Mixture of Experts (MoE) Architectures

Mixture of Experts (MoE) Architectures
Sparse routing; Conditional computation
Introduction
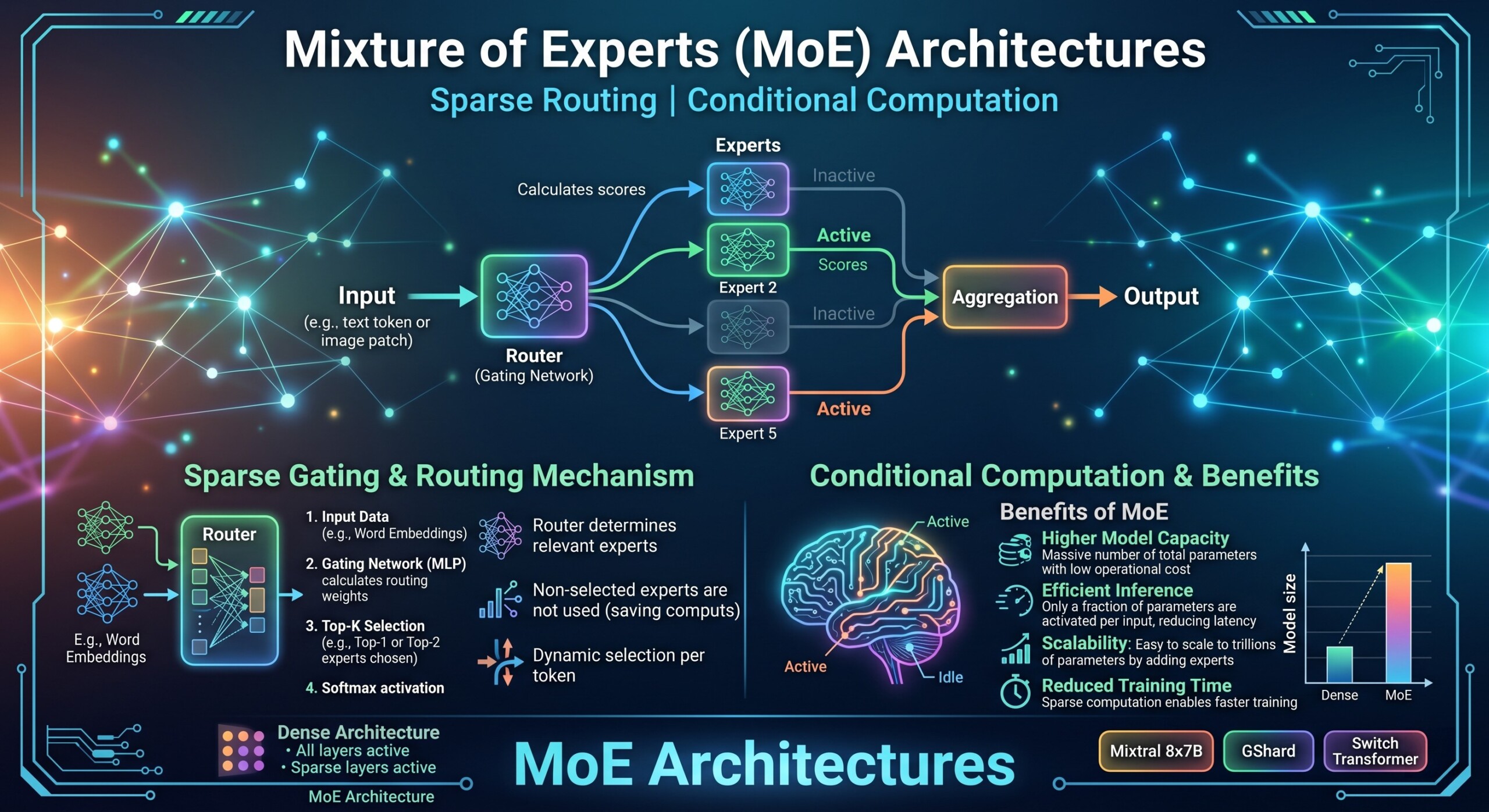
Mixture of Experts, or MoE, is one of the most important architectural ideas behind today’s efficient large AI models. The basic idea is simple: instead of making every input pass through the same full model, an MoE model contains many “expert” subnetworks and uses a router to choose only a small number of them for each token or input. This is called sparse routing and conditional computation.
In a dense Transformer model, every token activates nearly the same set of parameters. In an MoE Transformer, only selected experts are activated for each token. This allows the model to have a very large total parameter count while keeping the number of active parameters, and therefore the compute cost per token, much lower. Switch Transformer, for example, showed that sparse expert models could scale to trillion-parameter sizes while keeping computation manageable, though with challenges such as routing complexity, communication cost, and training instability.
MoE has become especially important in large language models because the AI industry now faces a major constraint: simply making dense models bigger is extremely expensive. Sparse MoE provides a way to increase capacity without increasing computation in the same proportion. Models such as GShard, Switch Transformer, Mixtral, DeepSeekMoE, and DeepSeek-V3 show how MoE has moved from a research idea to a practical scaling strategy for modern AI systems.
Let’s dive deep into the topic now.
1. What Is a Mixture of Experts Architecture?
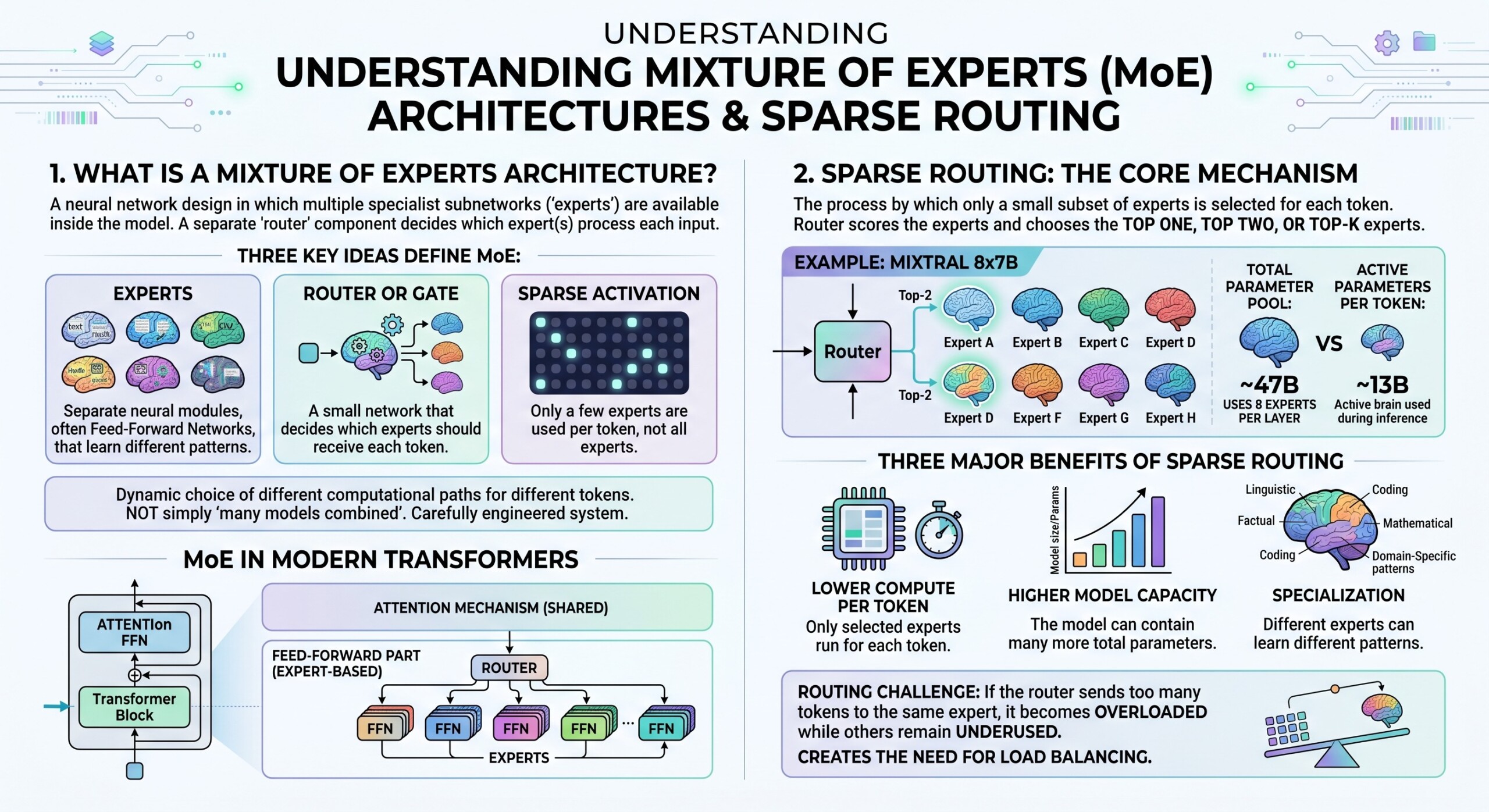
A Mixture of Experts architecture is a neural network design in which multiple specialist subnetworks, called experts, are available inside the model. A separate component, usually called a router or gating network, decides which expert or experts should process a given input.
In modern Transformer-based MoE models, the experts often replace or augment the feed-forward network layers inside the Transformer block. The attention mechanism may remain shared, while the feed-forward part becomes expert-based.
Three key ideas define MoE:
- Experts: Separate neural modules, often feed-forward networks, that learn different patterns.
- Router or gate: A small network that decides which experts should receive each token.
- Sparse activation: Only a few experts are used per token, not all experts.
This means MoE is not simply “many models combined.” It is a carefully engineered system where the model dynamically chooses different computational paths for different tokens.
2. Sparse Routing: The Core Mechanism
Sparse routing is the process by which only a small subset of experts is selected for each token. Instead of sending every token to every expert, the router scores the experts and chooses the top one, top two, or top-k experts.
For example, Mixtral 8x7B uses eight experts per layer, and for every token, the router selects two experts. This gives each token access to a large total parameter pool, but only a smaller active subset is used during inference. Mixtral’s paper reports that although the model has access to 47B parameters, it uses about 13B active parameters per token during inference.
Sparse routing has three major benefits:
- Lower compute per token: Only selected experts run for each token.
- Higher model capacity: The model can contain many more total parameters.
- Specialization: Different experts can learn different linguistic, factual, coding, mathematical, or domain-specific patterns.
However, routing is not trivial. If the router sends too many tokens to the same expert, that expert becomes overloaded while others remain underused. This creates the need for load balancing. An excellent collection of learning videos awaits you on our Youtube channel.
3. Conditional Computation: Computing Only What Is Needed
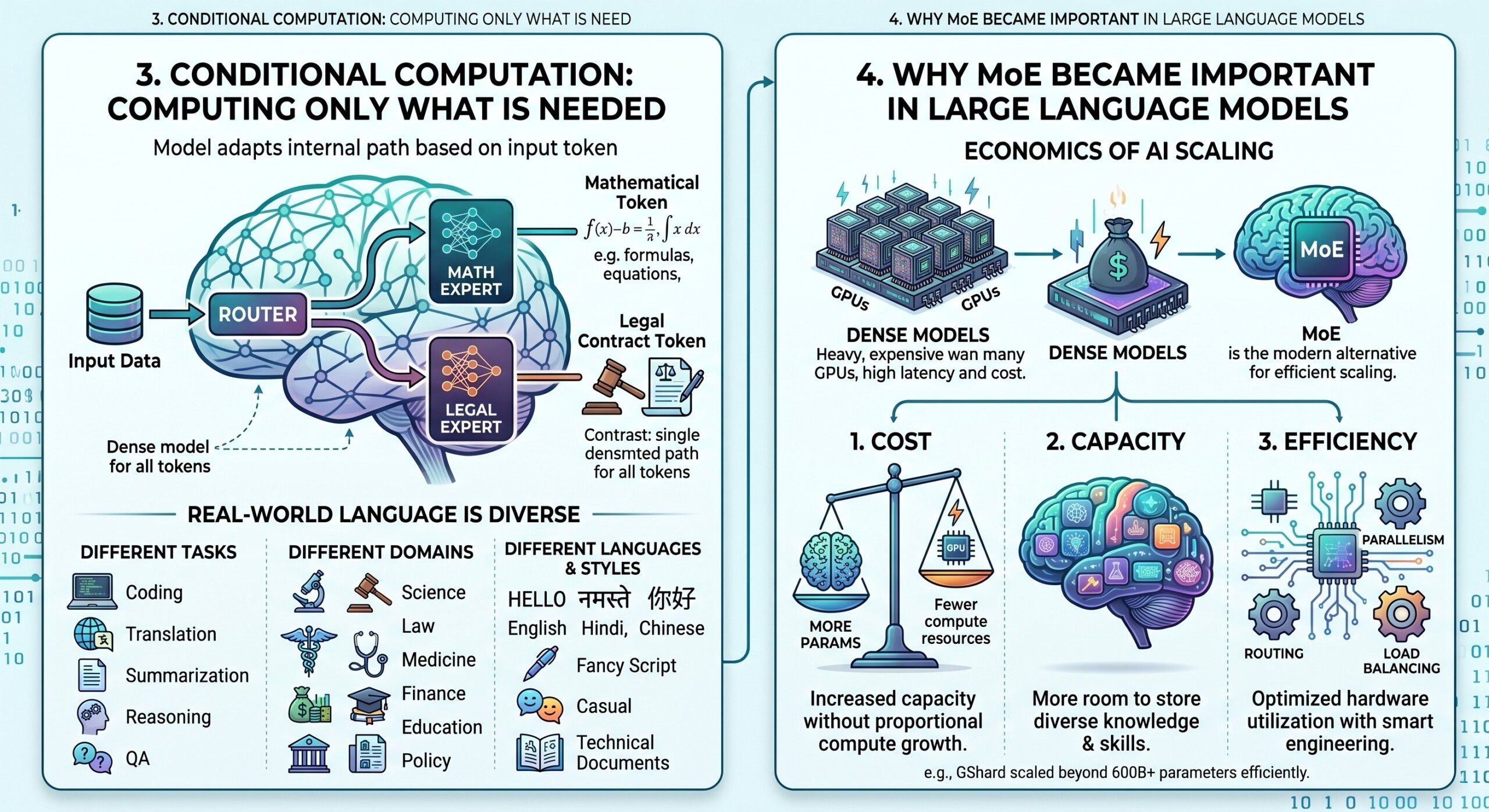
Conditional computation means the model does not perform the same computation for every input. Instead, it chooses computation based on the input itself.
In dense models, every token typically goes through the same parameters. In MoE models, two tokens in the same sentence may activate different experts. For example, a mathematical token may be routed to one expert, while a legal or multilingual token may be routed to another.
The idea is powerful because real-world language is diverse. A single model may need to handle:
- Different tasks: coding, translation, summarization, reasoning, question answering.
- Different domains: science, law, medicine, finance, education, policy.
- Different languages and styles: English, Hindi, Chinese, formal writing, casual chat, technical documents.
Conditional computation allows the model to adapt its internal path depending on the token, instead of forcing all inputs through exactly the same computation.
4. Why MoE Became Important in Large Language Models
The rise of MoE is closely connected to the economics of AI scaling. Large dense models are powerful, but they are expensive to train and serve. Every token must activate a very large number of parameters, which increases GPU memory demand, energy use, latency, and cost.
MoE offers a more efficient scaling path. It allows a model to increase total capacity while keeping active computation relatively controlled. GShard demonstrated sparse MoE scaling beyond 600 billion parameters for multilingual translation, using conditional computation and automatic sharding.
MoE became important because it addresses three major scaling problems:
- Cost: More total parameters without proportional compute growth.
- Capacity: More room to store knowledge and skills.
- Efficiency: Better use of hardware when routing, parallelism, and load balancing are well engineered.
This is why MoE is now central to many frontier and open-weight model discussions. A constantly updated Whatsapp channel awaits your participation.
5. The Router: The Brain of Expert Selection
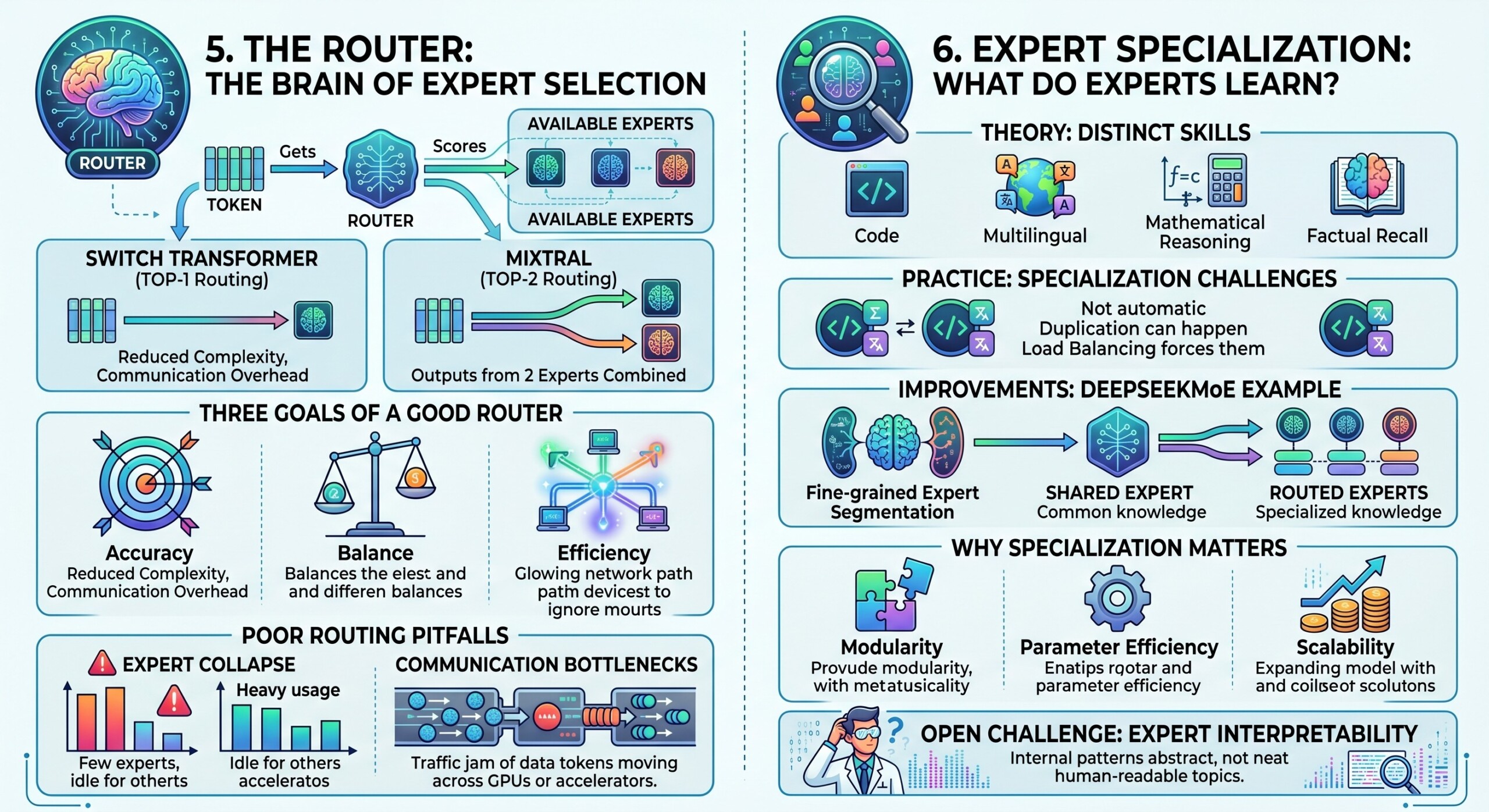
The router is one of the most important components in an MoE system. It receives the token representation and assigns scores to available experts. The model then selects the top expert or top-k experts.
Different models use different routing strategies. Switch Transformer simplified routing by using one selected expert per token, helping reduce complexity and communication overhead. Mixtral uses top-2 routing, where each token is processed by two selected experts and their outputs are combined.
A good router must satisfy three goals:
- Accuracy: Send tokens to experts that improve model performance.
- Balance: Avoid overloading only a few experts.
- Efficiency: Route tokens in a way that works well across GPUs or accelerators.
Poor routing can cause expert collapse, where only a few experts are heavily used, while others learn little. It can also create communication bottlenecks when tokens must be moved across devices.
6. Expert Specialization: What Do Experts Learn?
One of the promises of MoE is expert specialization. In theory, different experts should learn different skills. One expert may become better at code, another at multilingual text, another at mathematical reasoning, and another at factual recall.
In practice, specialization does not happen automatically. Some experts may duplicate each other, especially if load balancing forces them to behave similarly. DeepSeekMoE was designed to improve expert specialization by using fine-grained expert segmentation and shared experts. The shared experts capture common knowledge, while routed experts are encouraged to handle more specialized knowledge.
Expert specialization matters because:
- It improves parameter efficiency: Experts do not all need to learn the same things.
- It supports modularity: Different parts of the model can focus on different capabilities.
- It may improve scalability: More experts can be added without making every token use all of them.
Still, expert interpretability remains an open research challenge. We should not assume that every expert maps neatly to a human-readable topic such as “math expert” or “legal expert.” The internal specialization may be more abstract. Excellent individualised mentoring programmes available.
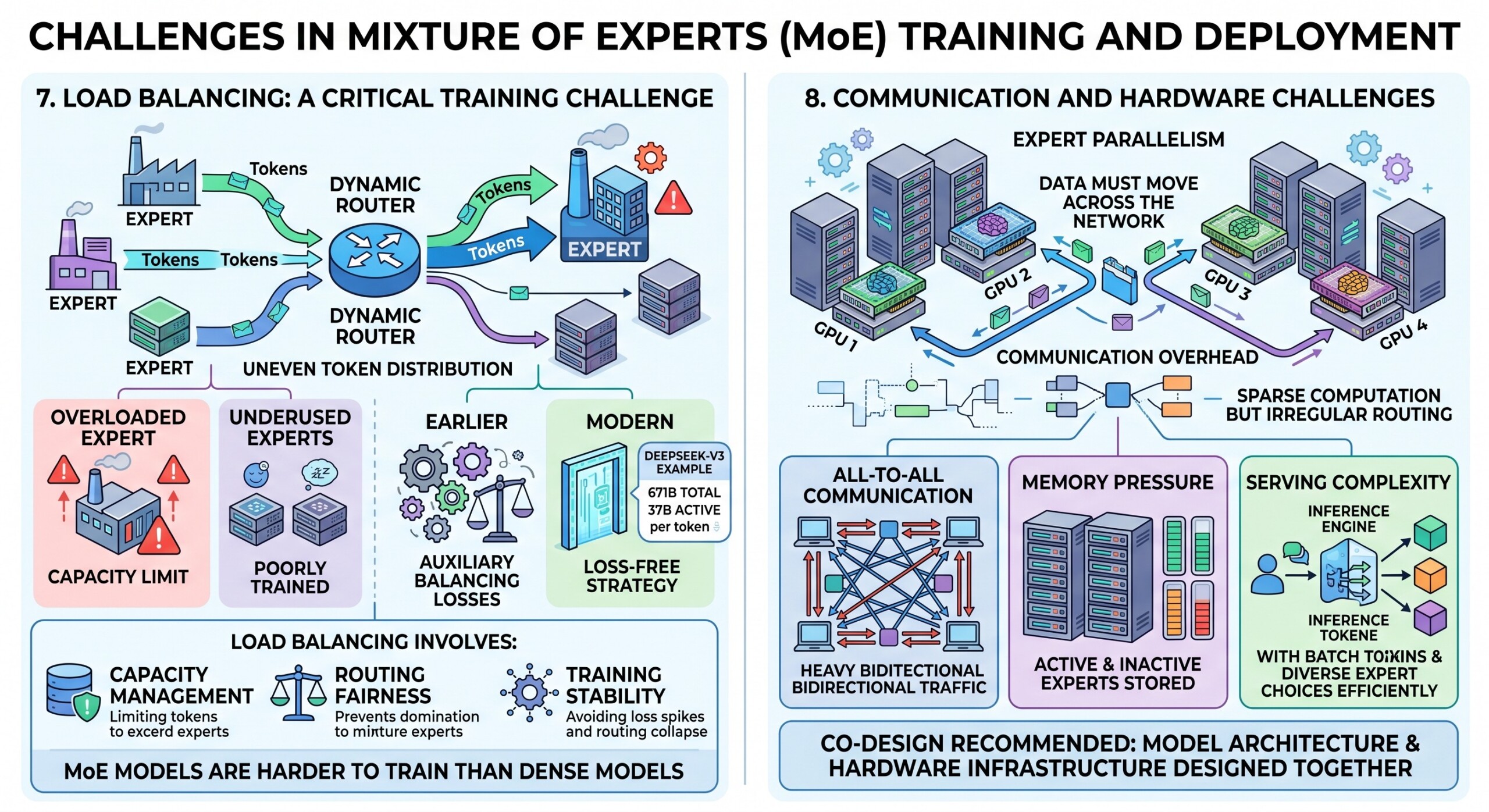
7. Load Balancing: A Critical Training Challenge
Load balancing is one of the hardest practical problems in MoE. Since the router chooses experts dynamically, some experts may receive too many tokens while others receive too few.
If many tokens go to the same expert, the model faces two problems. First, the overloaded expert may exceed its capacity. Second, underused experts do not train properly. Earlier MoE systems often used auxiliary load-balancing losses to encourage more even expert usage.
However, auxiliary losses can also interfere with the main language modeling objective. DeepSeek-V3 introduced an auxiliary-loss-free load balancing strategy, along with its DeepSeekMoE architecture, and reports 671B total parameters with 37B activated per token.
Load balancing involves:
- Capacity management: Limiting how many tokens each expert can process.
- Routing fairness: Preventing only a few experts from dominating.
- Training stability: Avoiding loss spikes, routing collapse, and inefficient expert usage.
This is one reason MoE models are harder to train than dense models, even though they can be more compute-efficient at scale.
8. Communication and Hardware Challenges
MoE models are not automatically cheaper or faster in every situation. They often require expert parallelism, where different experts are placed on different GPUs or accelerator devices. When tokens are routed to experts on other devices, data must move across the network.
This creates communication overhead. In dense models, computation is heavy but often more regular. In MoE models, computation is sparse but routing can be irregular. Hardware efficiency depends on batching, expert placement, interconnect speed, memory bandwidth, and serving infrastructure.
Three hardware issues are especially important:
- All-to-all communication: Tokens may need to be sent between devices that host different experts.
- Memory pressure: Even inactive experts must be stored somewhere.
- Serving complexity: Inference engines must efficiently batch tokens with different expert choices.
This is why MoE is most effective when model architecture and hardware infrastructure are designed together. Subscribe to our free AI newsletter now.
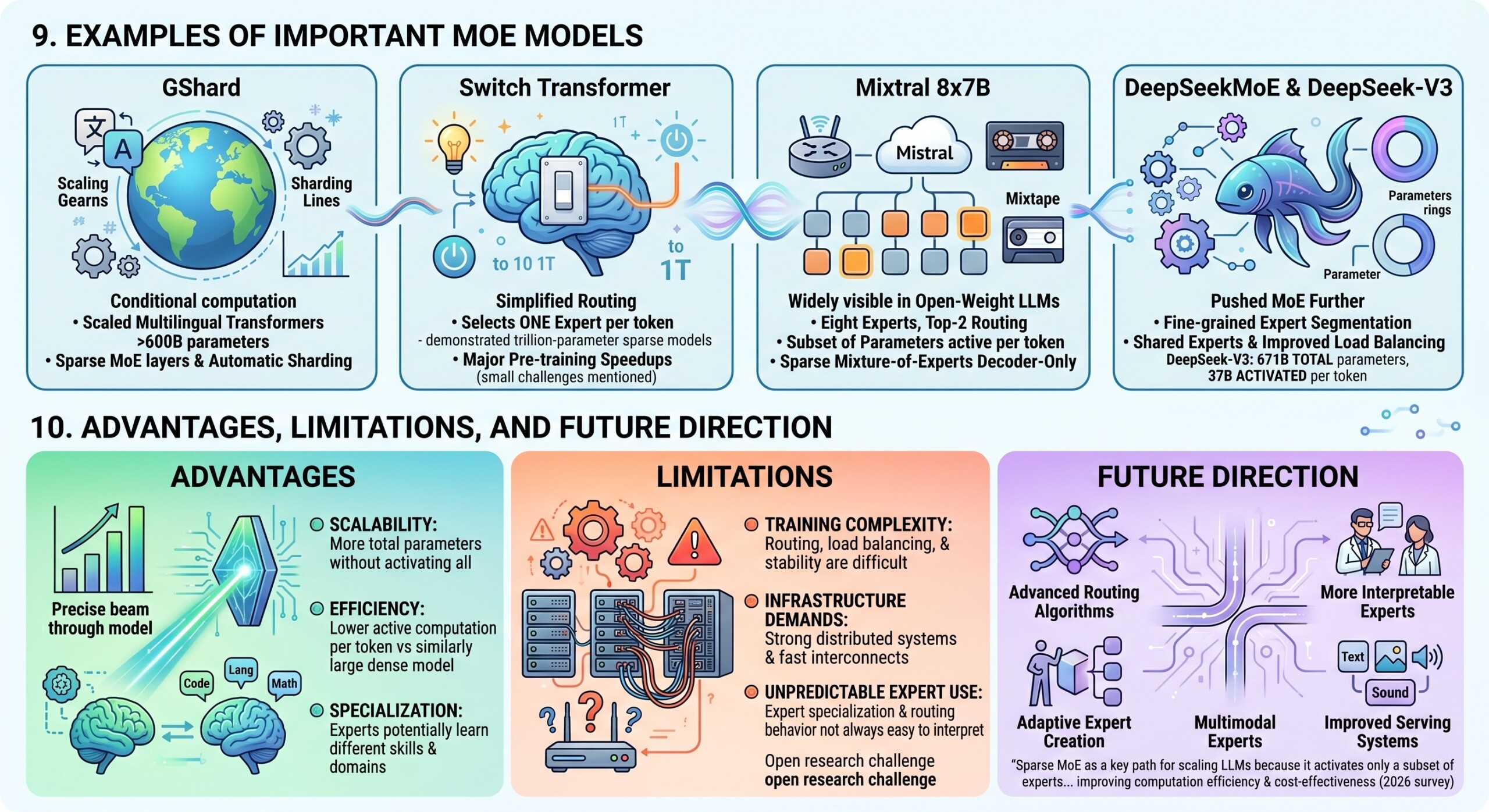
9. Examples of Important MoE Models
Several major MoE systems have shaped the field.
GShard showed that conditional computation could scale multilingual Transformer models beyond 600B parameters using sparse MoE layers and automatic sharding.
Switch Transformer simplified MoE routing by selecting one expert per token. It demonstrated up to trillion-parameter sparse models and reported major pre-training speedups under the same compute budget, while also highlighting instability and communication challenges.
Mixtral 8x7B made sparse MoE widely visible in the open-weight LLM world. It uses eight experts and top-2 routing, with only a subset of parameters active per token. Mistral described it as a sparse mixture-of-experts decoder-only model where a router selects two expert groups at every layer for each token.
DeepSeekMoE and DeepSeek-V3 pushed MoE further with fine-grained expert segmentation, shared experts, and improved load balancing. DeepSeek-V3 reports 671B total parameters and 37B activated parameters per token, illustrating the modern trend: very large total capacity with much smaller active computation.
10. Advantages, Limitations, and Future Direction
MoE is powerful, but it is not a universal replacement for dense architectures. Its advantages are strongest at large scale, where the savings from sparse activation can justify the engineering complexity.
The main advantages are:
- Scalability: More total parameters without activating all of them every time.
- Efficiency: Lower active computation per token compared with a similarly large dense model.
- Specialization: Experts can potentially learn different skills and domains.
The main limitations are:
- Training complexity: Routing, load balancing, and stability are difficult.
- Infrastructure demands: MoE requires strong distributed systems and fast interconnects.
- Unpredictable expert use: Expert specialization and routing behavior are not always easy to interpret.
The future of MoE will likely include better routing algorithms, more interpretable experts, adaptive expert creation, multimodal experts, and improved serving systems. A 2026 survey describes sparse MoE as a key path for scaling LLMs because it activates only a subset of experts through a routing network, improving computational efficiency and cost-effectiveness. Upgrade your AI-readiness with our masterclass.
Conclusion
Mixture of Experts architectures represent a major shift in how AI models are scaled. Instead of making every token use the entire model, MoE systems use sparse routing and conditional computation to activate only selected experts. This allows models to grow in total parameter capacity while keeping active computation much lower than an equivalent dense model.
The central idea is elegant: not every input needs the same computation. A model handling mathematics, code, multilingual text, policy documents, casual chat, and scientific reasoning should not necessarily process all tokens through the same internal path. MoE gives the model a way to choose different paths for different inputs.
At the same time, MoE is not magic. It brings real engineering challenges: routing quality, expert load balancing, communication overhead, training instability, and serving complexity. The best MoE systems succeed not only because they have many experts, but because they solve these practical problems well.
The latest direction is clear. Modern AI is moving from simply “bigger dense models” toward larger, sparser, more conditional models. MoE architectures are now one of the most important tools in that transition. For learners, researchers, and AI leaders, understanding MoE is essential because it explains how many advanced models can appear very large in total capacity while remaining economically usable in training and inference.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



