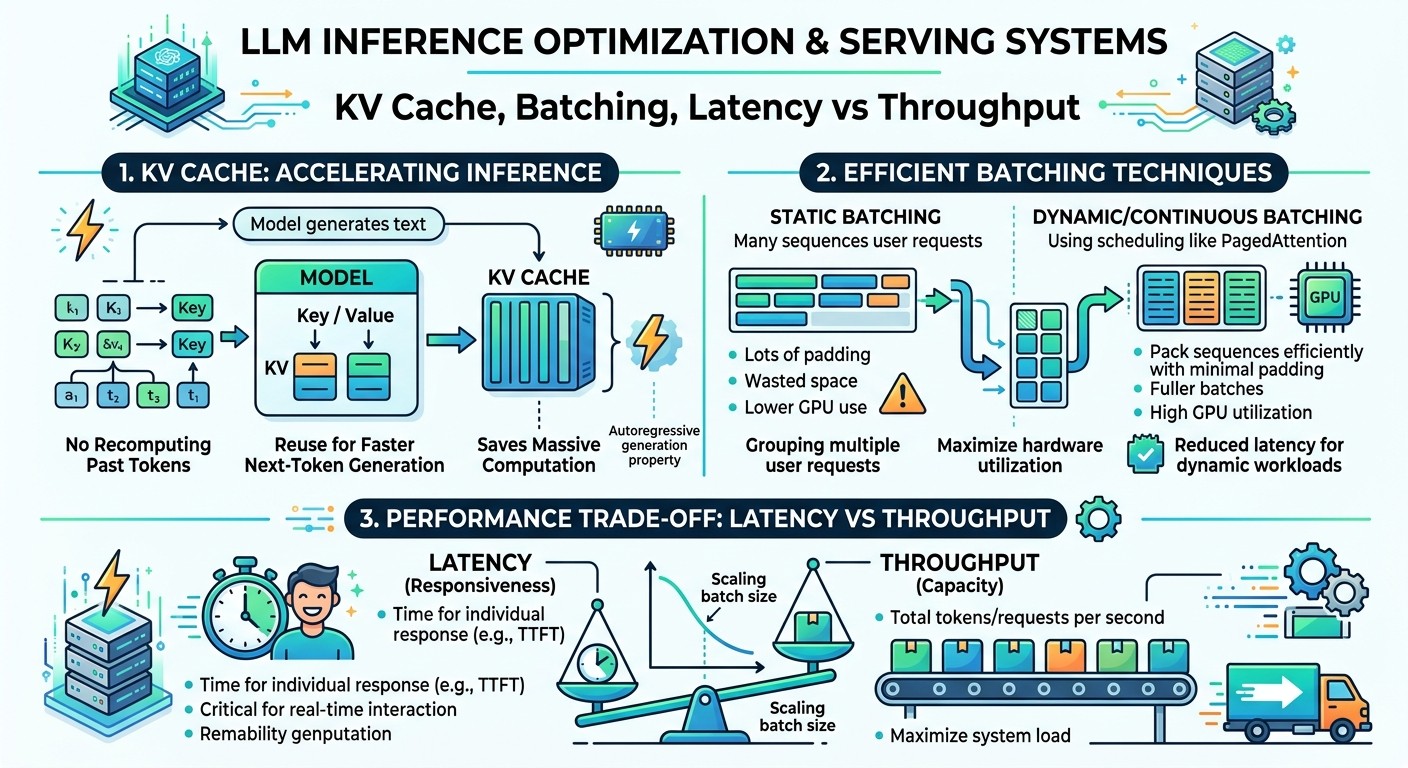
LLM Inference Optimization & Serving Systems

LLM Inference Optimization & Serving Systems
KV cache, Batching, Latency vs Throughput
Introduction
Large Language Models have become the foundation of modern AI applications: chatbots, coding assistants, search systems, tutoring platforms, enterprise copilots, document analyzers, and autonomous agents. However, training a model is only one part of the challenge. Once a model is trained, it must be served efficiently to real users. This is where LLM inference optimization becomes critical.
Inference means using a trained model to generate output. In the case of LLMs, inference usually means taking a user prompt and generating tokens one by one. This may sound simple, but at scale it becomes a major engineering problem. A model may need to serve thousands or millions of users, each with different prompt lengths, output lengths, latency expectations, and cost constraints.
The central challenge is this: how do we serve more users, faster, at lower cost, without reducing model quality?
This lecture focuses on three core ideas in LLM serving:
- KV cache
- Batching
- Latency vs throughput trade-off
Together, these concepts explain why LLM serving is different from ordinary machine learning inference. Traditional ML models often process one input and produce one output in a single forward pass. LLMs, by contrast, generate text step by step. Every generated token depends on all previous tokens. This makes inference memory-heavy, stateful, and sensitive to scheduling decisions.
Modern systems such as vLLM and NVIDIA TensorRT-LLM are designed specifically to optimize this process. vLLM, for example, emphasizes memory optimization and higher throughput through efficient KV cache management, while TensorRT-LLM includes optimized kernels and runtime techniques for NVIDIA GPUs.
Let’s dive deep into the topic now.
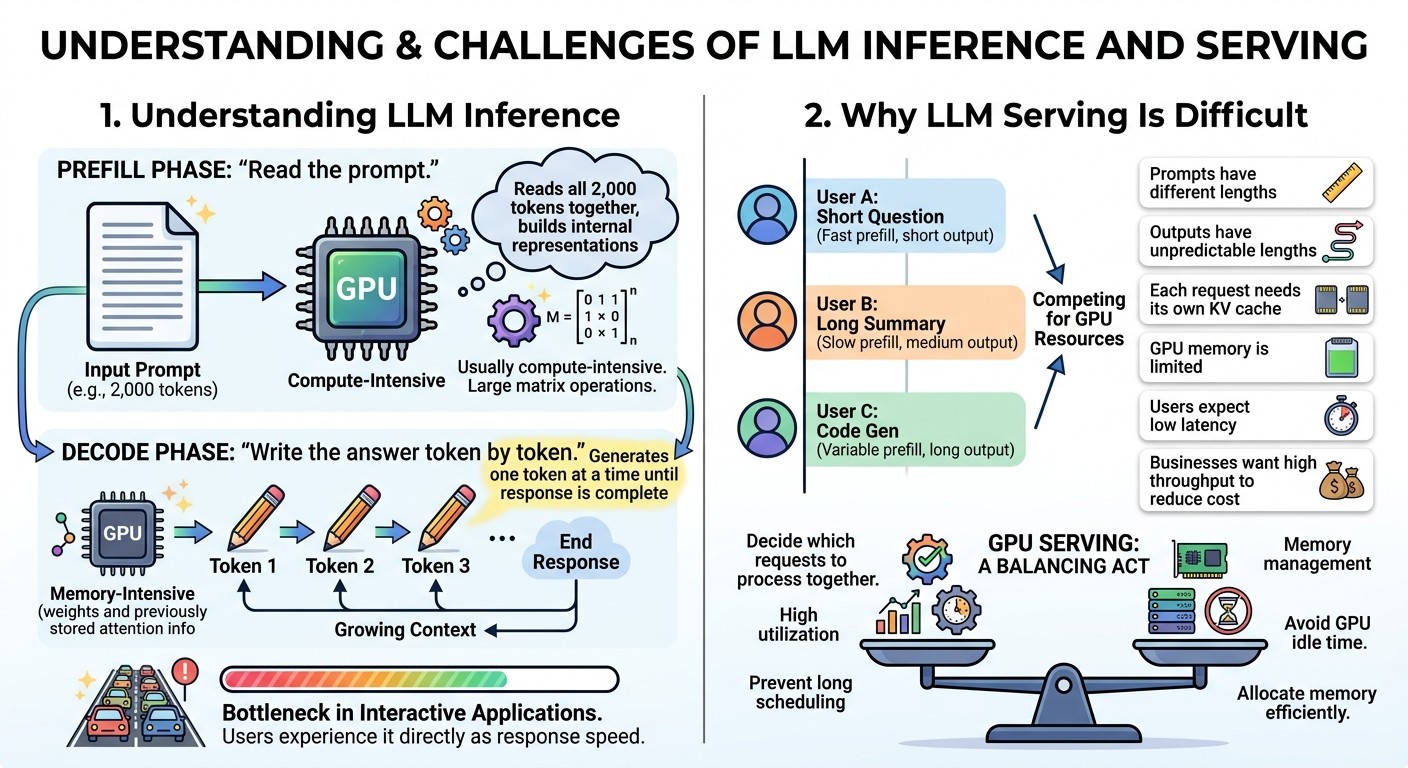
1. Understanding LLM Inference
LLM inference has two main phases: prefill and decode.
In the prefill phase, the model processes the full input prompt. For example, if a user sends a 2,000-token document, the model reads those 2,000 tokens together and builds internal representations. This phase is usually compute-intensive because the GPU performs large matrix operations.
In the decode phase, the model generates one token at a time. After generating one token, that token is added to the context, and the model generates the next token. This continues until the response is complete. The decode phase is often memory-intensive because the model repeatedly reads weights and previously stored attention information.
A simple way to understand this is:
- Prefill: “Read the prompt.”
- Decode: “Write the answer token by token.”
The decode phase is usually the bottleneck in interactive applications because users experience it directly as response speed. Even if the model understands the prompt quickly, the answer still appears gradually.
2. Why LLM Serving Is Difficult
Serving an LLM is not just about loading a model onto a GPU. The system must manage many simultaneous requests, each at a different stage.
One user may send a short question and expect a quick answer. Another user may upload a long document and ask for a summary. A third user may ask for code generation that produces hundreds of tokens. These requests compete for GPU memory, compute time, and scheduling priority.
The difficulty comes from several factors:
- Prompts have different lengths.
- Outputs have unpredictable lengths.
- Each request needs its own KV cache.
- GPU memory is limited.
- Users expect low latency.
- Businesses want high throughput to reduce cost.
This makes LLM serving a balancing act. The system must decide which requests to process together, how much memory to allocate, how to avoid GPU idle time, and how to prevent one long request from slowing down many short ones. An excellent collection of learning videos awaits you on our Youtube channel.
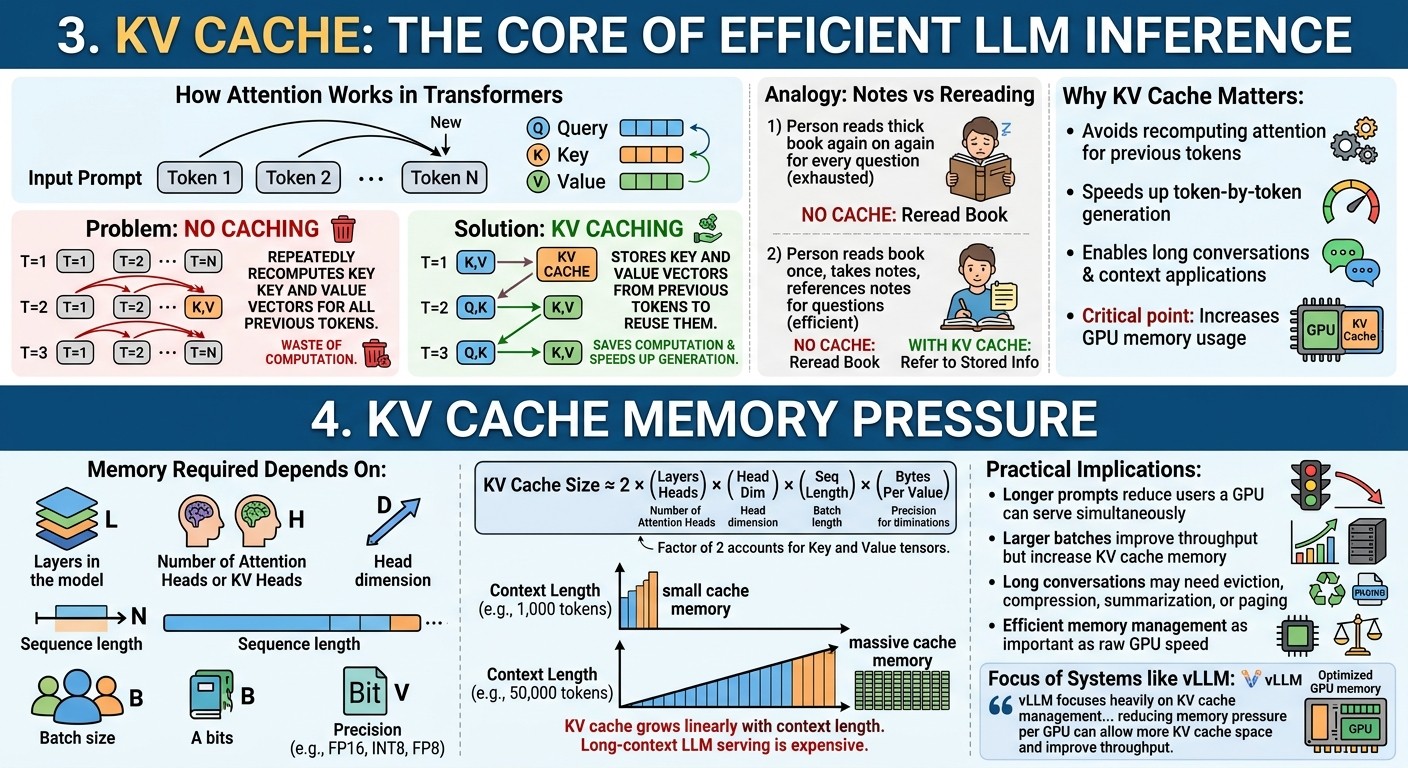
3. KV Cache: The Core of Efficient LLM Inference
The KV cache is one of the most important ideas in LLM inference optimization.
In transformer models, attention uses three types of vectors: Query, Key, and Value. For every new token, the model needs to attend to previous tokens. Without caching, the model would repeatedly recompute the Key and Value vectors for all previous tokens every time it generates a new token. That would be extremely wasteful.
The KV cache stores the Key and Value vectors from previous tokens so they can be reused. This saves computation and makes autoregressive generation practical.
Think of it like taking notes while reading a book. Without notes, every time someone asks a question, you reread the whole book. With notes, you refer to what you already stored.
Why KV cache matters
- It avoids recomputing attention information for previous tokens.
- It speeds up token-by-token generation.
- It enables long conversations and long-context applications.
- It increases GPU memory usage.
This last point is critical. KV cache improves speed, but it consumes memory. NVIDIA notes that LLM GPU memory requirements are mainly driven by model weights and KV cache, and that batching increases KV cache needs because each request has its own cache.
4. KV Cache Memory Pressure
KV cache is useful, but it can become very large.
The memory required depends on:
- Number of layers in the model
- Number of attention heads or KV heads
- Head dimension
- Sequence length
- Batch size
- Precision, such as FP16, BF16, INT8, or FP8
A simplified formula is:
KV cache size ≈ 2 × number of layers × number of KV heads × head dimension × sequence length × batch size × bytes per value
The factor of 2 appears because both Key and Value tensors are stored.
As context length grows, KV cache grows linearly. If one user has a 1,000-token conversation and another has a 50,000-token conversation, the second user requires far more cache memory. This is one reason long-context LLM serving is expensive.
Practical implications
- Longer prompts reduce the number of users a GPU can serve simultaneously.
- Larger batch sizes improve throughput but increase KV cache memory.
- Long conversations may need eviction, compression, summarization, or paging.
- Efficient memory management can be as important as raw GPU speed.
This is why systems such as vLLM focus heavily on KV cache management. vLLM documentation notes that reducing memory pressure per GPU can allow more KV cache space and improve throughput. A constantly updated Whatsapp channel awaits your participation.
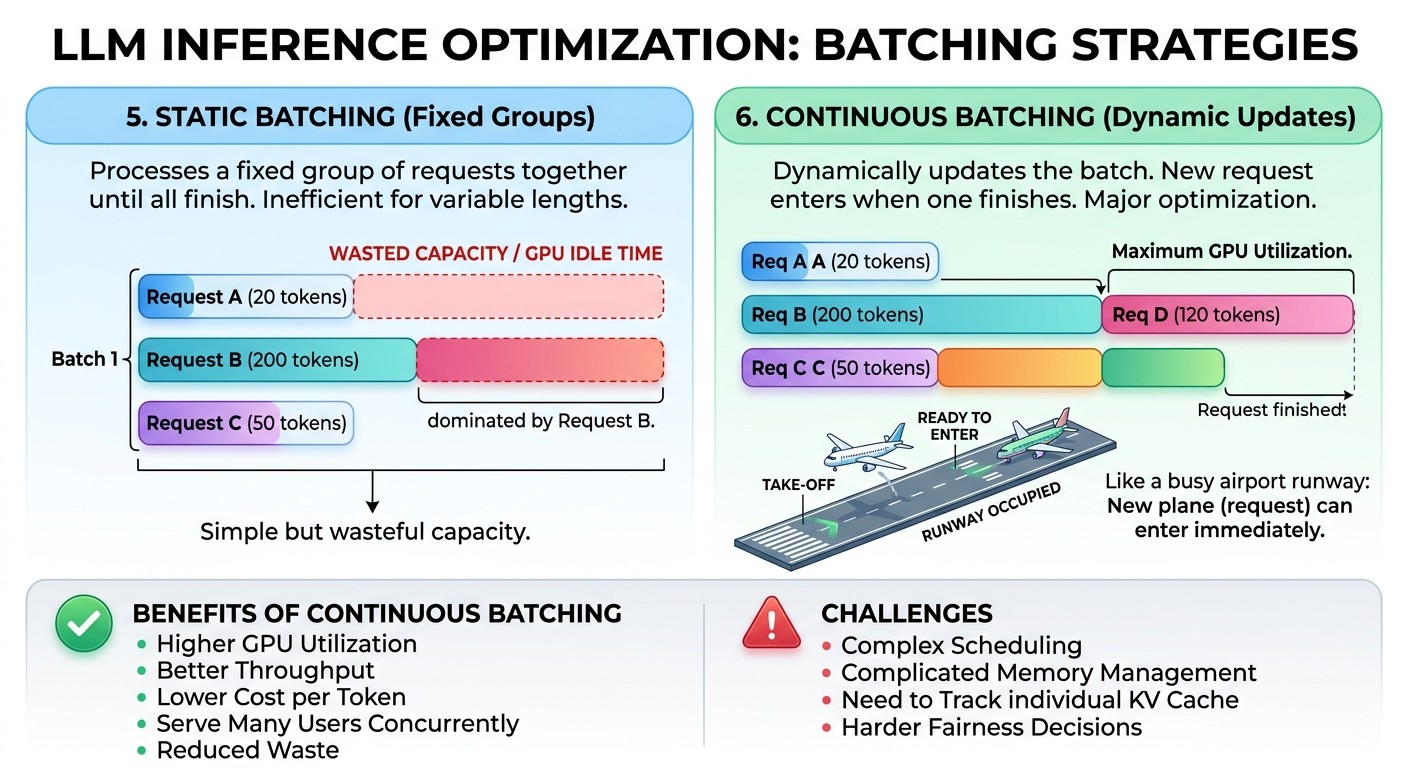
5. Static Batching vs Dynamic Batching
Batching means processing multiple requests together.
In ordinary deep learning inference, batching is simple: collect several inputs, combine them into a batch, run one forward pass, and return the outputs. For LLMs, batching is harder because generation is sequential and requests finish at different times.
In static batching, a fixed group of requests is processed together until all are finished. This can be inefficient because short requests may complete early but still occupy batch slots while longer requests continue.
For example:
Request A: 20 output tokens
Request B: 200 output tokens
Request C: 50 output tokens
If these are grouped statically, Request A finishes quickly, but the batch may still be dominated by Request B. GPU resources are not used efficiently.
Static batching is simple, but it can waste capacity.
6. Continuous Batching
Continuous batching is a major optimization in LLM serving.
Instead of waiting for an entire batch to finish, the serving system updates the batch dynamically. When one request finishes, a new request can enter. This keeps the GPU busy and improves throughput.
A serving system using continuous batching behaves like a well-managed airport runway. As soon as one plane takes off, another is scheduled. The runway is rarely idle.
Benefits of continuous batching
- Higher GPU utilization
- Better throughput
- Lower cost per token
- Ability to serve many users concurrently
- Reduced waste from short requests finishing early
Challenges of continuous batching
- More complex scheduling
- More complicated memory management
- Need to track each request’s KV cache separately
- Harder fairness decisions between short and long requests
Continuous batching is especially important because LLM outputs have variable length. A serving system cannot assume that all users will generate the same number of tokens. Some requests finish after a sentence; others generate essays, code, or reports. Excellent individualised mentoring programmes available.
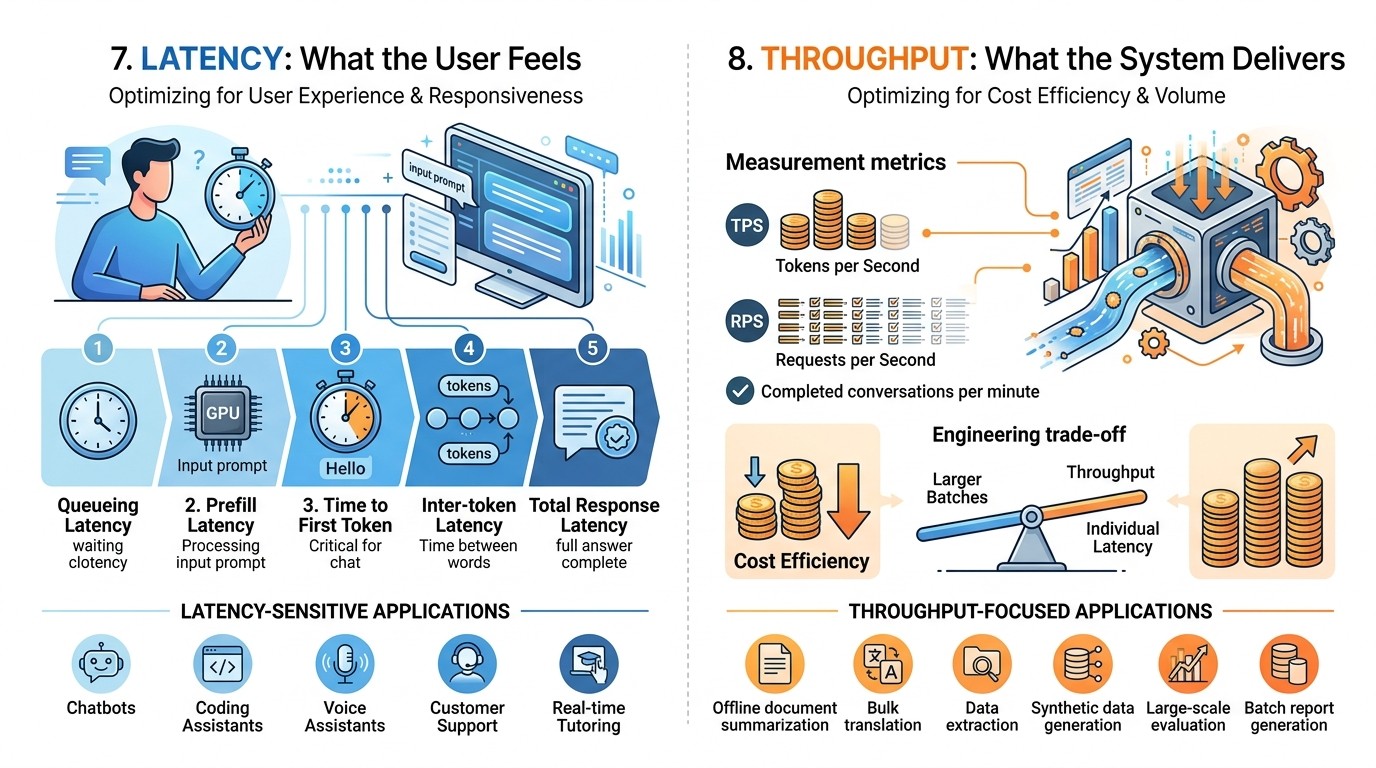
7. Latency: What the User Feels
Latency is the time a user waits.
In LLM applications, latency has multiple parts:
- Queueing latency: time spent waiting before processing begins.
- Prefill latency: time taken to process the input prompt.
- Time to first token: time until the first generated token appears.
- Inter-token latency: delay between generated tokens.
- Total response latency: time until the full answer is complete.
For chat applications, time to first token is very important. Users feel the system is responsive if the first token appears quickly, even if the full answer takes longer.
For batch workloads, total completion time may matter more than first-token latency. For example, if a company is summarizing 100,000 documents overnight, throughput matters more than interactive responsiveness.
Latency-sensitive applications include:
- Chatbots
- Coding assistants
- Voice assistants
- Customer support bots
- Real-time tutoring systems
In these systems, optimization should focus on fast first-token response, smooth streaming, and predictable generation speed.
8. Throughput: What the System Delivers
Throughput measures how much work the system completes over time.
In LLM serving, throughput is often measured as:
tokens per second
requests per second
completed conversations per minute
Throughput is important for cost efficiency. If one GPU can generate more tokens per second, the cost per user decreases.
However, throughput and latency often conflict. To improve throughput, the system may batch more requests together. But larger batches can increase waiting time for individual users. This creates a central engineering trade-off.
Throughput-focused applications include:
- Offline document summarization
- Bulk translation
- Data extraction from large archives
- Synthetic data generation
- Large-scale evaluation
- Batch report generation
For these tasks, the user may accept slower individual responses if the overall system processes more total work. Subscribe to our free AI newsletter now.
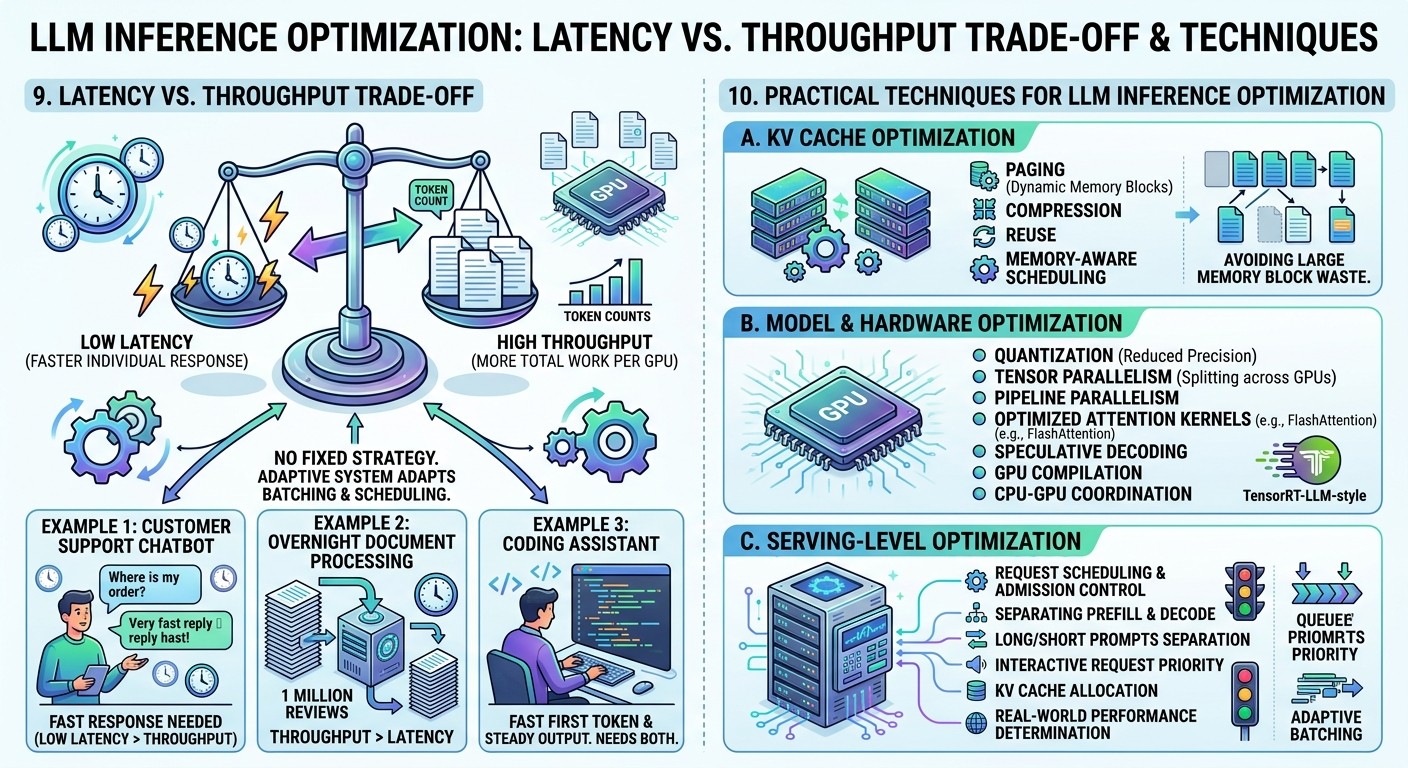
9. Latency vs Throughput Trade-off
The core trade-off in LLM serving is:
Low latency = faster individual response
High throughput = more total work per GPU
You usually cannot maximize both at the same time.
If you serve one request at a time, latency may be low for that request, but GPU utilization may be poor. If you batch many requests together, GPU utilization improves, but some users may wait longer.
The right balance depends on the application.
Example 1: Customer support chatbot
A user asks: “Where is my order?”
The answer should be quick. Low latency matters more than maximum throughput.
Example 2: Overnight document processing
A company wants to summarize 1 million customer reviews.
No one is waiting interactively. Throughput matters more than latency.
Example 3: Coding assistant
The first token should appear quickly, but the system also needs steady output speed. Both latency and throughput matter.
A good serving system does not use one fixed strategy for all workloads. It adapts batching, scheduling, memory allocation, and model configuration based on the use case.
10. Practical Techniques for LLM Inference Optimization
Modern LLM serving systems combine several optimization techniques.
a. KV cache optimization
KV cache can be optimized through paging, compression, reuse, and memory-aware scheduling.
Paged KV cache systems avoid wasting large blocks of memory. Instead of allocating one huge continuous memory region per request, memory can be divided into smaller blocks. This allows better utilization, especially when requests have different lengths.
b. Model and hardware optimization
Common techniques include:
- Quantization
- Tensor parallelism
- Pipeline parallelism
- Optimized attention kernels
- FlashAttention-style kernels
- Speculative decoding
- GPU-specific compilation
- CPU-GPU memory coordination
TensorRT-LLM, for example, provides optimized kernels and runtime optimizations such as speculative decoding and prefill-decode disaggregation for NVIDIA GPUs.
c. Serving-level optimization
The serving layer controls request scheduling, batching, memory allocation, streaming, retries, and admission control.
Key serving decisions include:
- How many requests should be batched together?
- Should long prompts be separated from short prompts?
- Should interactive requests get priority?
- When should the system reject or delay requests?
- How much KV cache should each request receive?
- Should prefill and decode be handled separately?
These decisions often determine real-world performance more than the model architecture itself. Upgrade your AI-readiness with our masterclass.
Conclusion
LLM inference optimization is the engineering discipline that makes large language models usable at scale. A powerful model is not enough. It must be served efficiently, reliably, and economically.
The three central ideas are KV cache, batching, and latency-throughput trade-off.
The KV cache makes token-by-token generation practical by storing previous attention information. But it also creates memory pressure, especially with long contexts and many users. Batching improves GPU utilization, but static batching can waste resources when requests have different output lengths. Continuous batching solves part of this problem by dynamically adding and removing requests during generation.
Latency and throughput represent two competing goals. Latency is what an individual user feels. Throughput is what the system delivers at scale. A chatbot, coding assistant, and offline document processing pipeline may all use the same LLM, but they need different serving strategies.
The future of LLM systems will not be shaped only by bigger models. It will also be shaped by better inference engines, smarter schedulers, memory-efficient KV cache designs, quantization, optimized kernels, and workload-aware serving systems.
In simple terms:
Training creates the model.
Inference serving makes the model useful.
Optimization makes the model affordable.
For anyone building AI products, understanding LLM inference optimization is no longer optional. It is one of the most important skills for turning a model into a scalable real-world system.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



