2025 (IndiaAI Mission) – Sarvam announced it was selected by the Government of India under the IndiaAI Mission to build India’s sovereign LLM, “capable of reasoning, designed for voice, fluent in Indian languages,” intended for secure population-scale deployment.
- Sovereign roadmap (2025): 3 variants – Sarvam stated it would develop Sarvam-Large, Sarvam-Small, and Sarvam-Edge variants as part of the sovereign effort, in collaboration with AI4Bharat (IIT Madras).
- Sarvam-M (May 23, 2025): chat + reasoning model – Sarvam introduced Sarvam-M (24B) and published benchmark comparisons showing strong performance on Indic-focused evaluations and competitive coding/math scores versus similar-class global models.
- Sarvam Translate (Jun 7, 2025): 22-language translation – Sarvam released Sarvam-Translate, describing it as fine-tuned from Gemma3-4B-IT, supporting 22 Scheduled Indian languages and long-form/structured translation.
- What Sarvam Translate cannot do well (explicit limits): Sarvam notes weaker translation quality / occasional incomplete outputs for some low-resource languages (e.g., Bodo, Dogri, Kashmiri, Manipuri, Santali, Sanskrit, Sindhi), and that it wasn’t extensively trained for very long LaTeX/HTML, recommending splitting large files.
- Saaras V3 (Feb 10, 2026): speech-to-text at national language scale – Sarvam introduced Saaras V3 supporting 22 official Indian languages + English, streaming low-latency decoding, trained on 1M+ hours of curated multilingual audio, and reported ~19% WER on IndicVoices (10-language subset).
- Bulbul V3 (Feb 5, 2026): text-to-speech for India – Sarvam launched Bulbul V3 with 35+ voices across 11 languages (and stated expansion toward 22), plus voice cloning and robustness emphasis for numerics, named entities, code-mix, and Romanized text.
- Sarvam Vision (Feb 5, 2026): document intelligence VLM – Sarvam released Sarvam Vision, describing it as a 3B-parameter state-space vision-language model for captioning, OCR, chart interpretation, and complex table parsing, with explicit focus on Indian-language document intelligence.
- Sarvam Audio (Feb 2, 2026): audio extension of sovereign 3B – Sarvam described Sarvam Audio as an audio extension of a 3B model pretrained from scratch on English + 22 Indian languages, adding context-aware ASR features (multiple transcription formats, long-duration robustness, multi-speaker) and even “speech-to-command” style function calling.
- Sarvam Edge (Feb 14, 2026): on-device push with specs – Sarvam announced Sarvam Edge and published concrete on-device model specs, e.g. ASR: 74M params (~294MB FP16) with TTFT under ~300ms; TTS: 24M params (~60MB); Translation: ~150M params (~334MB), emphasizing offline, privacy, and low-latency inference.
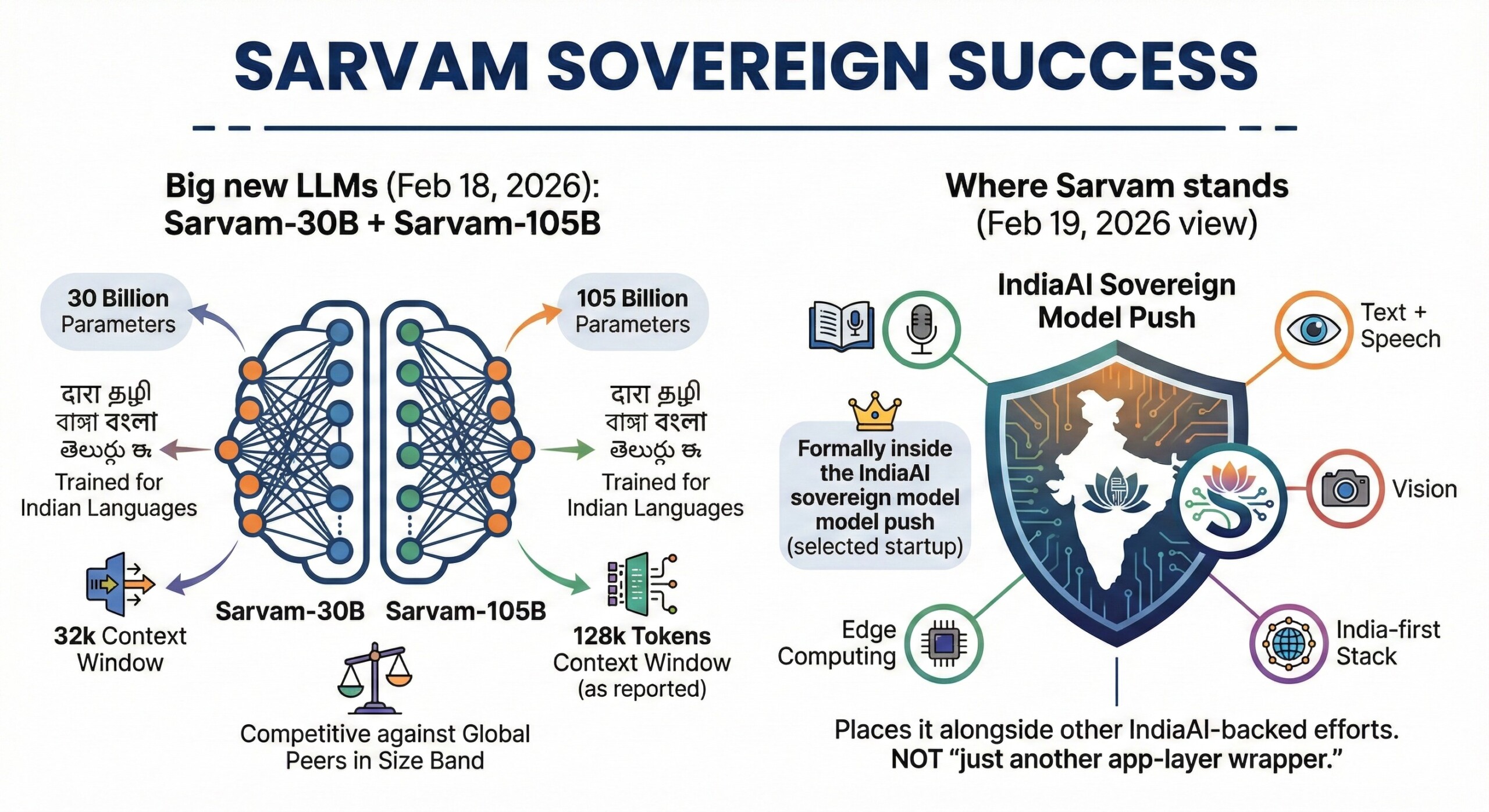
- Big new LLMs (Feb 18, 2026): Sarvam-30B + Sarvam-105B – Sarvam announced 30B and 105B parameter models trained for Indian languages; reporting 32k context for 30B and 128k tokens for 105B (as reported), and positioning them as competitive against several global peers in their size band.
- Where Sarvam stands (Feb 19, 2026 view): Sarvam is now one of the most visible “India-first” stacks spanning text + speech + vision + edge, and it is formally inside the IndiaAI sovereign model push (selected startup). This places it alongside other IndiaAI-backed efforts and not “just another app-layer wrapper.” Excellent individualised mentoring programmes available.
7. Global comparison: where it’s strong
- Indic speech + code-mix realism: Saaras V3 is explicitly trained/evaluated for noisy, code-mixed Indian speech and reports strong IndicVoices results.
- Indic translation breadth: Sarvam-Translate targets all 22 Scheduled languages and structured documents (a frequent real-world pain point).
- Model-to-product integration: Sarvam’s docs show a coherent lineup (ASR/TTS/translation/chat/document intelligence) designed for deployable workflows.
8. Global comparison: where it’s still constrained / not “magic”
- Not a frontier replacement in everything: Even with 30B/105B, global frontier labs still lead at the extreme end (tool ecosystems, safety research depth, multi-domain breadth). Sarvam’s advantage is India-first specialization more than “beat everyone at everything.”
- Language quality variance is real: Sarvam itself documents uneven performance for some lower-resource languages and structured long-form formats.
- On-device tradeoffs: Edge models are intentionally smaller; they win on privacy/latency/cost, but will lag big cloud models on deep reasoning and open-ended generation. Subscribe to our free AI newsletter now.
9. How it beats some leading AI models
Sarvam does heavyweight AI reasoning power at a fraction of the running cost. Their new 105-Billion parameter Mixture-of-Experts model (MoE) has a 128K context window but only activates 9B parameters at a time.
It can comprehend messy invoices, complex tables, and local PDFs better than US models. That is because Sarvam Vision hits a good 93.28% accuracy on OmniDocBench, outperforming frontier models like Gemini 3 Pro, ChatGPT, and DeepSeek.
Unlike other US/Chinese models, it processes Hindi, Tamil, or Bengali just as fast and cheaply as English. Global models use 4-8 tokens per word for Indian languages. Sarvam slashes this to 1.4-2.1 across all 22 official languages. That is how token fertility is managed.
Quality clearly beats quantity. Highly specialized local models can completely outsmart much bigger, more expensive global ones. In complex reasoning and Indian languages, Sarvam’s focused 105B model beats massive giants like DeepSeek R1 (which has 600B parameters).
This is in line with our earlier point that while ChatGPT and Gemini are foundation general models (the jacks of all trades) for general work, India’s Sarvam is a highly specialized Indic model that completely beats the giants in its chosen narrow Indic domain.
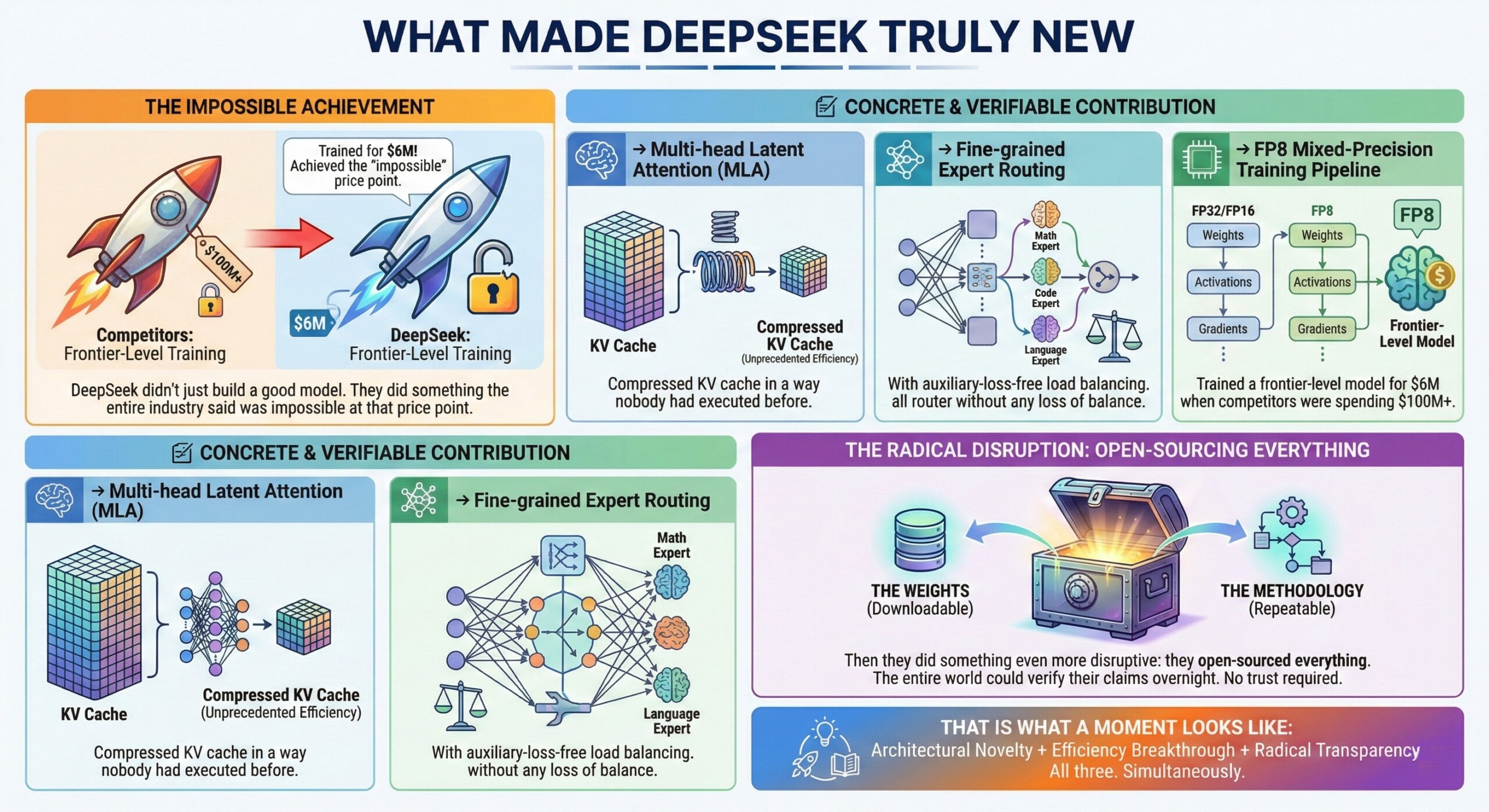
10. Why Sarvam is not DeepSeek – Limitations, and risks it faces
A. Sarvam is an innovation and not pure invention. Innovation and invention aren’t the same. Invention creates something fundamentally new – a new method, device, or capability that did not exist before. Innovation takes ideas or technologies, new or existing, and turns them into scalable, useful, and economically viable solutions in the real world. Sarvam is an innovation, as it integrates pre-existing (a) model architectures (e.g., Transformers/MoE), (b) optimization methods, (c) training recipes, (d) tokenization strategies, and (e) commodity GPU-based distributed compute, for creating its models. It did not invent any of these ab initio.
B. Comparing Sarvam with Chinese DeepSeek is incorrect. We cannot say Sarvam is a fully-invented solution in India, because it uses pre-existing templates.
- Sarvam’s MoE design reuses established mixture-of-experts (MoE) paradigms without introducing novel routing, attention, or memory-compression mechanisms. [Mixture of Experts (MoE) for Neural Networks – Allows very large models to run cheaper by activating only parts of the network; Created by Shazeer et al. (Google), in the USA]
- Cost-efficiency gains are incremental optimizations, not a step-change collapse in training or inference economics per parameter. [Low-Cost frontier-scale training – Challenged the belief that only $100M+ budgets can train top-tier models; Created by the DeepSeek AI team, in China]
- No peer-reviewed technical disclosure exists to validate training methodology, optimization stack, or scaling behaviour.
- Claimed capabilities lack independently reproducible benchmarks with publicly verifiable evaluation pipelines.
- Training “from scratch” on Indic corpora reflects sovereign adaptation, not a new pretraining or representation-learning paradigm.
- Openness is deferred rather than immediate, limiting community audit of weights, code, and training dynamics.
- The work has not shifted global research priors on model architecture, efficiency frontiers, or AI cost curves.
C. What a DeepSeek from India will need to do. The Chinese DeepSeek created a true industry-shifting moment by introducing real architectural innovations (MLA-based KV cache compression and efficient MoE routing), collapsing frontier-model training costs via FP8 mixed-precision pipelines, and fully open-sourcing weights, code, and methodology so results were independently reproducible without trust. An Indian company will have to, hence, do these:
- Build a totally new model architecture, not just adapt or adopt existing ones. Something that spooks the American and Chinese companies.
- Create a new cost-effective way of training or inferencing that shakes the industry’s core assumptions. DeepSeek shook the American’s belief that anything less than a $100 million cannot even build a model.
- Open source every bit of your work – the methods, the hyperparameters, the weights et al. This challenges the world to check your truth instantly.
- Peer review that confirms your claims via independent papers and verification. All supposed benchmarks should be checked by anyone.
- A super-quake that forces entire world to check their working methods, fearful they may have gotten it wrong so far.
D. Risks Sarvam faces: It will need huge capital infusion to keep scaling constantly, to not only beat the benchmark performance but to initially subsidize the user costs (till it becomes profitable via scale) but also to stay in the game when the giants decide to go Indic. It will need to do genuine innovation in parallel, as well. Upgrade your AI-readiness with our masterclass.
Summary
Sarvam is India’s reply to the massive new AI market dominated by US, Europe and China. It needs government support to scale globally. It also needs constant research and development to stay in the race, and win customer confidence. Sarvam, today, remains India’s true sovereign AI bet.

Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



