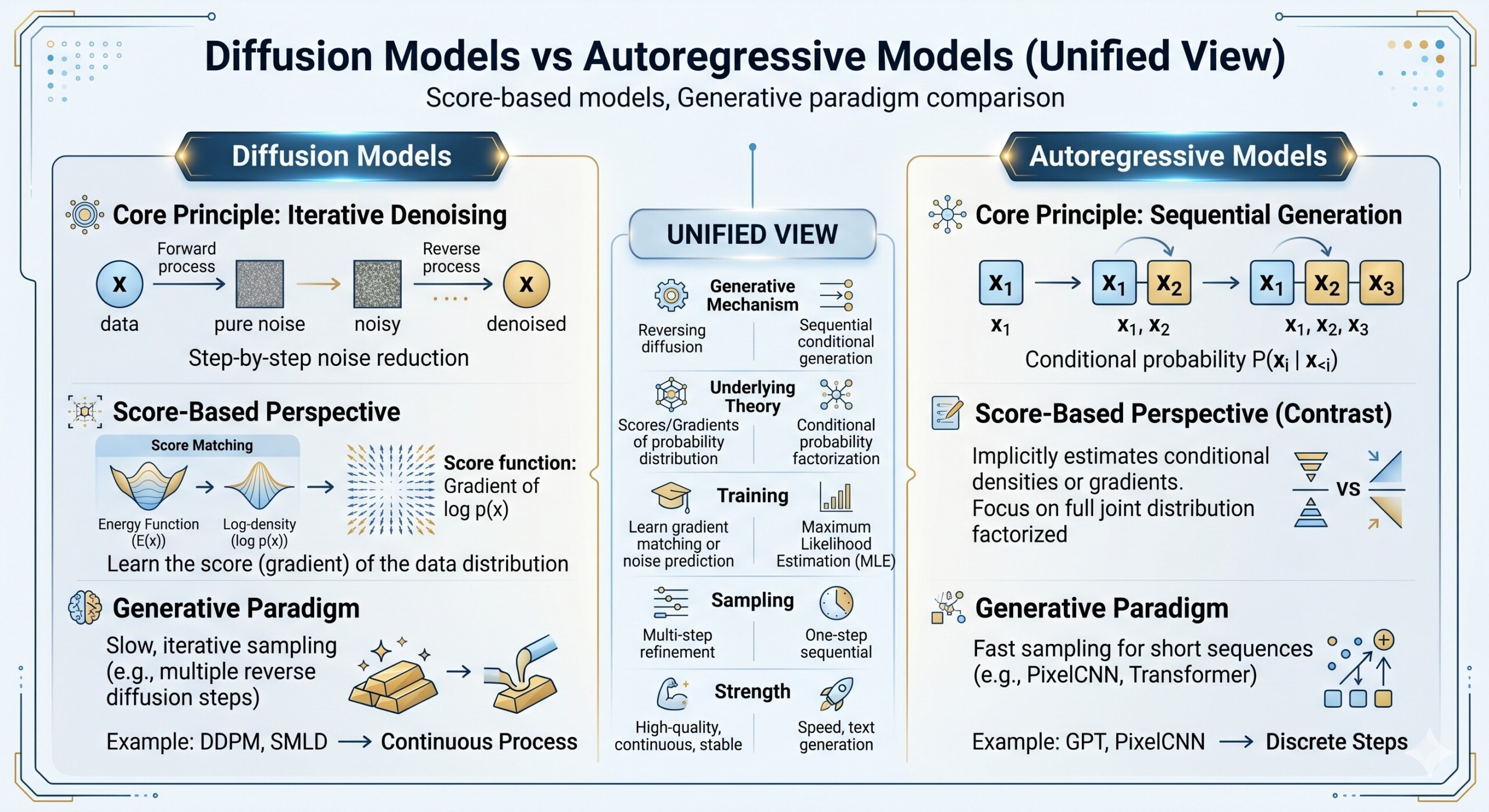
Diffusion Models vs Autoregressive Models (Unified View)

Diffusion Models vs Autoregressive Models (Unified View)
Score-based models, Generative paradigm comparison
Introduction
Generative AI in 2026 is no longer a story of one winning model family. It is a story of different ways to factor, transform, or reverse the probability distribution of data. Autoregressive models, diffusion models, score-based models, flow-matching models, and hybrid systems are now part of a broader generative toolbox.
Autoregressive models became dominant in language because they model generation as a sequence: predict the next token, then the next, then the next. This is the principle behind GPT-style language models and many multimodal transformers. Diffusion models became dominant in image, audio, and video generation because they learn to reverse a gradual noising process, turning random noise into structured data. Score-based generative modeling provides a mathematical bridge: instead of directly predicting data, the model learns the score, meaning the gradient of the log probability density, which tells the model how to move noisy samples toward more likely data. Song et al.’s SDE framework formally unified score-based generative modeling and diffusion probabilistic modeling through reverse-time stochastic differential equations.
By 2026, the boundary between the two paradigms has become less rigid. Diffusion is being explored for text and code generation, such as Google DeepMind’s experimental Gemini Diffusion, while autoregressive models are being pushed into image generation through visual autoregressive methods such as VAR, which uses coarse-to-fine next-scale prediction rather than simple raster-scan pixel prediction.
The right question, therefore, is not simply “Which is better?” A more useful lecture question is: What distributional assumption, ordering strategy, sampling method, and compute trade-off does each paradigm make?
Let’s dive deep into the topic now.
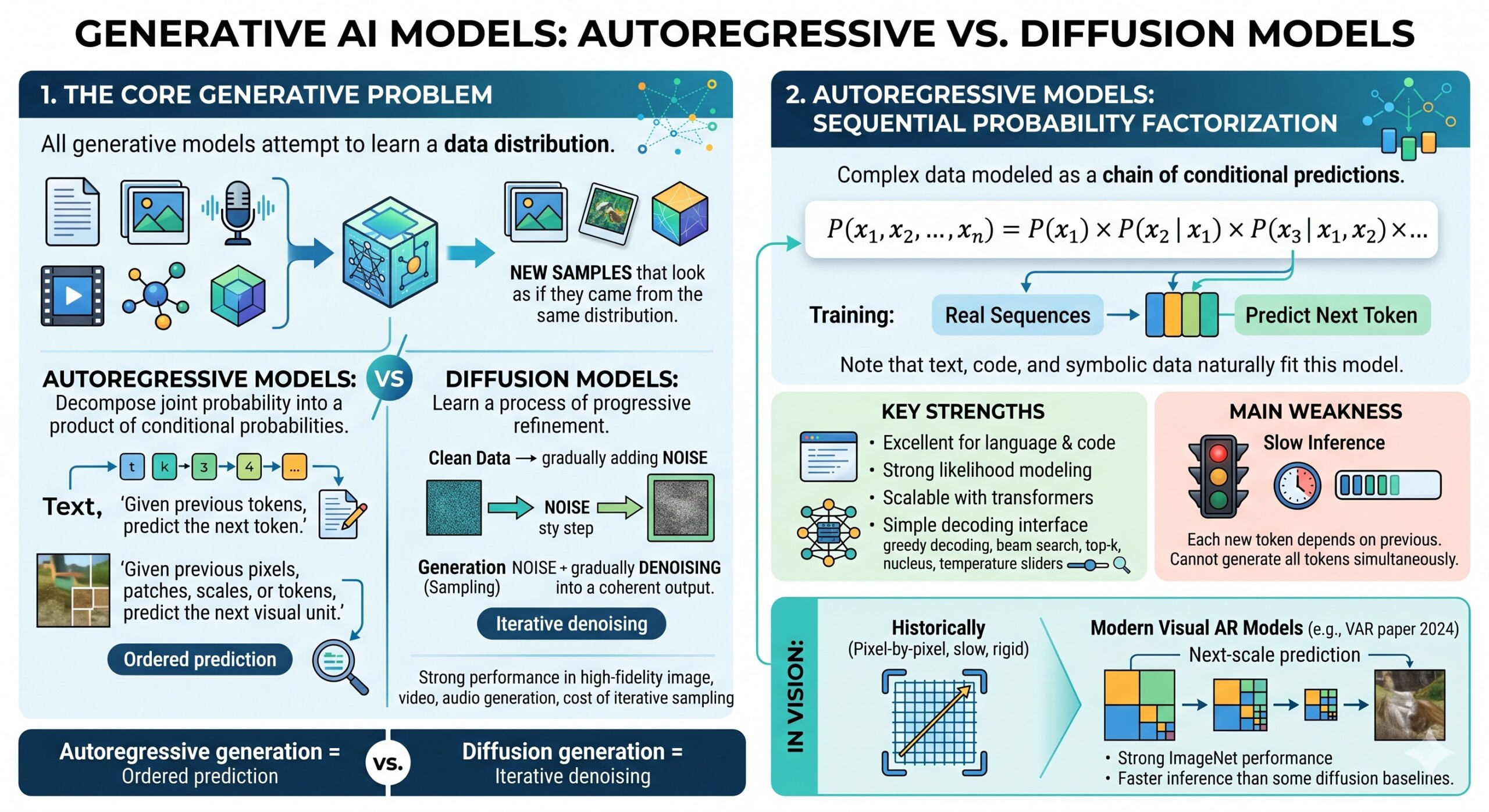
1. The Core Generative Problem
All generative models attempt to learn a data distribution. Given examples of text, images, audio, video, molecules, or 3D objects, the model learns how to produce new samples that look as if they came from the same distribution.
Autoregressive models do this by decomposing the joint probability into a product of conditional probabilities:
Data is generated one unit at a time.
For a text sequence, this means:
Given previous tokens, predict the next token.
For an image, it could mean:
Given previous pixels, patches, scales, or tokens, predict the next visual unit.
Diffusion models instead learn a process of progressive refinement. They start with clean data, add noise step by step during training, and then learn how to reverse that process during generation. In sampling, the model starts from noise and gradually denoises it into a coherent output. Surveys of diffusion models describe this as one of the central reasons for their strong performance in high-fidelity image, video, and audio generation, although with the cost of iterative sampling.
So, at the highest level:
Autoregressive generation = ordered prediction.
Diffusion generation = iterative denoising.
2. Autoregressive Models: Sequential Probability Factorization
Autoregressive models are built around a simple but powerful idea: complex data can be modeled as a chain of conditional predictions.
For a sequence of tokens, the model learns:
P(x₁, x₂, …, xₙ) = P(x₁) × P(x₂ | x₁) × P(x₃ | x₁, x₂) × …
This makes training conceptually straightforward. The model is shown real sequences and learns to predict the next token. This is why autoregressive modeling fits naturally with text, code, and symbolic data.
Key strengths:
- Excellent for language and code: Text already has a natural left-to-right or structured order.
- Strong likelihood modeling: Autoregressive models give explicit token probabilities.
- Scalable with transformers: Transformer-based next-token prediction has shown strong scaling behavior in language models.
- Simple decoding interface: The model can generate using greedy decoding, beam search, top-k sampling, nucleus sampling, or temperature control.
The weakness is also obvious: because generation is sequential, inference can be slow for long outputs. Each new token depends on previous tokens, so the system cannot easily generate all tokens independently at once.
In vision, this has historically been a bigger problem. Pixel-by-pixel generation is too slow and too rigid. However, modern visual autoregressive models increasingly avoid naive pixel scanning. The 2024 VAR paper reframed image generation as next-scale prediction, moving from coarse structure to finer detail, and reported strong ImageNet performance and faster inference compared with some diffusion baselines. An excellent collection of learning videos awaits you on our Youtube channel.
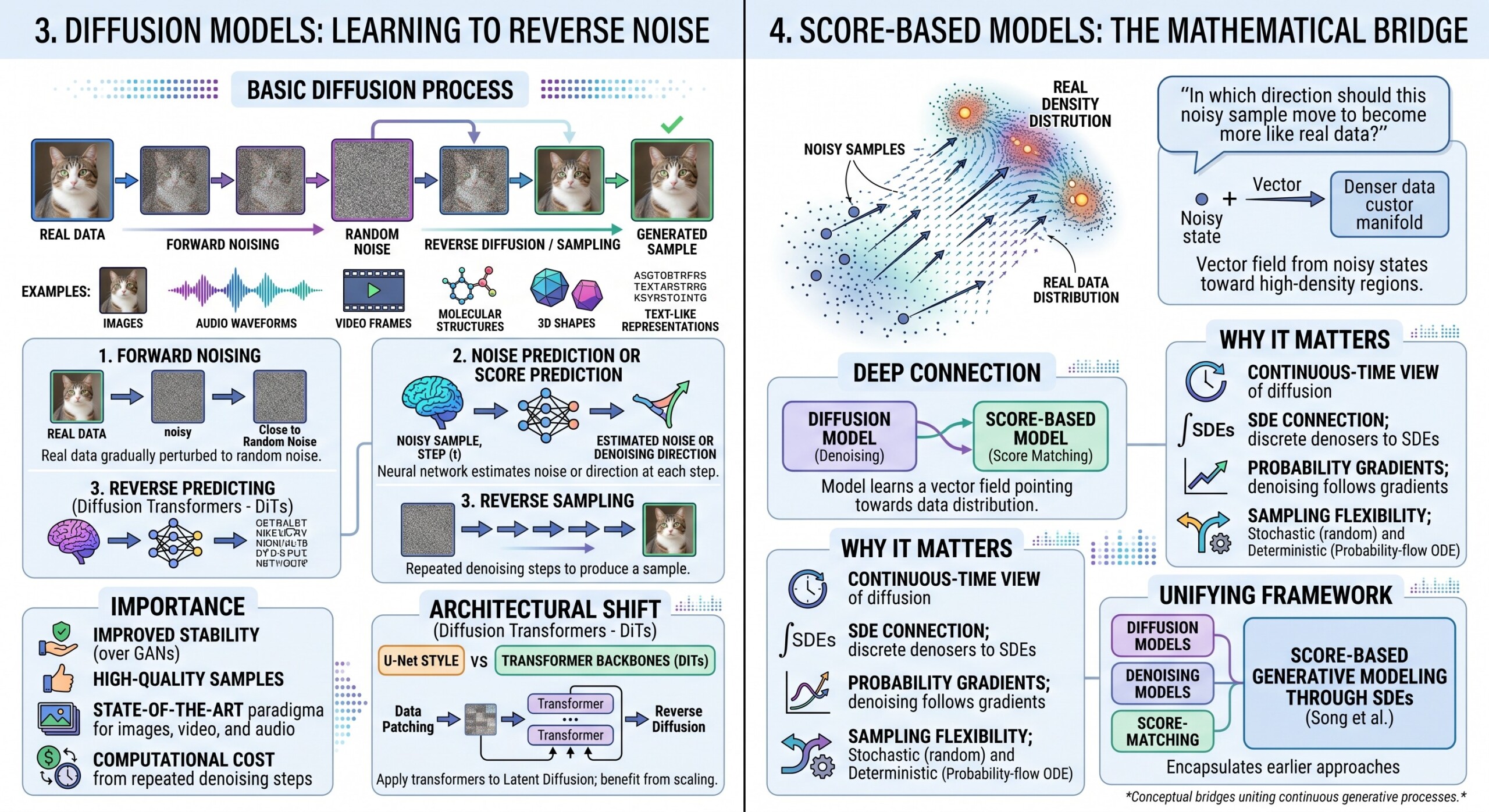
3. Diffusion Models: Learning to Reverse Noise
Diffusion models begin with a forward process that slowly corrupts real data with noise. During training, the model learns how to remove that noise. During generation, the model starts with random noise and repeatedly denoises until a sample appears.
This is why diffusion models are so intuitive for images. A noisy image can be gradually refined into a clean picture. The same idea can be applied to audio waveforms, video frames, molecular structures, 3D shapes, and even text-like representations.
The basic diffusion process has three conceptual stages:
- Forward noising: Real data is gradually perturbed until it becomes close to random noise.
- Noise prediction or score prediction: A neural network learns how to estimate the noise or direction of denoising at each step.
- Reverse sampling: The model starts from noise and repeatedly applies denoising steps to produce a sample.
Diffusion models became especially important because they improved stability over GAN-style training and produced high-quality samples in media domains. The 2026 survey literature still describes diffusion models as a major state-of-the-art paradigm for images, video, and audio, while also emphasizing their computational cost from repeated denoising steps.
A major architectural shift was the rise of Diffusion Transformers, or DiTs. Instead of using only U-Net-style architectures, DiT models apply transformer backbones to latent diffusion, showing that diffusion models can also benefit from transformer scaling principles.
4. Score-Based Models: The Mathematical Bridge
Score-based generative modeling focuses on estimating the score function:
the gradient of the log probability density of the data distribution.
In simple terms, the score tells us:
“In which direction should this noisy sample move to become more like real data?”
This creates a deep connection between diffusion models and score matching. Instead of directly predicting a clean sample, the model learns a vector field that points from noisy states toward high-density regions of the data distribution.
Why score-based modeling matters:
- It provides a continuous-time view of diffusion.
- It connects discrete denoising diffusion models with stochastic differential equations.
- It explains why denoising can be interpreted as following probability gradients.
- It allows both stochastic sampling and deterministic probability-flow ODE sampling.
Song et al. showed that score-based generative modeling through SDEs can encapsulate earlier diffusion and score-matching approaches, making it one of the most important unifying frameworks for modern diffusion theory.
This is why the subtitle of this lecture is important. Score-based models are not merely another category; they are one of the conceptual bridges that help us see diffusion models, denoising models, and continuous generative processes as part of one family. A constantly updated Whatsapp channel awaits your participation.
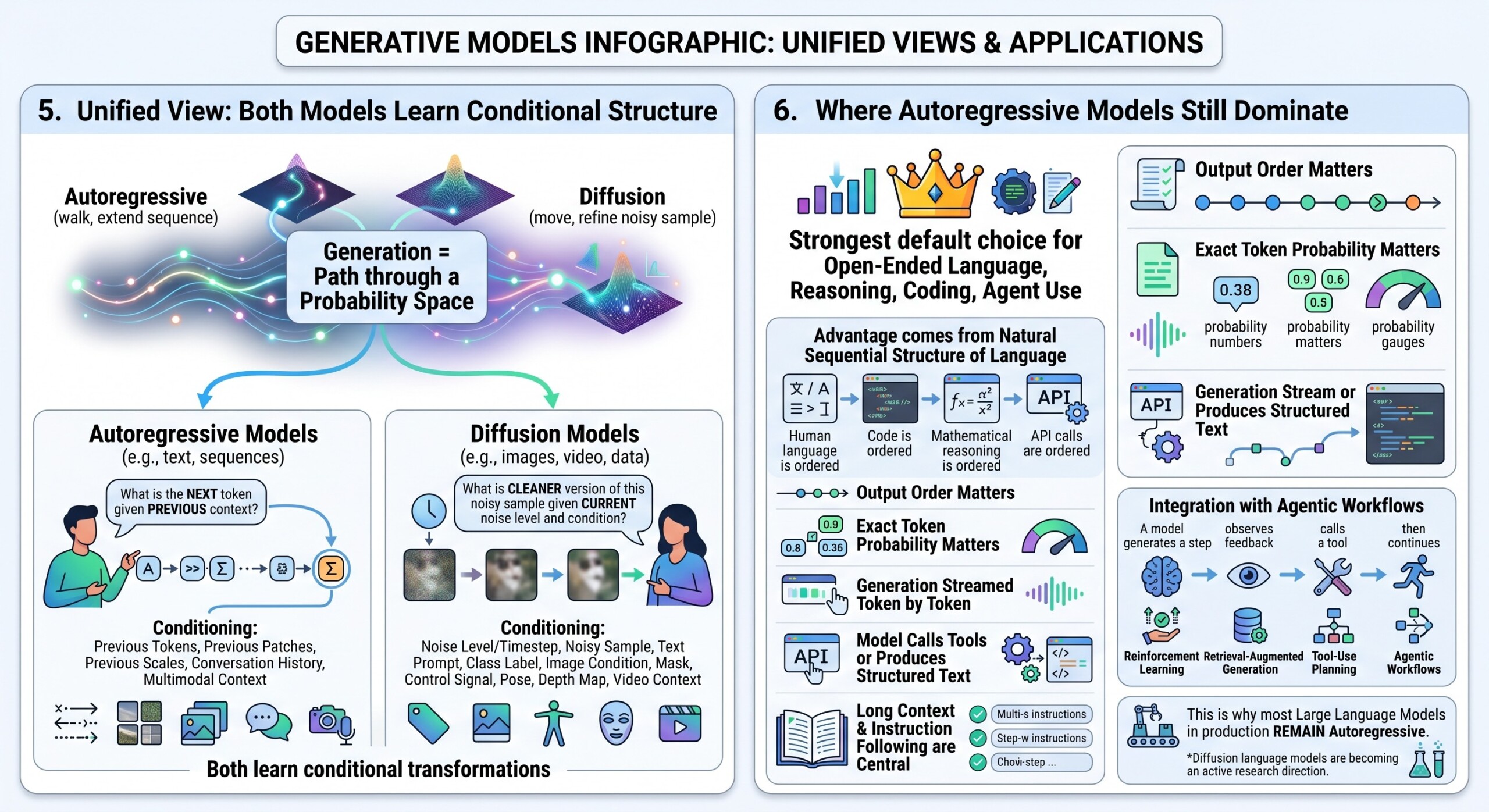
5. Unified View: Both Models Learn Conditional Structure
Although autoregressive and diffusion models look very different, both can be understood as learning conditional transformations.
Autoregressive models ask:
What is the next token given the previous context?
Diffusion models ask:
What is the cleaner version of this noisy sample given its current noise level and condition?
In both cases, the model learns a conditional distribution. The difference lies in what is being conditioned on.
Autoregressive conditioning:
- previous tokens,
- previous patches,
- previous scales,
- conversation history,
- multimodal context.
Diffusion conditioning:
- noise level or timestep,
- noisy sample,
- text prompt,
- class label,
- image condition,
- mask, control signal, pose, depth map, or video context.
The unified view is this:
generation is a path through a probability space.
Autoregressive models walk through that space by extending a sequence. Diffusion models move through that space by refining a noisy sample.
6. Where Autoregressive Models Still Dominate
Autoregressive models remain the strongest default choice for open-ended language generation, reasoning traces, coding, tool use, dialogue, agents, and structured symbolic output.
Their advantage comes from the natural sequential structure of language. Human language is ordered; code is ordered; mathematical reasoning is ordered; API calls are ordered. Autoregressive decoding fits this structure well.
Autoregressive models are especially strong when:
- output order matters,
- exact token probability matters,
- generation must be streamed token by token,
- the model must call tools or produce structured text,
- long context and instruction following are central.
They also integrate well with reinforcement learning, retrieval-augmented generation, tool-use planning, and agentic workflows. A model can generate a step, observe feedback, call a tool, then continue. Diffusion models can do some of this, but autoregressive systems currently provide the cleaner interface for interactive reasoning and tool orchestration.
This is why most large language models in production remain autoregressive or autoregressive-like, even though diffusion language models are becoming an active research direction. Excellent individualised mentoring programmes available.
7. Where Diffusion Models Still Dominate
Diffusion models remain extremely strong in domains where outputs are dense, continuous, perceptual, and globally structured: images, video, audio, 3D, design, and scientific structures.
Their strength comes from iterative global refinement. An image is not naturally a one-dimensional sentence. A face, landscape, or product design involves global composition, texture, lighting, symmetry, and fine detail. Diffusion models can revise the whole sample repeatedly, making them especially suitable for perceptual generation.
Diffusion models are especially strong when:
- global coherence matters,
- visual fidelity is important,
- generation benefits from iterative refinement,
- conditioning is spatial or multimodal,
- editing, inpainting, outpainting, and style control are needed.
Text-to-image controllability has become a major research area, with surveys covering methods such as prompt conditioning, layout control, structural guidance, image editing, and multimodal conditioning.
However, diffusion’s historical weakness has been speed. Traditional diffusion samplers may need many denoising steps. Recent work has tried to reduce this through distillation, consistency models, faster samplers, rectified flows, and flow matching. A 2026 MIT tutorial frames diffusion and flow-based models through ODEs and SDEs, reflecting how the field is converging on continuous generative dynamics rather than treating every model family as separate.
8. Flow Matching and the 2026 Generative Landscape
By 2026, the diffusion-vs-autoregressive discussion must include flow matching. Flow matching learns a vector field that transports samples from a simple distribution, such as noise, to the data distribution. It is closely related to diffusion, but often framed through deterministic or continuous transport dynamics.
Meta’s 2024 flow-matching guide describes flow matching as a framework that has achieved strong performance across image, video, audio, speech, and biological-structure generation, while providing a review of its mathematical foundations and design choices.
This matters because the modern landscape is becoming less about labels and more about paths:
- Autoregressive models define a path through token order.
- Diffusion models define a path from noise to data through denoising.
- Score-based models define a path through probability gradients.
- Flow-matching models define a path through learned transport fields.
The unifying question is:
What trajectory does the model learn from a simple state to a meaningful data sample?
This is why many frontier systems are hybrid. A system may use an autoregressive language model for planning, a diffusion or flow model for image/video generation, a vision encoder for perception, and a separate reward or preference model for alignment. Subscribe to our free AI newsletter now.
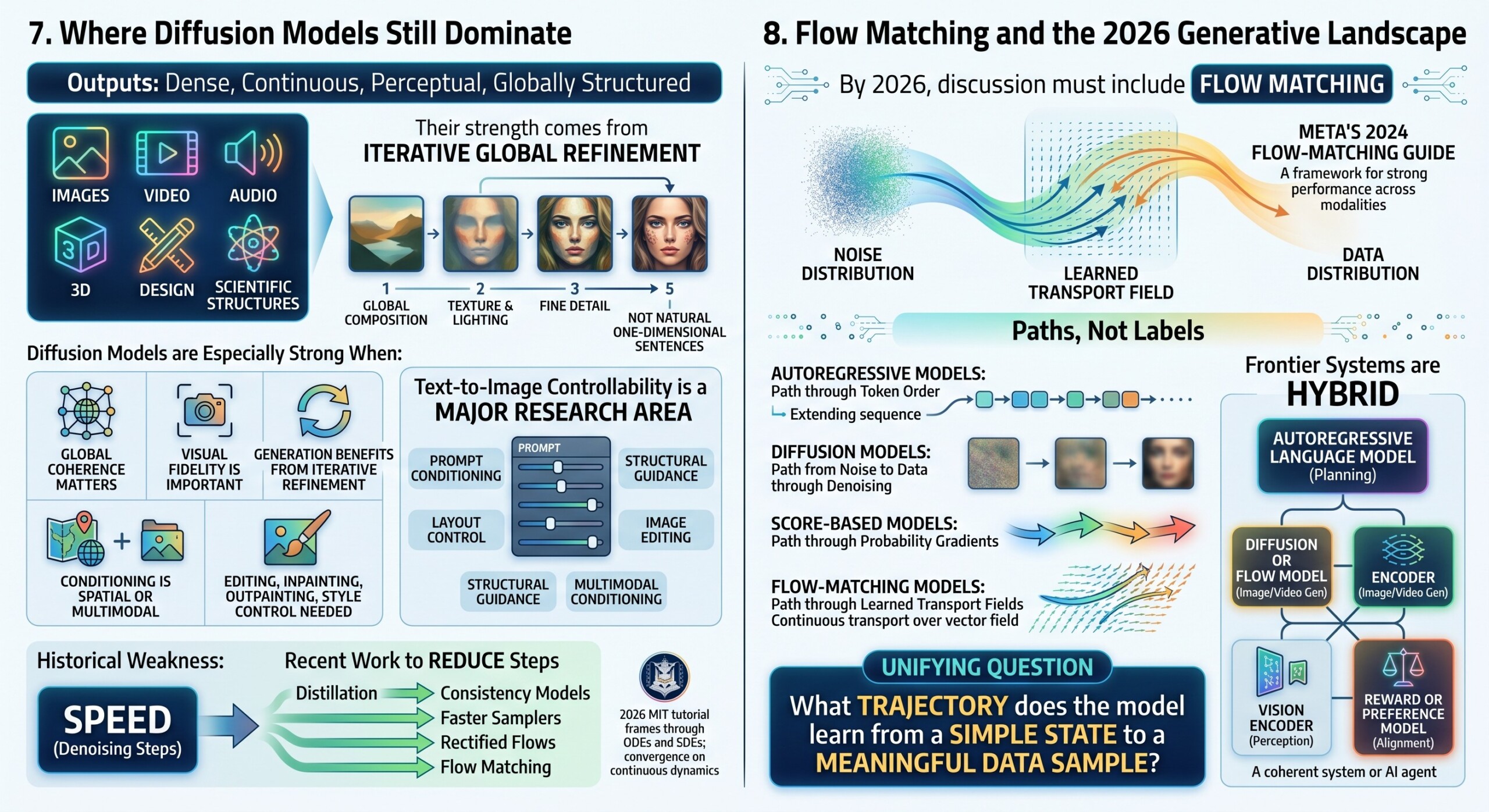
9. Diffusion for Text and Autoregression for Vision
One of the most important 2025–2026 developments is the crossing of boundaries.
Diffusion is no longer only for images. Google DeepMind’s Gemini Diffusion is an experimental text diffusion model that generates text or code by converting random noise into coherent output, borrowing ideas from image and video diffusion. Google describes it as exploring a new kind of language model with greater control, creativity, and speed in text generation.
At the same time, autoregressive models are no longer only for text. Vision autoregressive models now generate images using tokens, patches, or scales. VAR is a major example because it replaces next-token raster prediction with next-scale prediction and argues that GPT-style autoregressive models can compete with or surpass diffusion transformers on some image-generation benchmarks.
This gives us a powerful 2026 insight:
- Text can be diffused.
- Images can be autoregressed.
- Transformers can be used inside diffusion models.
- Denoising can be formulated with score functions, flows, or transport fields.
- Future systems may combine all of these instead of choosing only one.
This is why the lecture title says “Unified View.”
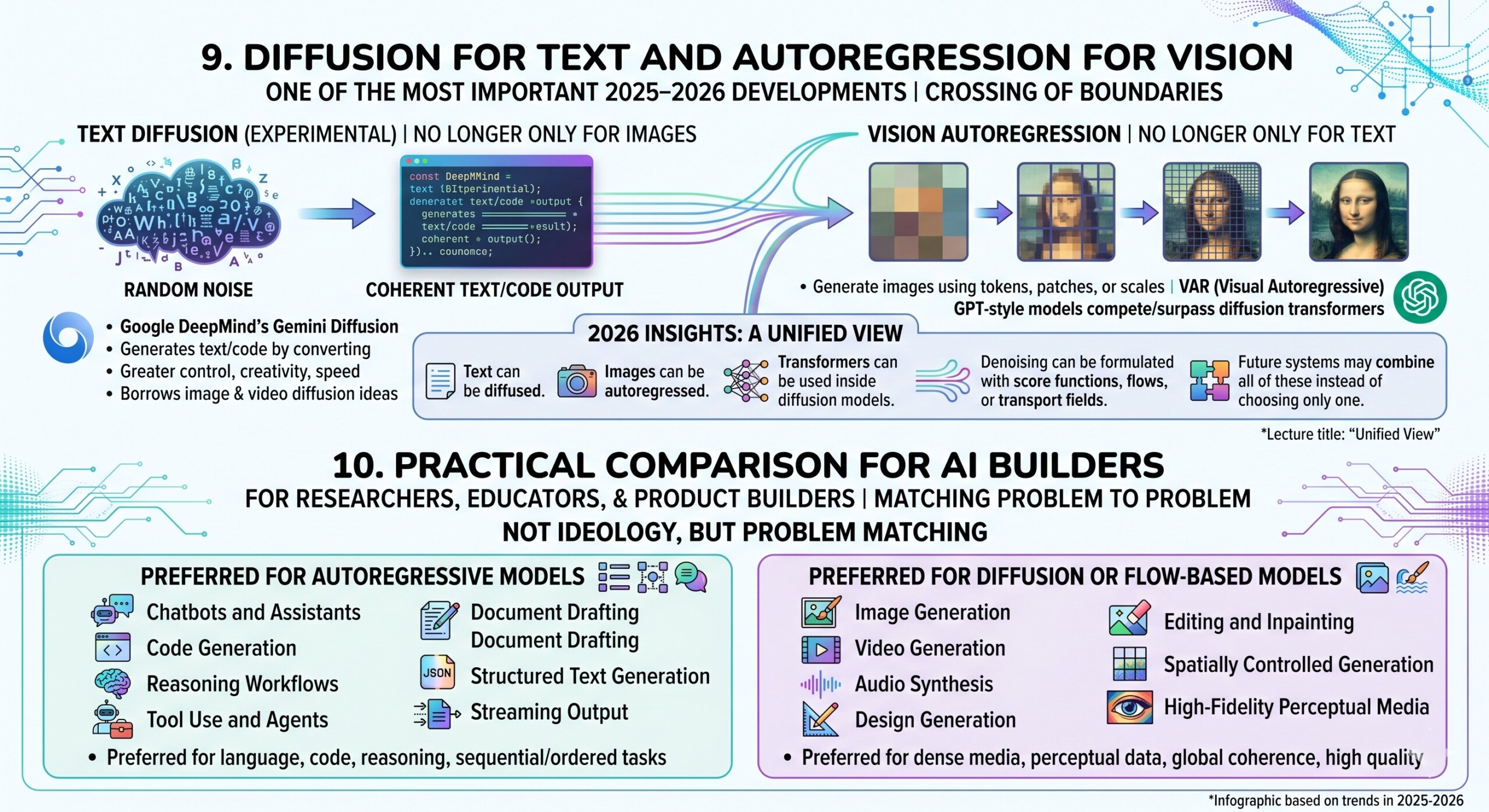
10. Practical Comparison for AI Builders
For researchers, educators, and product builders, the key issue is not ideology. It is matching the model family to the problem.
Autoregressive models are usually preferred for:
- chatbots and assistants,
- code generation,
- reasoning workflows,
- tool use and agents,
- document drafting,
- structured text generation,
- streaming output.
Diffusion or flow-based models are usually preferred for:
- image generation,
- video generation,
- audio synthesis,
- design generation,
- editing and inpainting,
- spatially controlled generation,
- high-fidelity perceptual media.
Important trade-offs
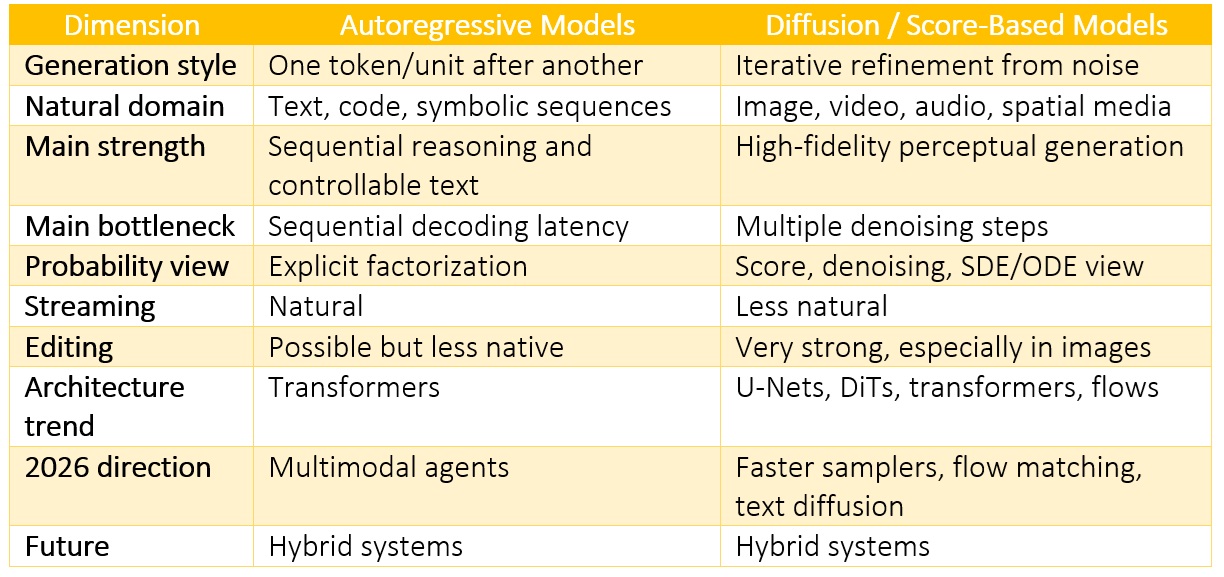
The most accurate 2026 position is that autoregressive models and diffusion models are converging through architecture, conditioning, and multimodal integration, even while their sampling procedures remain different. Upgrade your AI-readiness with our masterclass.
Conclusion
Diffusion models and autoregressive models represent two great generative traditions.
Autoregressive models generate by ordering: they predict the next unit from the previous ones. This makes them powerful for language, code, reasoning, dialogue, and tool use.
Diffusion models generate by refinement: they transform noise into data through learned denoising steps. This makes them powerful for images, video, audio, design, and other perceptual domains.
Score-based models give us a deeper mathematical view: generation can be understood as moving through a learned probability field. Flow matching extends this view further by treating generation as transport from a simple distribution to the data distribution.
By 2026, the frontier is no longer a simple contest between diffusion and autoregression. Diffusion is entering text. Autoregression is entering high-quality vision. Transformers are used in both. Flow-based methods are reshaping the theory. Hybrid multimodal systems are becoming normal.
The unified view is this:
Generative AI is the science of learning paths from uncertainty to structure.
Autoregressive models walk that path step by step.
Diffusion and score-based models refine that path from noise to meaning.
Future AI systems will use whichever path best serves the task.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



