Memory Mechanisms in LLMs

Memory Mechanisms in LLMs
Context windows vs external memory, Retrieval vs compression
Introduction
Large Language Models are often described as intelligent systems that can understand, reason, write, summarize, translate, and converse. But one of the most important questions about them is: how do they remember? The answer is more complex than it first appears.
An LLM does not remember like a human being. It does not naturally carry all past conversations, experiences, and facts inside an active mind. Instead, it works with a limited amount of text at a time. This active text space is called the context window. Whatever is placed inside that window can influence the model’s response. Whatever is outside it usually cannot.
To overcome this limitation, modern AI systems use additional memory mechanisms. Some rely on external memory, where information is stored in databases, files, vector stores, or knowledge bases. Others use retrieval, where the system searches for relevant information and brings it into the prompt. Another approach is compression, where long histories or documents are summarized into shorter forms.
The real challenge is not simply giving an LLM “more memory.” The challenge is deciding what to keep, what to retrieve, what to summarize, and what to ignore. This is where the design of memory mechanisms becomes central to building useful AI systems.
Let’s dive deep into the topic.
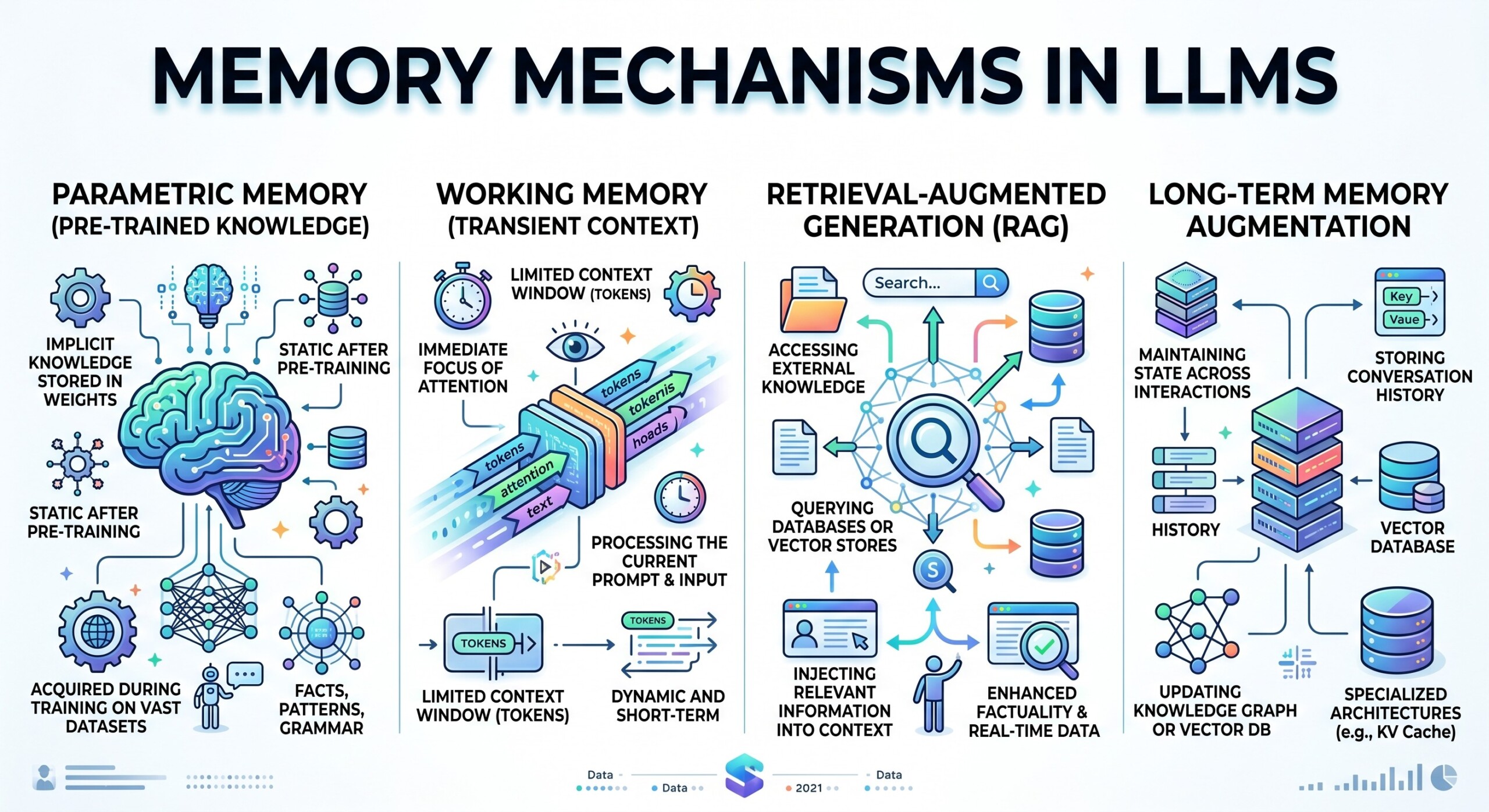
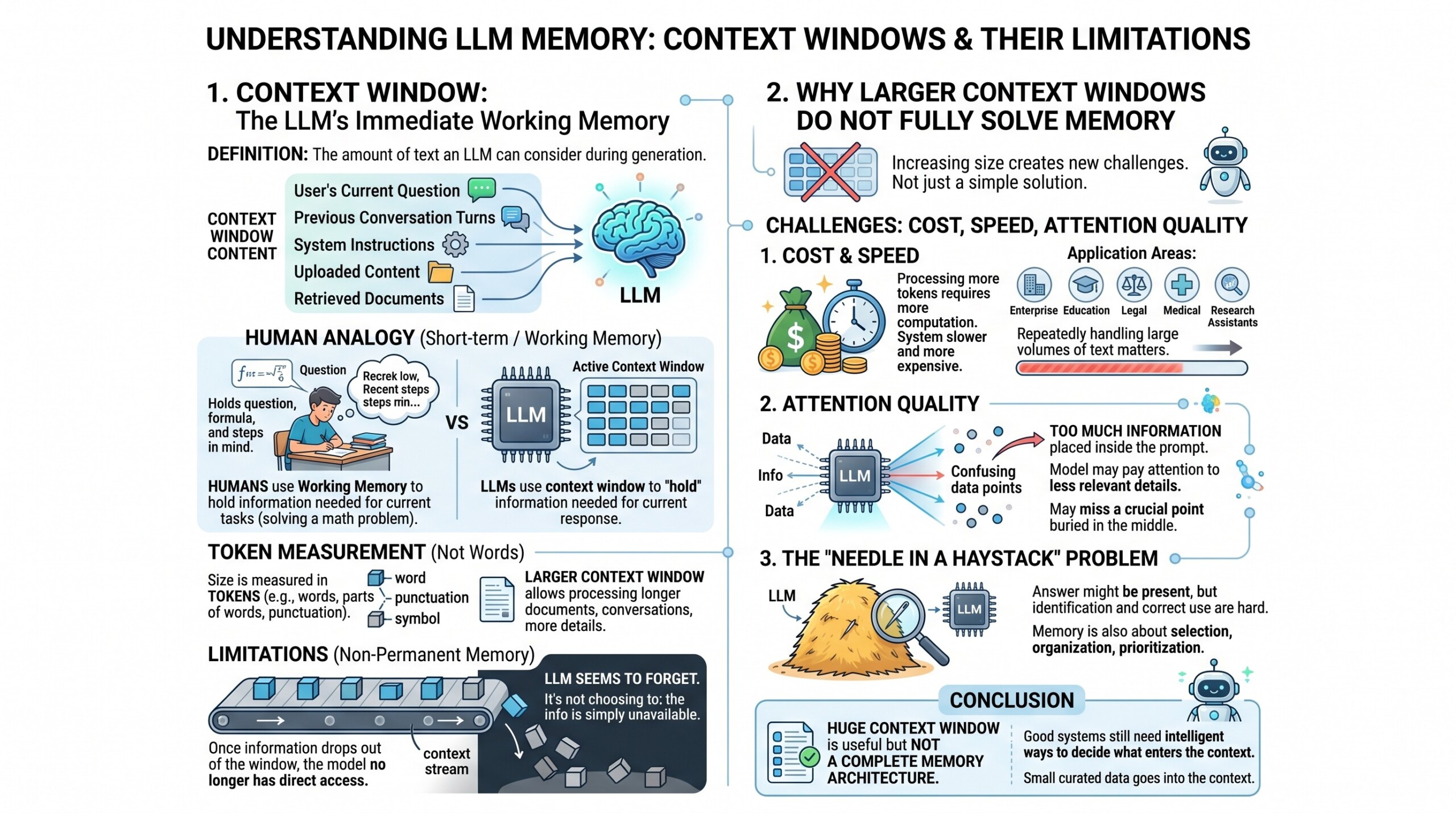
1. Context Window: The LLM’s immediate working memory
The context window is the amount of text an LLM can consider while generating an answer. It includes the user’s current question, previous conversation turns, system instructions, uploaded content, retrieved documents, and any other text inserted into the prompt.
This is similar to short-term or working memory in humans, though the comparison is not perfect. If a student is solving a math problem, they hold the question, formula, and recent steps in their mind. Similarly, an LLM uses the context window to “hold” the information needed for the current response.
The size of the context window is measured in tokens, not words. A token may be a word, part of a word, punctuation mark, or symbol. A larger context window allows the model to process longer documents, longer conversations, and more detailed instructions.
However, the context window is not permanent memory. Once information drops out of the window, the model no longer has direct access to it. This is why an LLM may seem to forget something mentioned earlier in a long conversation. It is not choosing to forget; the information may simply no longer be available in its active context.
2. Why larger Context Windows do not fully solve memory
At first, it may seem that the solution is simple: make context windows bigger. If an LLM can process more text, it should remember more. In practice, the problem is not so easy.
Large context windows create three major challenges: cost, speed, and attention quality. Processing more tokens requires more computation. This can make the system slower and more expensive. For enterprise applications, education platforms, legal analysis, medical documentation, or research assistants, this matters a lot because the system may need to handle large volumes of text repeatedly.
There is also the problem of relevance. Just because a model can read a very long context does not mean it will always focus on the most important part. When too much information is placed inside the prompt, the model may pay attention to less relevant details or miss a crucial point buried in the middle.
This is sometimes called the “needle in a haystack” problem. The answer may be present somewhere in the context, but the model still has to identify and use it correctly. Therefore, memory is not only about size. It is also about selection, organization, and prioritization.
A huge context window is useful, but it is not a complete memory architecture. Good systems still need intelligent ways to decide what enters the context. An excellent collection of learning videos awaits you on our Youtube channel.
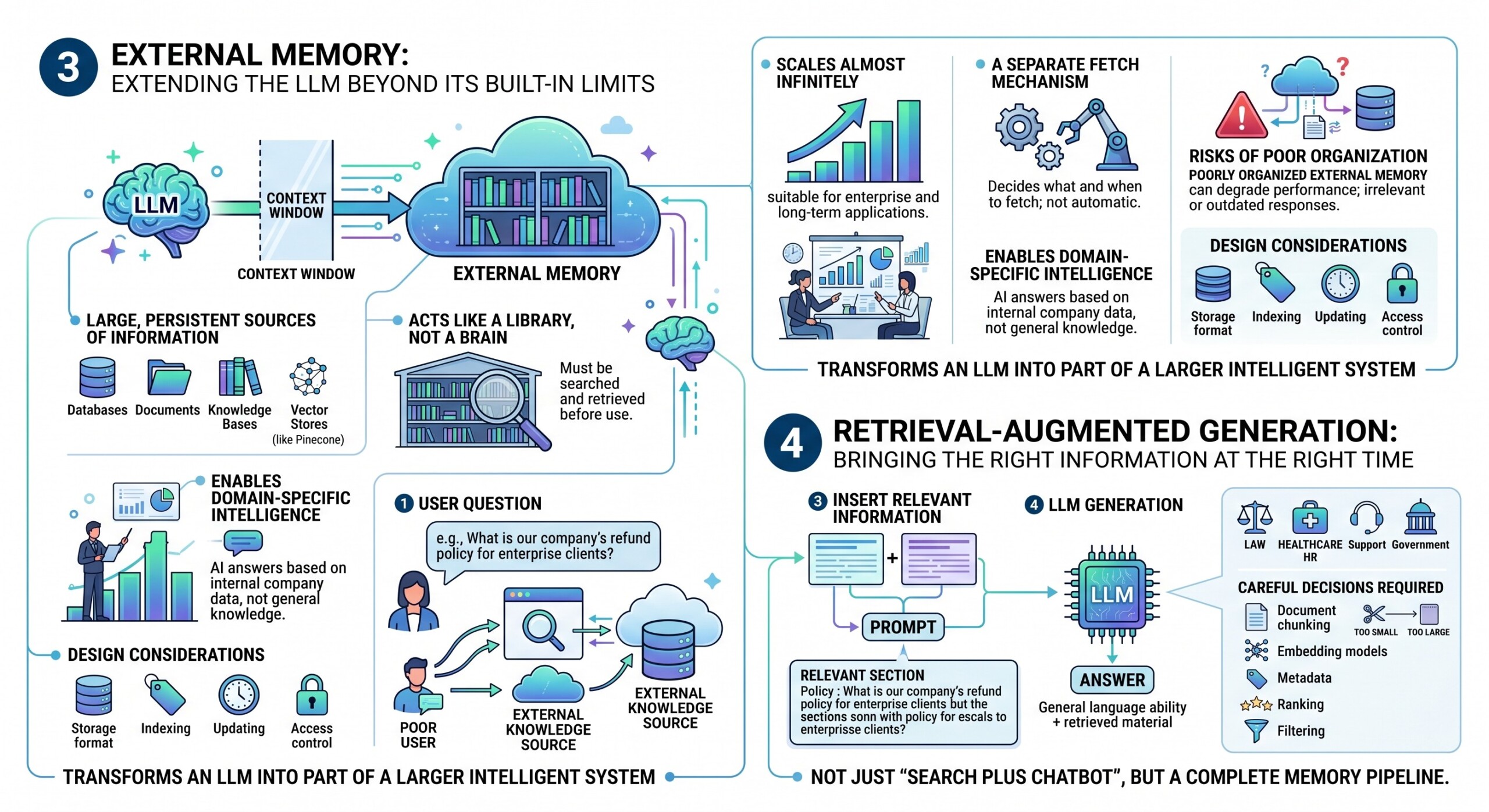
3. External Memory: Extending the LLM beyond its built-in limits
External memory allows an LLM system to go beyond the strict limits of its context window. Instead of relying only on what fits inside a single prompt, the system can access large, persistent sources of information stored outside the model.
- External memory typically includes structured and unstructured sources such as databases, documents, knowledge bases, and vector stores like Pinecone.
- It acts more like a library than a brain – the information exists, but it must be searched and retrieved before use.
- This memory can scale almost infinitely compared to the fixed size of context windows, making it suitable for enterprise and long-term applications.
- It enables domain-specific intelligence, allowing AI systems to answer questions based on internal company data rather than general knowledge.
- However, the LLM does not automatically “know” what is stored externally; a separate mechanism must decide what to fetch and when.
- Poorly organized external memory can degrade performance, leading to irrelevant or outdated responses.
- Designing external memory involves decisions about storage format, indexing, updating, and access control.
In practice, external memory transforms an LLM from a standalone model into part of a larger intelligent system.
4. Retrieval-Augmented Generation: Bringing the right information at the right time
Retrieval-Augmented Generation, commonly called RAG, is one of the most important methods for giving LLMs access to external knowledge. In a RAG system, the user’s question is used to search an external knowledge source. The most relevant pieces of information are retrieved and inserted into the prompt. The LLM then generates an answer using both its general language ability and the retrieved material.
For example, suppose a user asks, “What is our company’s refund policy for enterprise clients?” The model may not know the company’s current refund policy by itself. A retrieval system searches the company’s policy documents, finds the relevant section, and provides it to the LLM. The LLM then answers based on that retrieved text.
The strength of retrieval is that it allows AI systems to use fresh, specific, and private information. This is useful in law, healthcare, finance, education, technical support, HR, and government applications.
However, retrieval is only as good as the search process. If the wrong document is retrieved, the answer may be wrong. If the document chunks are too small, the model may lack context. If they are too large, the prompt becomes crowded. Therefore, RAG requires careful decisions about document chunking, embedding models, metadata, ranking, and filtering.
Retrieval is not just “search plus chatbot.” It is a complete memory pipeline. A constantly updated Whatsapp channel awaits your participation.
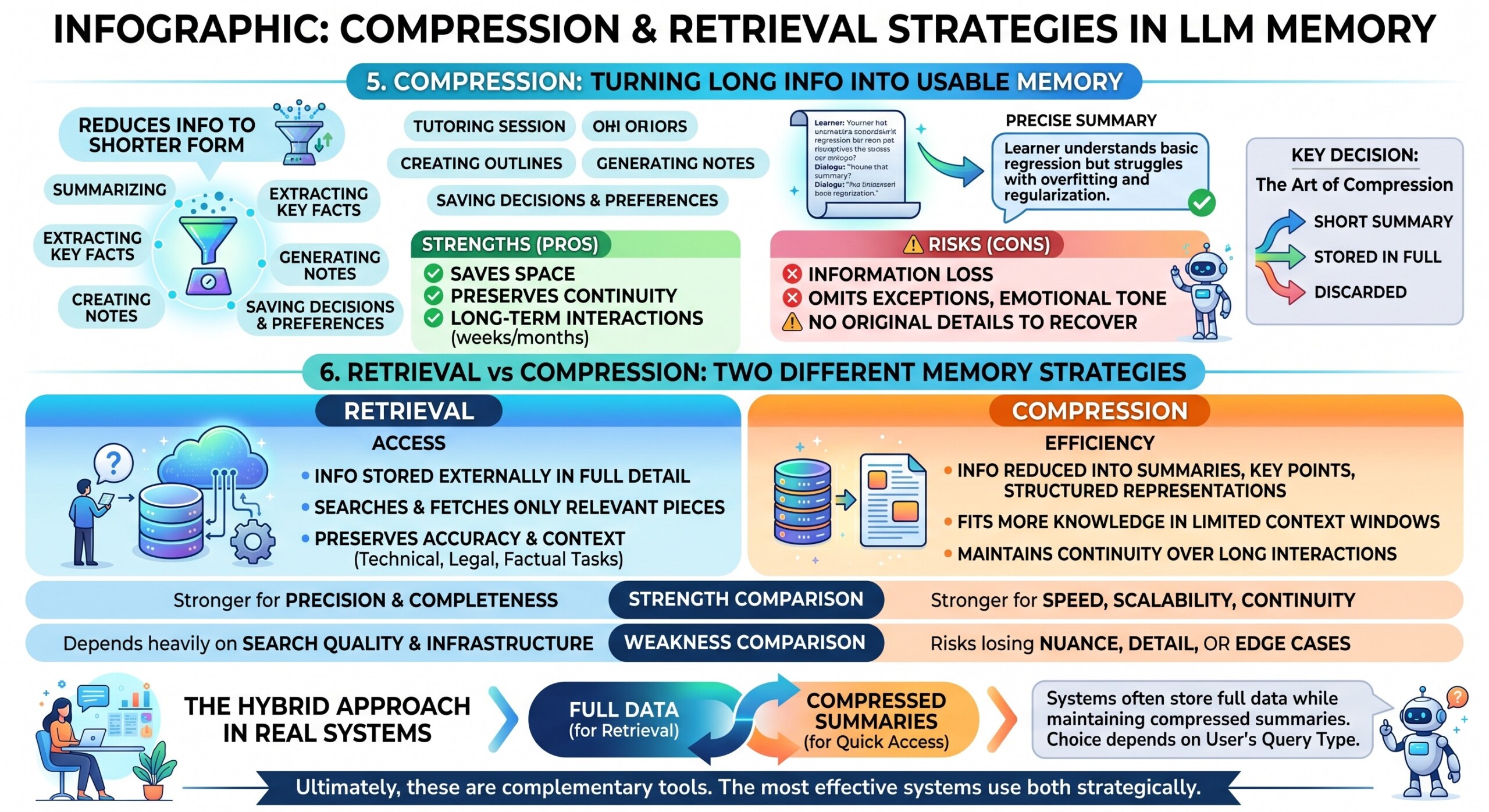
5. Compression: Turning long information into usable memory
Compression is another major memory mechanism. Instead of storing or inserting everything in full detail, the system reduces information into a shorter form. This may involve summarizing conversations, extracting key facts, creating outlines, generating notes, or saving decisions and preferences.
For example, after a long tutoring session, the system may compress the session into a short memory such as: “The learner understands basic regression but struggles with overfitting and regularization.” In a future session, this summary can help the AI tutor continue effectively without reading the entire past conversation.
Compression is powerful because it saves space. It allows systems to preserve continuity without filling the context window with long histories. It is also useful when conversations span weeks or months.
But compression has a risk: information can be lost. A summary may omit exceptions, emotional tone, reasoning steps, or important details. Once the original detail is removed, the model may not be able to recover it.
This means compression should be used thoughtfully. Some information deserves a short summary. Some information should be stored in full. Some should be discarded. The art of compression lies in deciding what matters for future use.
6. Retrieval vs Compression: Two different memory strategies
Retrieval and compression represent two fundamentally different ways of handling memory in LLM systems. Both aim to manage large amounts of information, but they take opposite approaches.
- Retrieval focuses on access:
- Information is stored externally in full detail.
- The system searches and fetches only the most relevant pieces when needed.
- This preserves accuracy and context, especially for technical, legal, or factual tasks.
- Compression focuses on efficiency:
- Information is reduced into summaries, key points, or structured representations.
- This allows more knowledge to fit inside limited context windows.
- It is useful for maintaining continuity over long interactions without overload.
- Strength comparison:
- Retrieval is stronger when precision and completeness are critical.
- Compression is stronger when speed, scalability, and continuity are required.
- Weakness comparison:
- Retrieval depends heavily on search quality and infrastructure.
- Compression risks losing nuance, detail, or edge cases.
- Hybrid approach in real systems:
- Systems often store full data for retrieval while maintaining compressed summaries for quick access.
- The choice between retrieval and compression may depend on the user’s query type.
Ultimately, these are not competing methods but complementary tools. The most effective systems use both strategically. Excellent individualised mentoring programmes available.
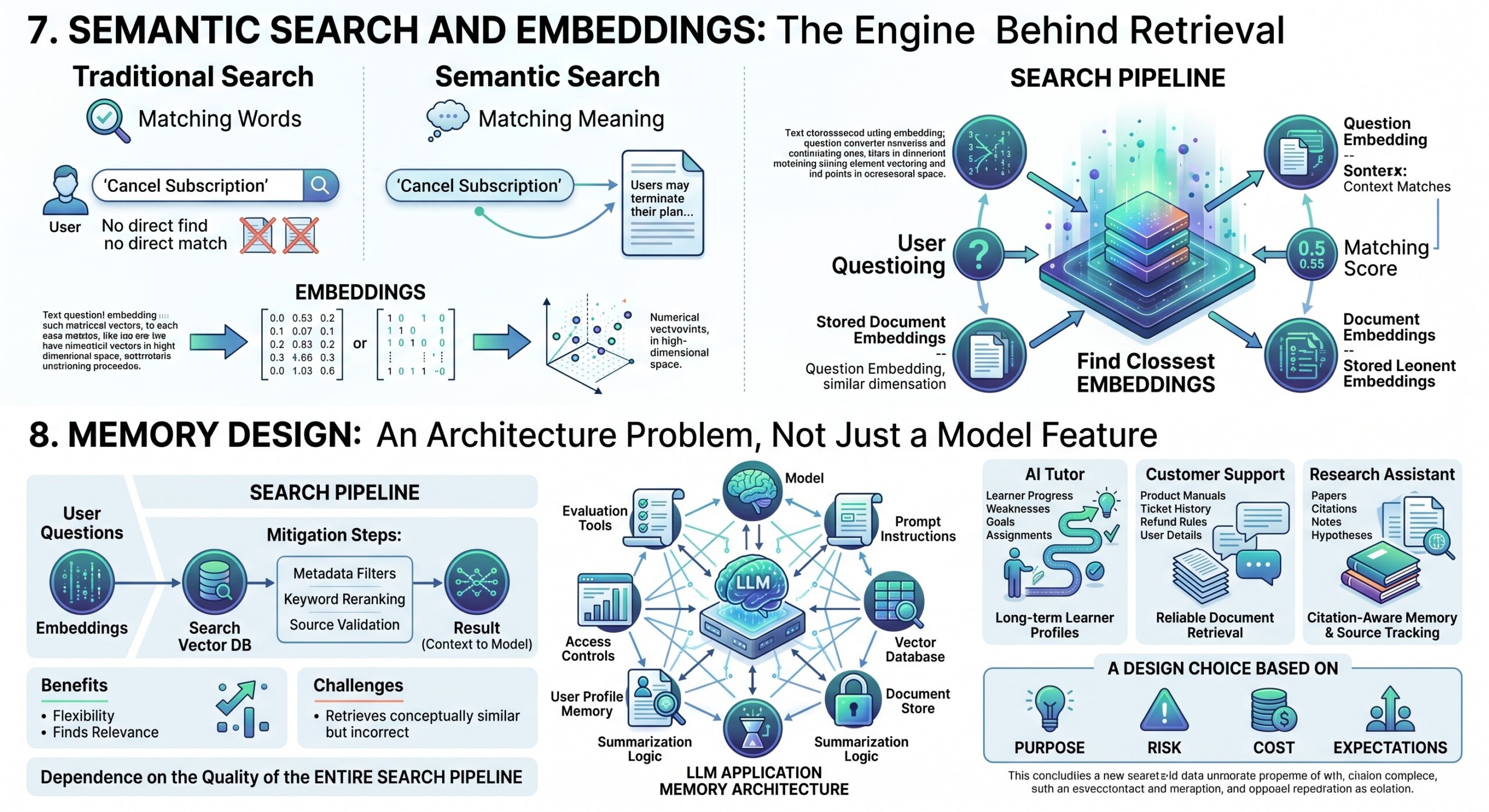
7. Semantic Search and Embeddings: The engine behind retrieval
Retrieval often depends on semantic search. Traditional search looks for matching words. Semantic search looks for matching meaning.
To enable this, text is converted into numerical representations called embeddings. These embeddings capture the meaning of sentences, paragraphs, or documents in a mathematical form. When a user asks a question, that question is also converted into an embedding. The system then compares the question embedding with stored document embeddings to find the closest matches.
For example, a user may ask, “How do I cancel my subscription?” The document may not use the word “cancel.” It may say, “Users may terminate their plan through account settings.” A keyword search might miss this. Semantic search can recognize that both sentences are related in meaning.
This makes retrieval more flexible and powerful. It allows AI systems to find relevant information even when the user’s wording differs from the document’s wording.
However, semantic search is not perfect. It may retrieve text that is conceptually similar but not actually correct for the question. That is why many systems use additional methods such as keyword matching, metadata filters, reranking, and source validation.
Good retrieval depends not only on embeddings, but also on the quality of the entire search pipeline.
8. Memory Design is an architecture problem, not just a Model feature
Many people think memory is something the model either has or does not have. In reality, memory is often designed at the system level.
A useful LLM application may include the model, prompt instructions, a vector database, a document store, user profile memory, summarization logic, access controls, and evaluation tools. Together, these components create the experience of memory.
For example, an AI tutor needs to remember the learner’s progress, weaknesses, goals, and previous assignments. A customer support bot needs to remember product manuals, ticket history, refund rules, and user account details. A research assistant needs to remember papers, citations, notes, and hypotheses.
Each of these systems needs a different memory design. The tutor may need long-term learner profiles. The support bot may need reliable document retrieval. The research assistant may need citation-aware memory and source tracking.
This shows that memory is not one universal feature. It is a design choice based on purpose, risk, cost, and user expectations. Subscribe to our free AI newsletter now.
9. Personalization through long-term memory
Personalization is one of the most impactful applications of memory in LLM systems. By remembering user-specific information, AI can provide more relevant, efficient, and tailored interactions over time.
- Long-term memory allows systems to retain user preferences, goals, behavior patterns, and interaction history.
- It reduces repetition, so users do not need to restate their context, style, or requirements in every interaction.
- Personalization can apply across domains:
- Writing assistants can adapt tone and structure.
- Learning systems can track progress and weaknesses.
- Business tools can remember workflows, priorities, and decision patterns.
- It creates a sense of continuity, making the AI feel more like a consistent assistant rather than a stateless tool.
- However, personalization introduces important design and ethical considerations:
- What information should be stored, and what should be ignored?
- How can users control, edit, or delete their memory?
- How is sensitive data protected from misuse or exposure?
- Responsible systems must balance usefulness with privacy, transparency, and user control.
When implemented correctly, long-term memory turns LLMs from reactive systems into adaptive, user-aware assistants.
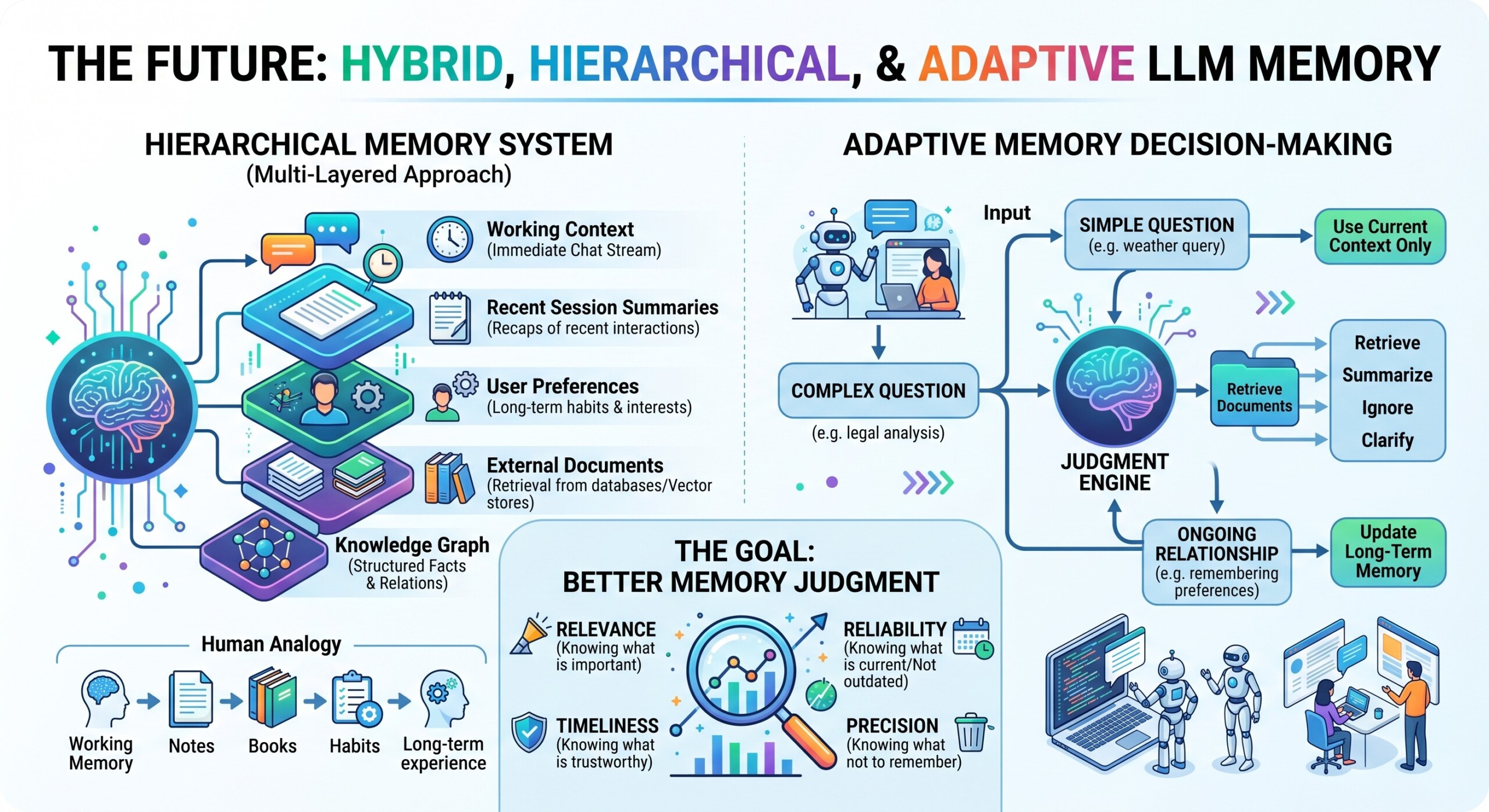
10. The Future: Hybrid, Hierarchical, and Adaptive memory
The future of LLM memory will likely be hybrid. Instead of relying only on context windows, retrieval, or compression, advanced systems will combine several layers of memory.
One layer may handle immediate conversation context. Another may store short summaries of recent sessions. Another may store long-term user preferences. Another may retrieve exact documents from external databases. Another may keep structured facts in a knowledge graph.
This creates a hierarchical memory system, similar to how humans use working memory, notes, books, habits, and long-term experience.
Future systems may also become adaptive. They may decide automatically whether to retrieve, summarize, ignore, or ask for clarification. For a simple question, they may use only the current context. For a complex question, they may retrieve documents. For an ongoing relationship, they may update long-term memory.
The most powerful AI systems will not simply have larger memory. They will have better memory judgment. They will know what is relevant, what is reliable, what is outdated, and what should not be remembered at all. Upgrade your AI-readiness with our masterclass.
Conclusion
Memory mechanisms are central to the future of LLMs. Without memory, an AI system is limited to the information placed in front of it at that moment. With well-designed memory, it can become a tutor, assistant, researcher, analyst, mentor, or enterprise knowledge partner.
The context window gives the model immediate working memory, but it is limited. External memory extends the system beyond those limits. Retrieval brings relevant information into the prompt when needed. Compression makes long histories manageable. Each approach has strengths and weaknesses.
The best systems will combine these methods intelligently. They will use context for the present, retrieval for accuracy, compression for efficiency, and long-term memory for personalization.
In the end, the question is not whether LLMs can remember like humans. The better question is: how can we design memory systems that make AI more useful, reliable, transparent, and trustworthy?
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



