Decoding Strategies in Generative Models

Decoding Strategies in Generative Models
Top-k, top-p, beam search; Temperature scaling
Introduction
Generative models, especially modern large language models, produce text one token at a time. At each step, the model predicts a probability distribution over possible next words and then selects one of them. The method used for this selection is called a decoding strategy.
Even when the same model and prompt are used, different decoding strategies can produce very different outputs. One configuration may generate precise and factual responses, while another may produce creative and varied text.
Decoding is therefore not a minor technical detail. It plays a central role in shaping how AI systems behave, communicate, and deliver value in real-world applications.
Let’s dive deep now.
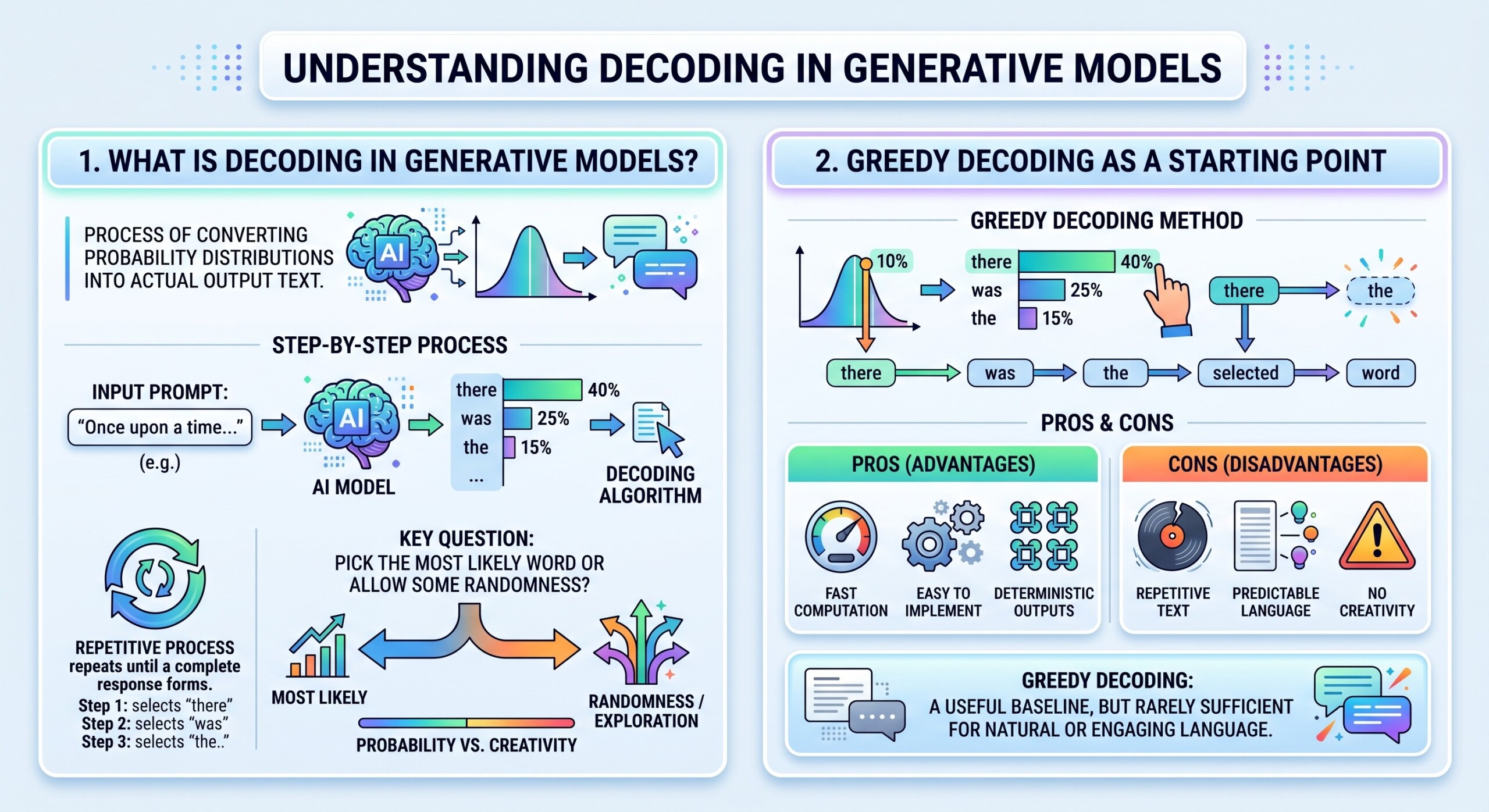
1. What is Decoding in Generative Models?
Decoding refers to the process of converting probability distributions into actual output text. At each step, the model assigns probabilities to all possible tokens, and the decoding algorithm selects one token to continue the sequence.
This process repeats until a complete response is formed. The key question is simple but powerful: should the model always pick the most likely word, or should it allow some randomness to explore alternative possibilities?
2. Greedy Decoding as a Starting Point
The simplest decoding method is greedy decoding. In this approach, the model always selects the token with the highest probability at each step.
- It is fast and easy to implement
- It produces deterministic outputs
- It often leads to repetitive or predictable text
While useful as a baseline, greedy decoding is rarely sufficient for applications that require natural or engaging language. An excellent collection of learning videos awaits you on our Youtube channel.
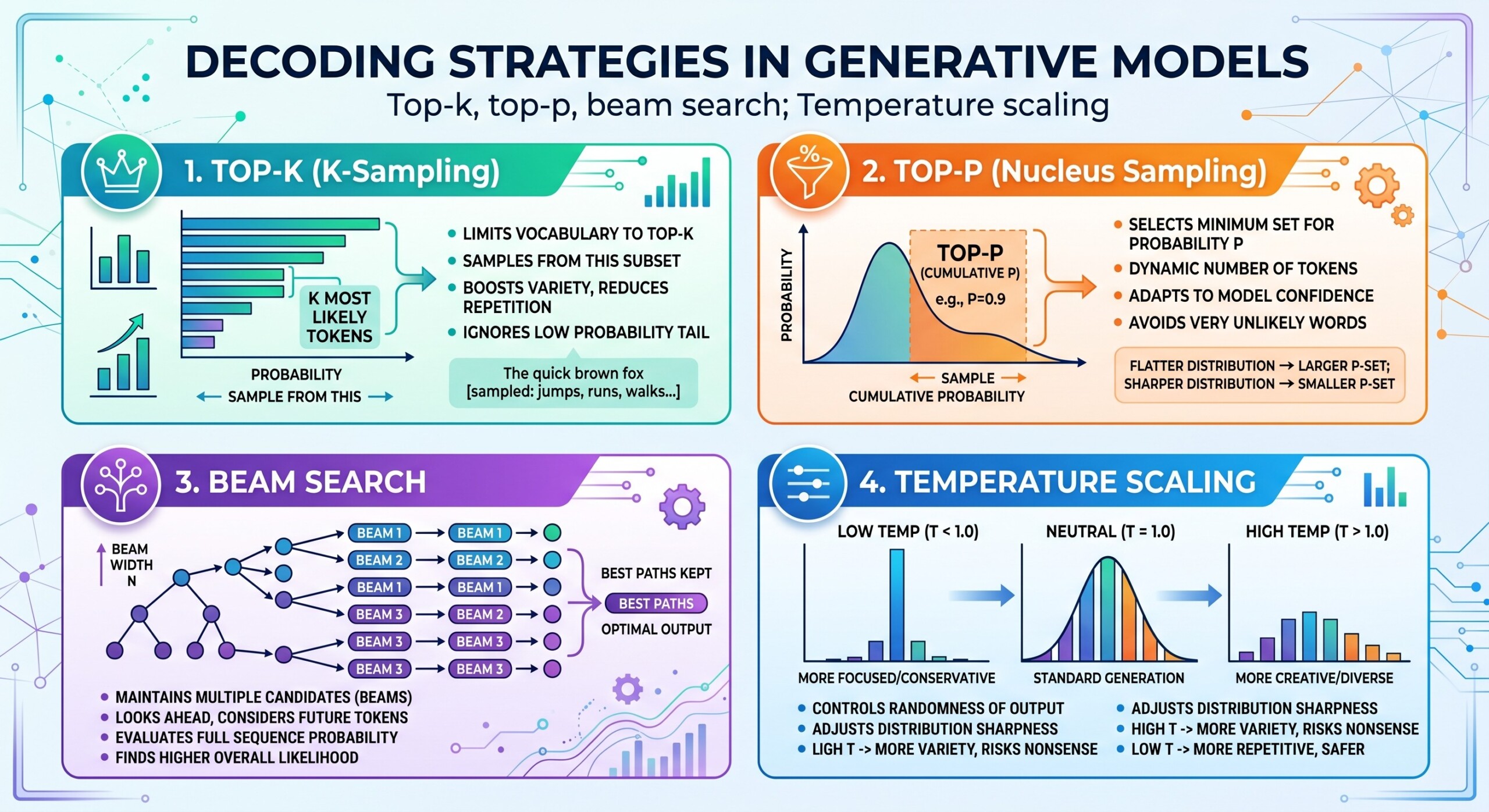
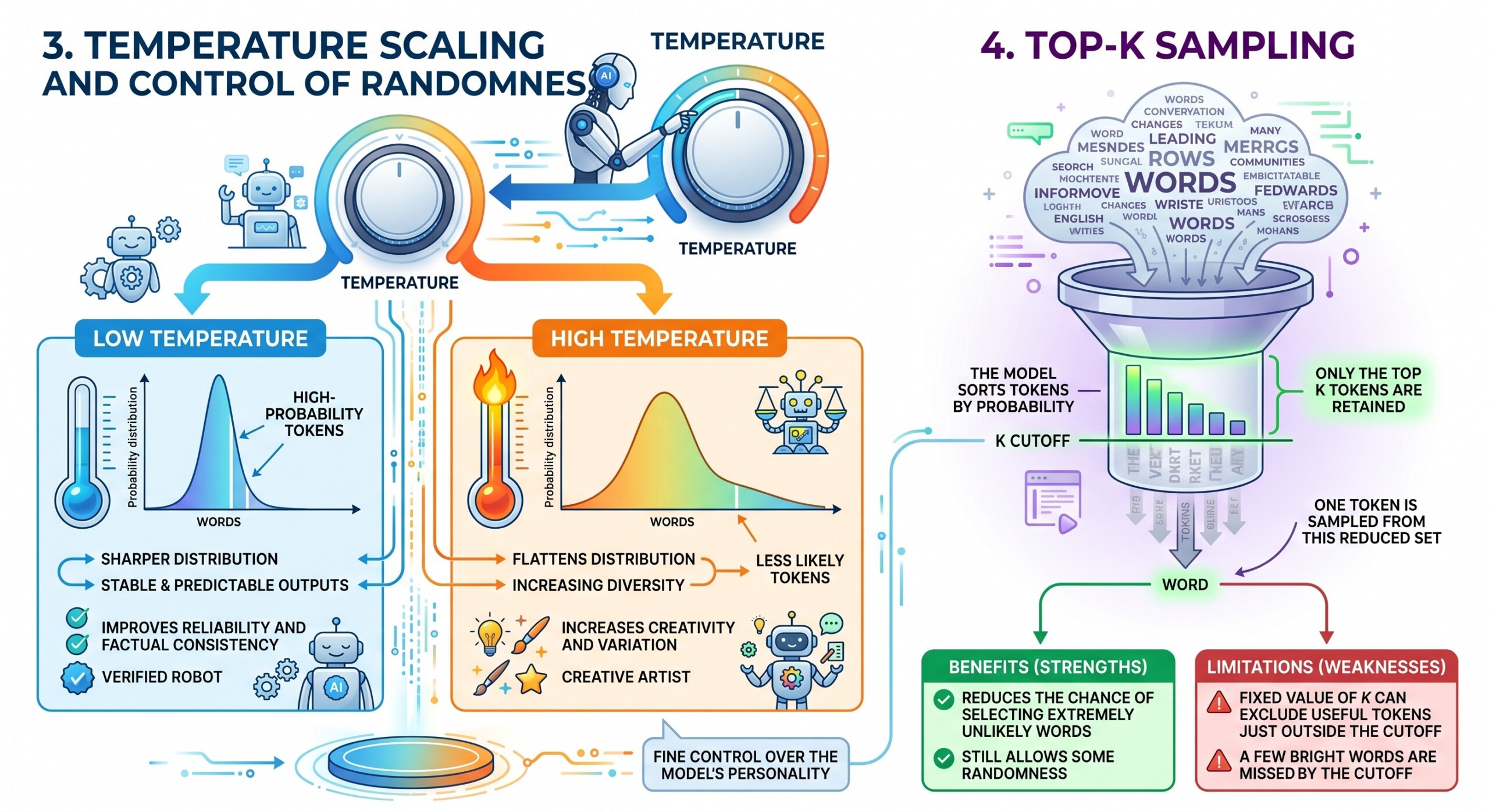
3. Temperature Scaling and Control of Randomness
Temperature scaling adjusts the probability distribution before sampling. It controls how confident or exploratory the model becomes.
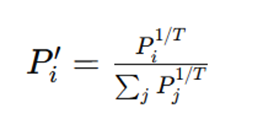
A lower temperature makes the distribution sharper, which pushes the model toward high-probability tokens. This leads to more stable and predictable outputs. A higher temperature flattens the distribution, allowing less likely tokens to be selected and increasing diversity.
- Low temperature improves reliability and factual consistency
- High temperature increases creativity and variation
- Moderate values provide a balance between the two
In practice, temperature acts as a fine control over the model’s personality.
4. Top-k Sampling
Top-k sampling limits the model’s choices to the top k most probable tokens. Instead of considering the entire vocabulary, the model focuses only on a smaller set of likely candidates.
- The model sorts tokens by probability
- Only the top k tokens are retained
- One token is sampled from this reduced set
This method reduces the chance of selecting extremely unlikely words while still allowing some randomness. However, the fixed value of k can sometimes exclude useful tokens that fall just outside the cutoff. A constantly updated Whatsapp channel awaits your participation.
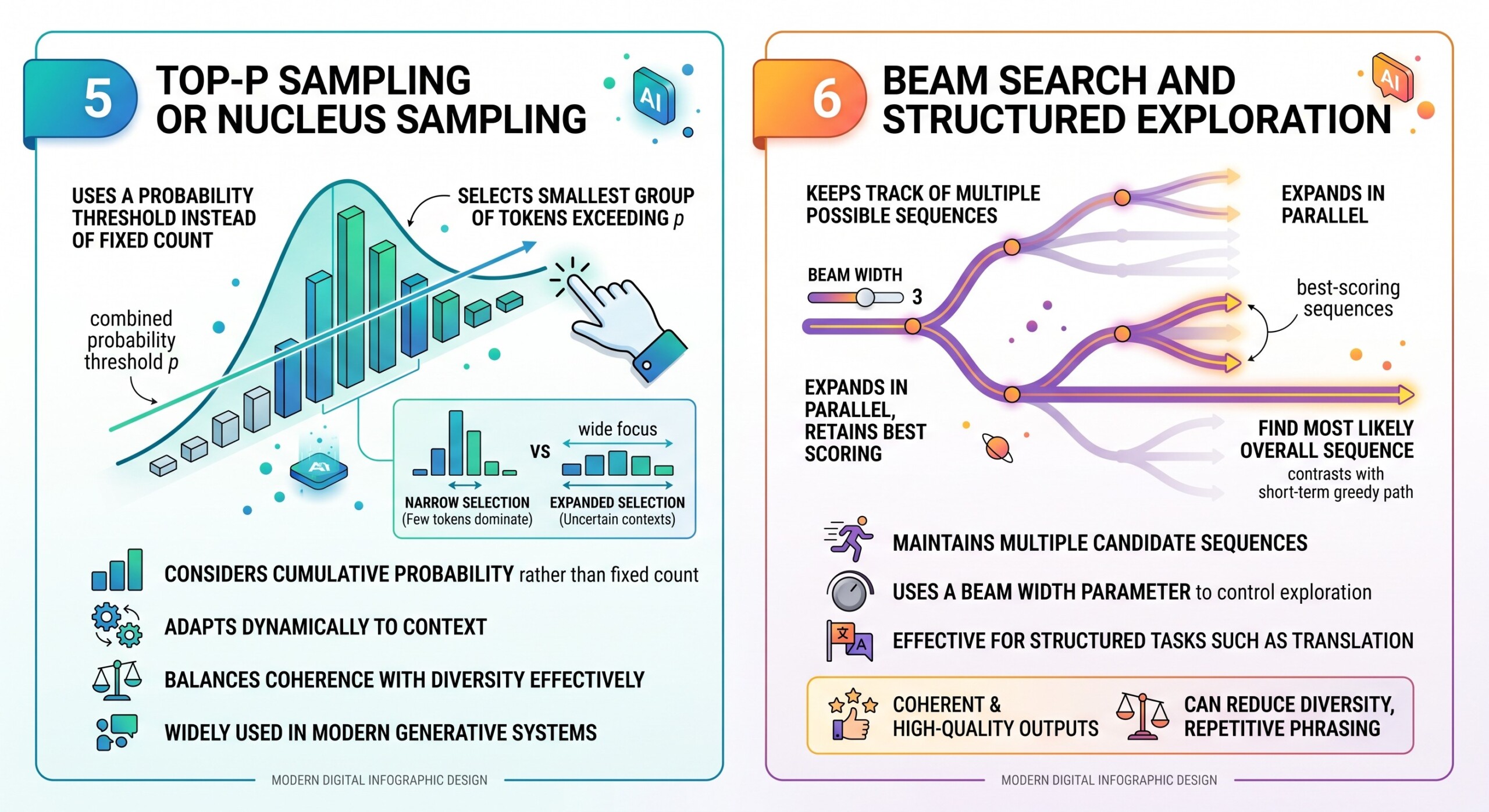
5. Top-p Sampling or Nucleus Sampling
Top-p sampling improves on top-k by using a probability threshold instead of a fixed number of tokens. The model selects the smallest group of tokens whose combined probability exceeds a value p.
This approach adapts to the shape of the probability distribution. In situations where a few tokens dominate, the selection remains narrow. In more uncertain contexts, the selection expands naturally.
- It considers cumulative probability rather than a fixed count
- It adapts dynamically to context
- It balances coherence with diversity effectively
Because of this flexibility, top-p sampling is widely used in modern generative systems.
6. Beam Search and Structured Exploration
Beam search takes a different approach. Instead of sampling randomly, it keeps track of multiple possible sequences at each step and expands them in parallel. At every stage, only the best scoring sequences are retained.
This method is particularly useful when the goal is to find the most likely overall sequence rather than making locally optimal choices.
- It maintains multiple candidate sequences
- It uses a beam width parameter to control exploration
- It is effective for structured tasks such as translation
Beam search tends to produce coherent and high-quality outputs, but it can reduce diversity and sometimes lead to repetitive phrasing. Excellent individualised mentoring programmes available.
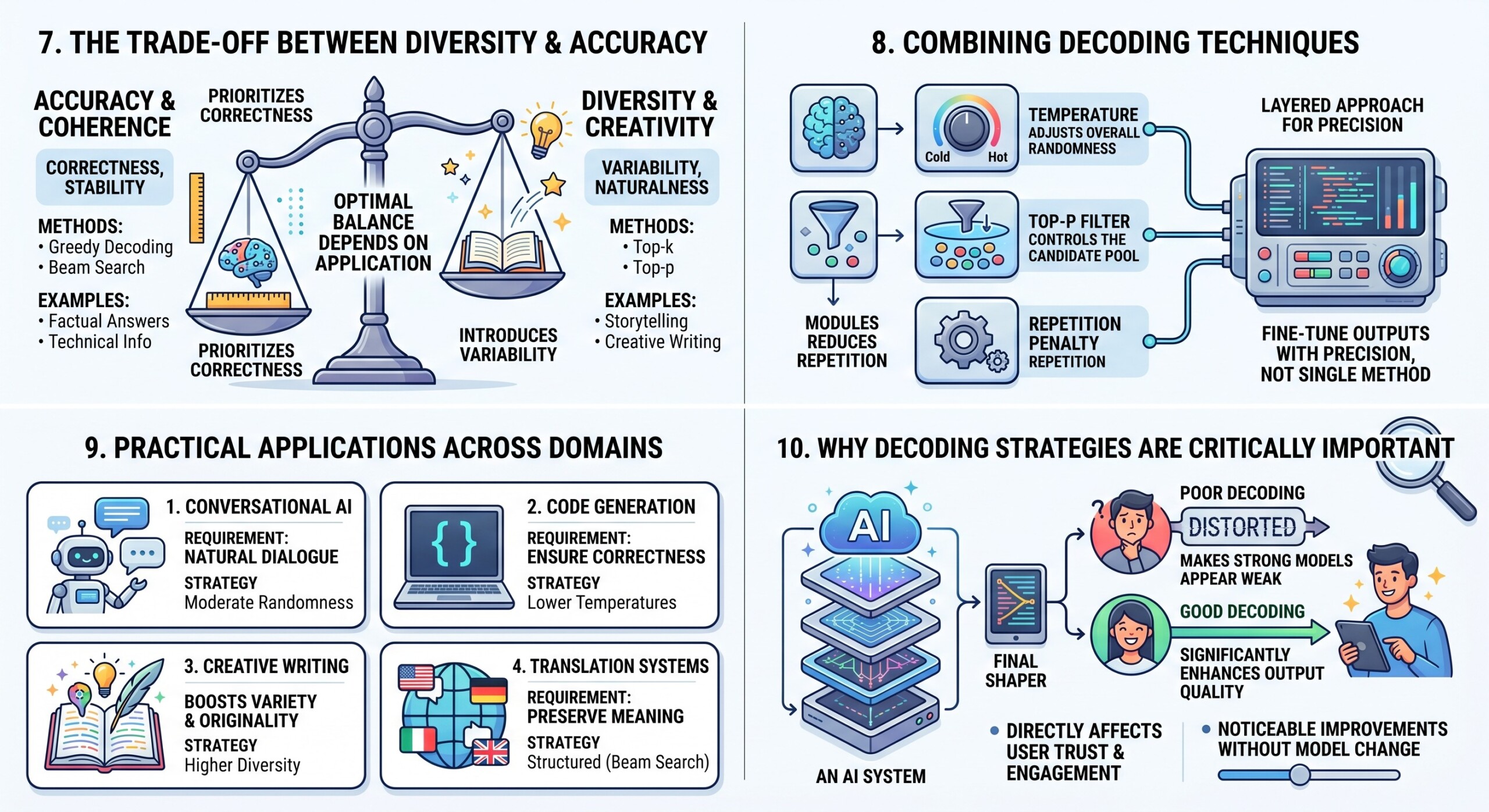
7. The Trade-off Between Diversity and Accuracy
All decoding strategies operate within a fundamental trade-off. On one side is accuracy and coherence. On the other side is diversity and creativity.
Methods like greedy decoding and beam search prioritize correctness and stability. Sampling methods such as top-k and top-p introduce variability, making outputs more natural and less predictable.
The optimal balance depends on the application. A system designed for factual answers requires different settings compared to one designed for storytelling.
8. Combining Decoding Techniques
In real-world systems, decoding strategies are often combined to achieve better control. For example, temperature scaling is frequently used alongside top-p sampling.
- Temperature adjusts overall randomness
- Top-p controls the candidate pool
- Additional penalties can reduce repetition
This layered approach allows developers to fine-tune outputs with precision rather than relying on a single method. Subscribe to our free AI newsletter now.
9. Practical Applications Across Domains
Different applications demand different decoding behaviors. For conversational AI, a moderate level of randomness helps maintain natural dialogue. In contrast, code generation systems often use lower temperatures to ensure correctness.
Creative writing tools benefit from higher diversity, while translation systems rely on structured approaches like beam search to preserve meaning.
The choice of decoding strategy is therefore closely tied to the intended use case and user expectations.
10. Why Decoding Strategies Are Critically Important
The performance of a generative model is not determined by training alone. Decoding plays a crucial role in shaping the final output that users experience.
- Poor decoding can make strong models appear weak
- Good decoding can significantly enhance output quality
- It directly affects user trust and engagement
In many practical scenarios, adjusting decoding parameters can produce noticeable improvements without changing the model itself. Upgrade your AI-readiness with our masterclass.
Conclusion
Decoding strategies form the final step in the generative process, transforming probability distributions into meaningful language. They determine whether a model behaves in a predictable, cautious manner or explores more creative and diverse possibilities.
From temperature scaling to top-k, top-p, and beam search, each method offers a different balance between control and flexibility. Understanding these strategies allows practitioners to tailor AI systems to specific goals, whether those involve accuracy, creativity, or a mix of both.
As generative AI continues to expand across industries, mastering decoding strategies will become an essential skill. It is not only about building powerful models, but also about guiding them to communicate effectively in the real world.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



