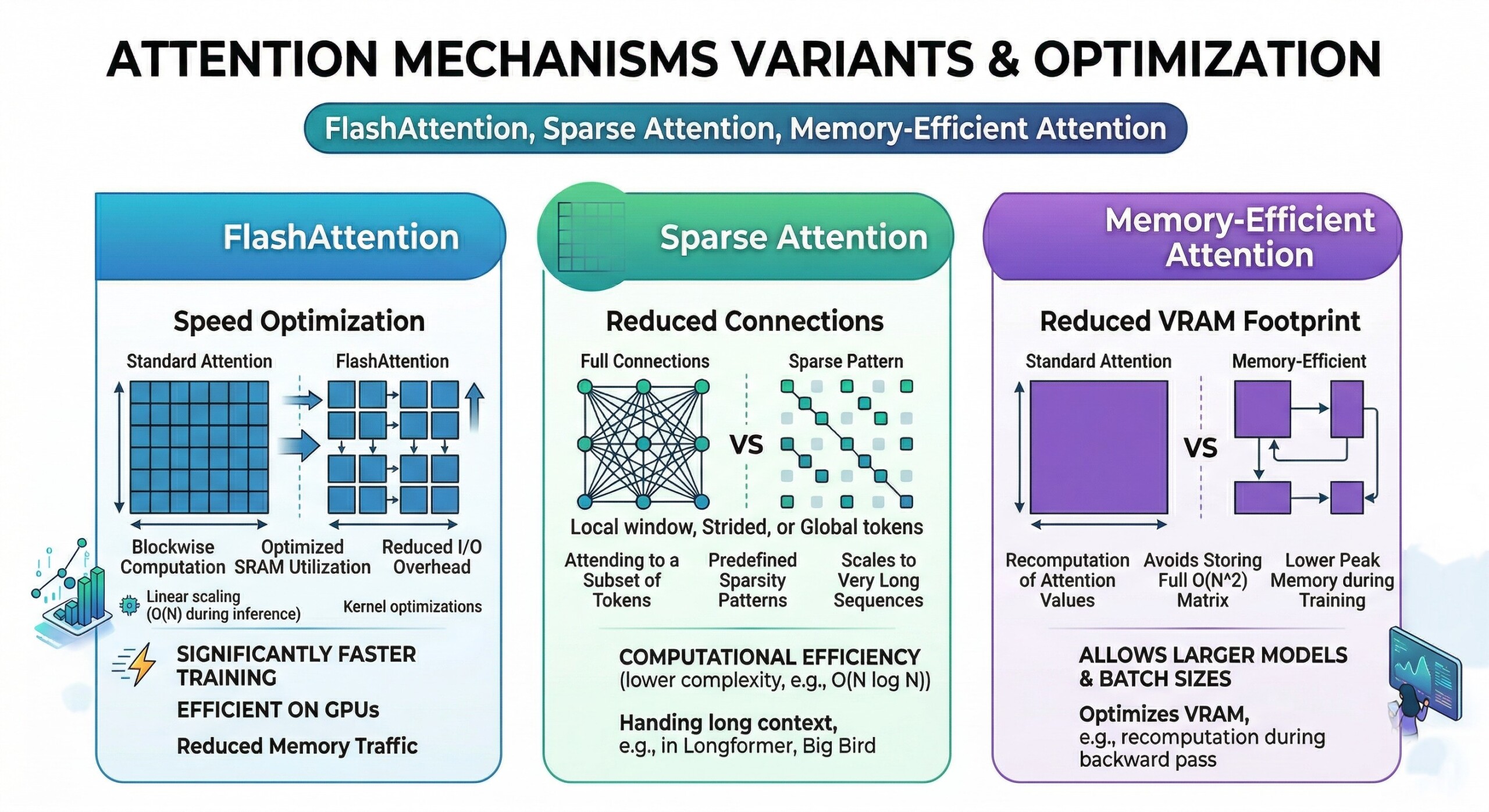
Attention Mechanisms Variants & Optimization

Attention Mechanisms Variants & Optimization
Flash attention, sparse attention, memory-efficient attention
Introduction
The concept of attention mechanisms revolutionized modern AI, particularly after the introduction of the Transformer architecture in the landmark paper Attention Is All You Need. Attention allows models to dynamically focus on relevant parts of input sequences, enabling breakthroughs in natural language processing, computer vision, and multimodal AI.
However, as models scale to billions of parameters and process longer sequences (thousands to millions of tokens), traditional attention mechanisms face severe computational and memory bottlenecks. The quadratic complexity O(n2) in both compute and memory makes naïve attention impractical for large-scale real-world applications like long-document understanding, code generation, and video processing.
To address these challenges, researchers and engineers have developed optimized attention variants such as FlashAttention, sparse attention, and memory-efficient attention. These innovations aim to preserve model performance while drastically reducing computational overhead, enabling faster training, lower memory usage, and scalability to longer contexts.
This lecture explores these variants in depth – covering their principles, trade-offs, and practical implications—while highlighting how they reshape the future of large-scale AI systems.
Let’s dive deep into the topic.
Before diving into specific techniques, it is important to understand the core challenge:
Standard Attention Complexity
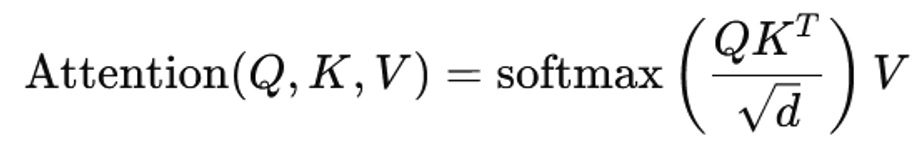
- Time Complexity: O(n2)
- Memory Complexity: O(n2)
- Bottleneck: Storing and computing full attention matrices
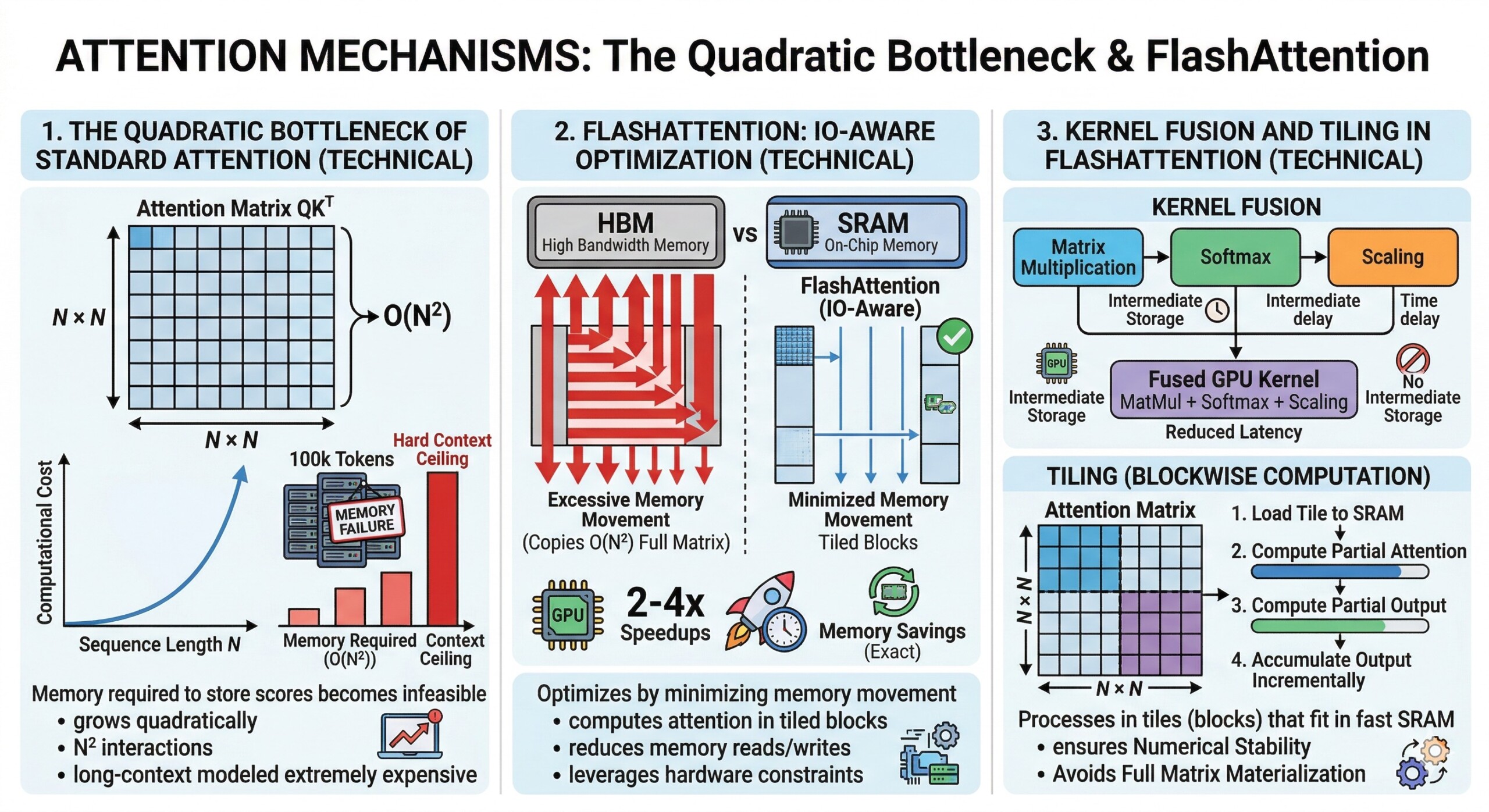
1. The quadratic bottleneck of Standard Attention (Technical)
The primary limitation of vanilla attention lies in the computation of the attention matrix QKT, which grows quadratically with sequence length. For sequences of length nnn, this results in n2 interactions, making long-context modeling extremely expensive.
In practical terms, when dealing with sequences of 100k tokens (common in modern LLMs), the memory required to store attention scores becomes infeasible even on high-end GPUs. This creates a hard ceiling on context length unless optimization strategies are applied.
2. FlashAttention: IO-Aware Optimization (Technical)
FlashAttention is a breakthrough technique that optimizes attention computation by minimizing memory movement between GPU high-bandwidth memory (HBM) and on-chip SRAM. Instead of storing the full attention matrix, it computes attention in tiled blocks.
This approach leverages IO-awareness – a concept where the algorithm is designed around hardware constraints. By reducing memory reads/writes and fusing operations, FlashAttention achieves significant speedups (2–4x) and memory savings without approximation. An excellent collection of learning videos awaits you on our Youtube channel.
3. Kernel Fusion and Tiling in FlashAttention (Technical)
FlashAttention uses kernel fusion, combining multiple operations (matrix multiplication, softmax, scaling) into a single GPU kernel. This avoids intermediate memory storage and reduces latency.
Additionally, it processes attention in tiles (blocks) that fit into fast on-chip memory. Each block computes partial attention scores, normalizes them, and accumulates outputs incrementally, ensuring numerical stability while avoiding full matrix materialization.
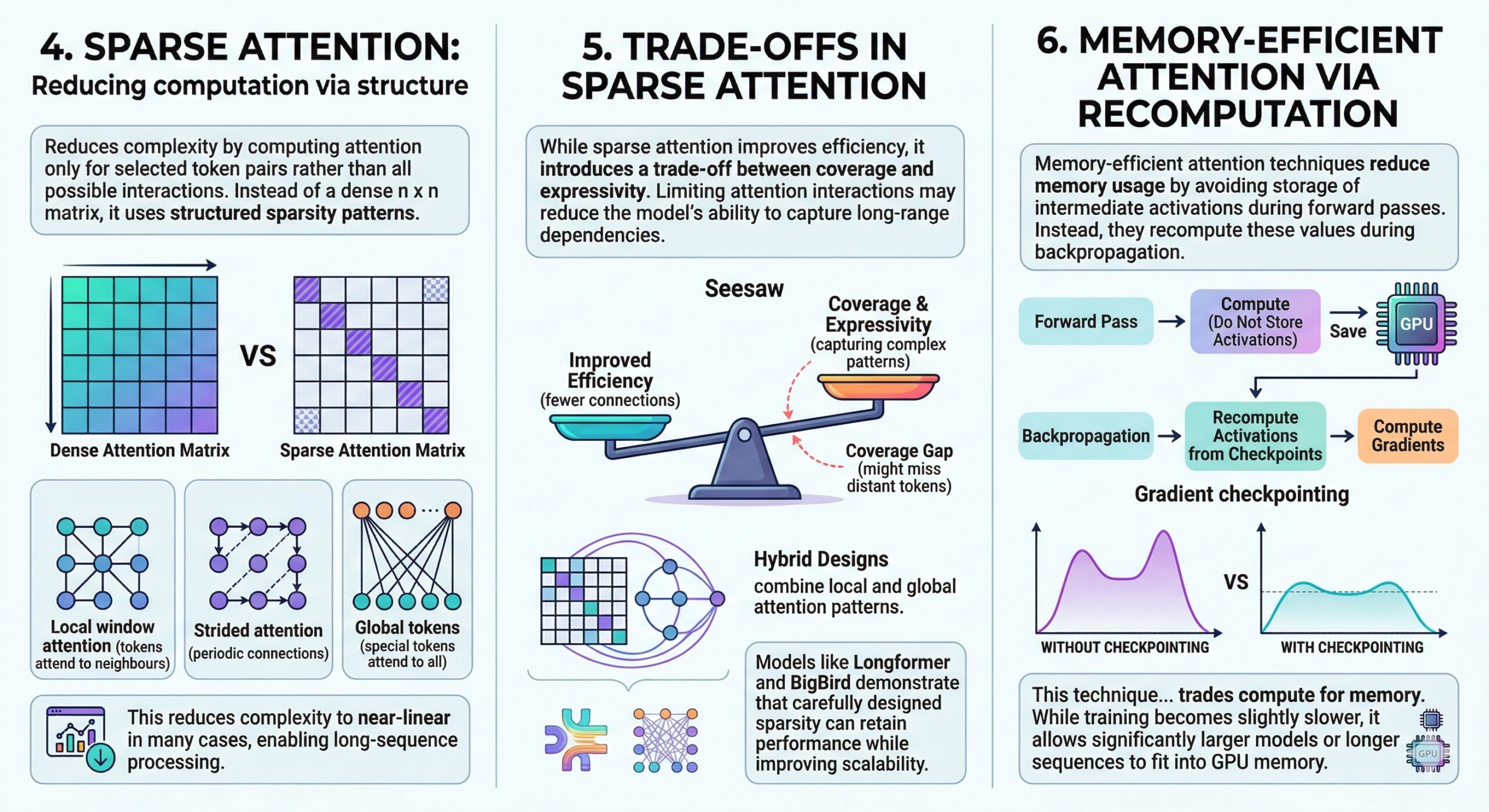
4. Sparse Attention: Reducing computation via structure
Sparse attention reduces complexity by computing attention only for selected token pairs rather than all possible interactions. Instead of a dense n × n matrix, it uses structured sparsity patterns.
Examples include:
- Local window attention (tokens attend to neighbours)
- Strided attention (periodic connections)
- Global tokens (special tokens attend to all)
This reduces complexity to near-linear in many cases, enabling long-sequence processing. A constantly updated Whatsapp channel awaits your participation.
5. Trade-offs in Sparse Attention
While sparse attention improves efficiency, it introduces a trade-off between coverage and expressivity. Limiting attention interactions may reduce the model’s ability to capture long-range dependencies.
To mitigate this, hybrid designs combine local and global attention patterns. Models like Longformer and BigBird demonstrate that carefully designed sparsity can retain performance while improving scalability.
6. Memory-Efficient Attention via recomputation
Memory-efficient attention techniques reduce memory usage by avoiding storage of intermediate activations during forward passes. Instead, they recompute these values during backpropagation.
This technique, often called gradient checkpointing, trades compute for memory. While training becomes slightly slower, it allows significantly larger models or longer sequences to fit into GPU memory. Excellent individualised mentoring programmes available.
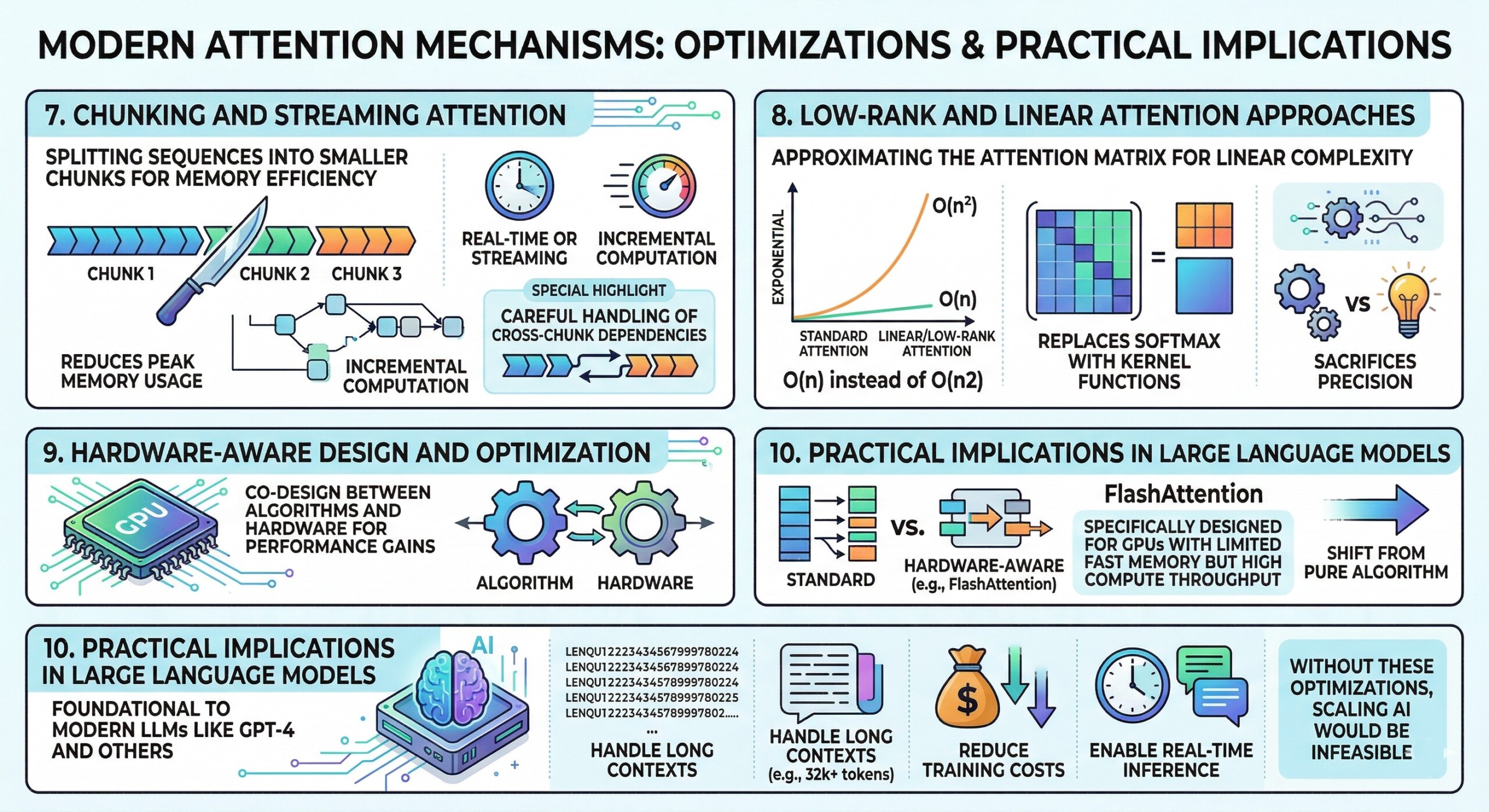
7. Chunking and Streaming Attention
Another approach to memory efficiency is splitting sequences into smaller chunks and computing attention incrementally. This is particularly useful for streaming or real-time applications.
Chunking ensures that only a subset of tokens is processed at a time, reducing peak memory usage. However, it requires careful handling of cross-chunk dependencies to maintain model performance.
8. Low-Rank and Linear Attention approaches
Some attention variants approximate the attention matrix using low-rank factorization or kernel methods, reducing complexity from quadratic to linear.
For instance, linear attention replaces softmax with kernel functions, allowing attention to be computed as:
O(n) instead of O(n2)
While highly efficient, these methods may sacrifice accuracy in tasks requiring precise token interactions. Subscribe to our free AI newsletter now.
9. Hardware-Aware Design and Optimization
Modern attention optimizations are increasingly driven by hardware characteristics. FlashAttention, for example, is specifically designed for GPUs with limited fast memory but high compute throughput.
This marks a shift from purely algorithmic innovation to co-design between algorithms and hardware, where performance gains arise from aligning computation patterns with hardware capabilities.
10. Practical implications in Large Language Models
Attention optimizations are not just theoretical – they are foundational to modern LLMs like GPT-4 and other large-scale systems.
These models rely heavily on efficient attention mechanisms to:
- Handle long contexts (e.g., 32k+ tokens)
- Reduce training costs
- Enable real-time inference
Without these optimizations, scaling AI systems to current levels would be economically and technically infeasible. Upgrade your AI-readiness with our masterclass.
Conclusion
Attention mechanisms are the backbone of modern AI, but their scalability challenges have driven a wave of innovation in optimization techniques. FlashAttention redefines efficiency through IO-aware computation, sparse attention introduces structural efficiency, and memory-efficient methods enable larger models within hardware constraints.
Together, these approaches represent a broader trend: the evolution of AI from purely mathematical models to system-level engineering disciplines. The future of attention mechanisms will likely involve hybrid approaches – combining exact computation, sparsity, approximation, and hardware-aware design.
As AI systems continue to scale, mastering these attention variants is not optional – it is essential. They are the key enablers of next-generation models capable of understanding longer contexts, operating efficiently, and delivering real-world impact at scale.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



