Positional Encoding & Sequence Representation

Positional Encoding & Sequence Representation
Absolute vs relative encoding; RoPE, ALiBi
Introduction
Modern transformer models, such as those used in natural language processing, do not inherently understand the order of words in a sequence. Unlike recurrent or convolutional models, transformers process tokens in parallel, which makes them highly efficient but positionally unaware by design.
To solve this, positional encoding is introduced as a mechanism to inject information about the order of tokens. Without it, a sentence like “dog bites man” would be indistinguishable from “man bites dog”.
Over time, researchers have developed different approaches to encode positional information. These broadly fall into two categories:
- Absolute positional encoding
- Relative positional encoding
More advanced methods such as Rotary Positional Encoding (RoPE) and Attention with Linear Biases (ALiBi) have significantly improved how models handle long sequences and generalize beyond training lengths.

Let’s dive deep into the topic.
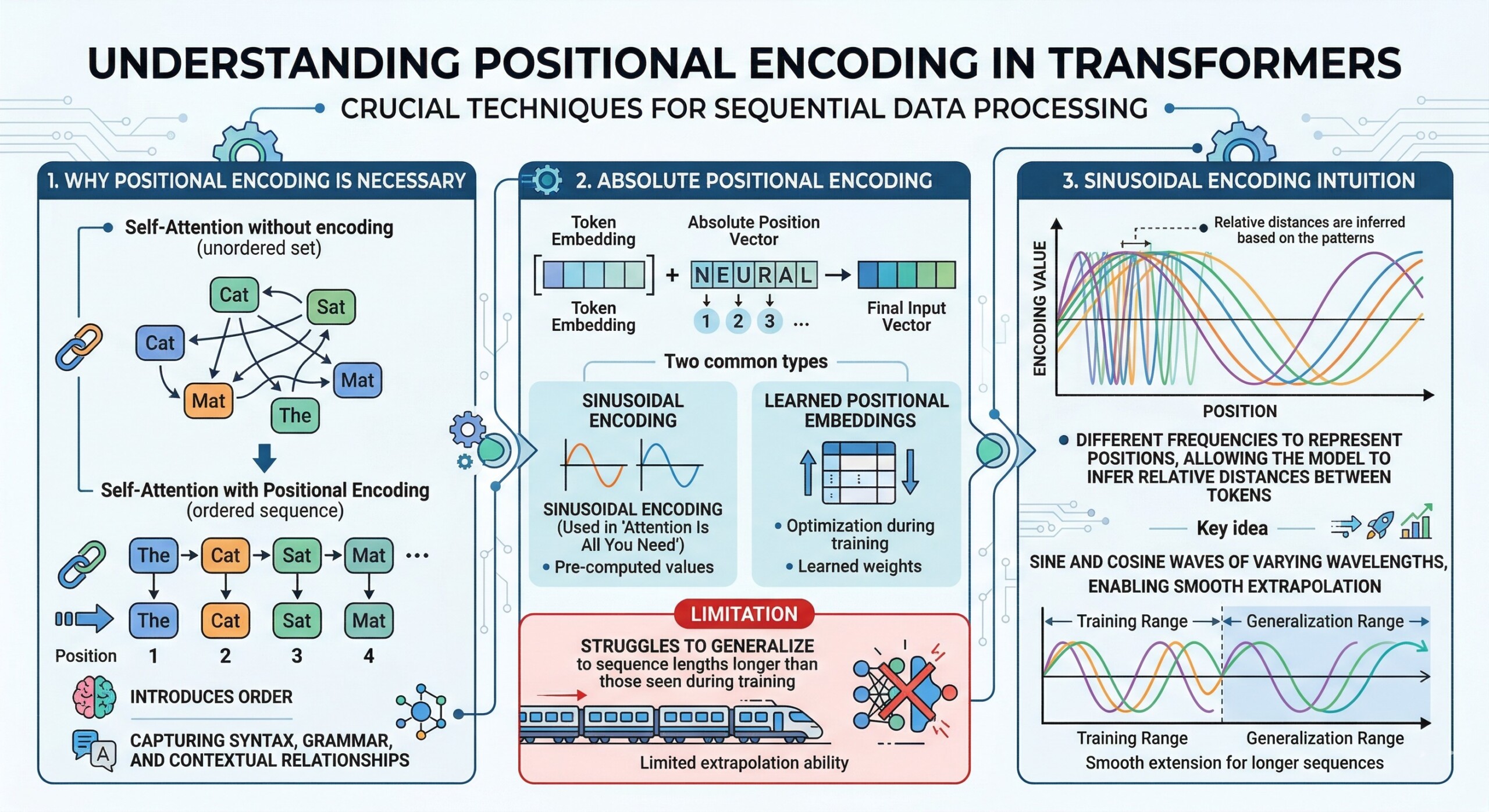
1. Why positional encoding is necessary
Transformers rely on self-attention, which treats input tokens as a set rather than a sequence. Positional encoding introduces order, enabling the model to capture syntax, grammar, and contextual relationships.
2. Absolute positional encoding
Absolute encoding assigns a fixed position to each token in a sequence (e.g., position 1, 2, 3…). These encodings are added to token embeddings.
Two common types:
- Sinusoidal encoding (used in Attention Is All You Need)
- Learned positional embeddings
Limitation:
They struggle to generalize to sequence lengths longer than those seen during training. An excellent collection of learning videos awaits you on our Youtube channel.
3. Sinusoidal encoding intuition
Sinusoidal functions use different frequencies to represent positions, allowing the model to infer relative distances between tokens.
Key idea: Positions are encoded using sine and cosine waves of varying wavelengths, enabling smooth extrapolation.
4. Relative positional encoding
Instead of encoding absolute positions, relative encoding focuses on distance between tokens.
Example:
The model learns that “word A is 3 tokens away from word B” rather than “word A is at position 5.”
Advantage:
Better generalization and improved handling of long sequences. A constantly updated Whatsapp channel awaits your participation.
5. Limitations of early relative methods
Early implementations increased computational complexity and were difficult to scale efficiently in large transformer architectures.
6. Rotary Positional Encoding (RoPE)
RoPE introduces position information by rotating query and key vectors in attention space.
Core idea:
- Each token embedding is rotated based on its position
- Relative position emerges naturally through dot-product attention
Benefits:
- Strong generalization to longer sequences
- Preserves relative distance information
- Efficient and widely used in modern LLMs Excellent individualised mentoring programmes available.
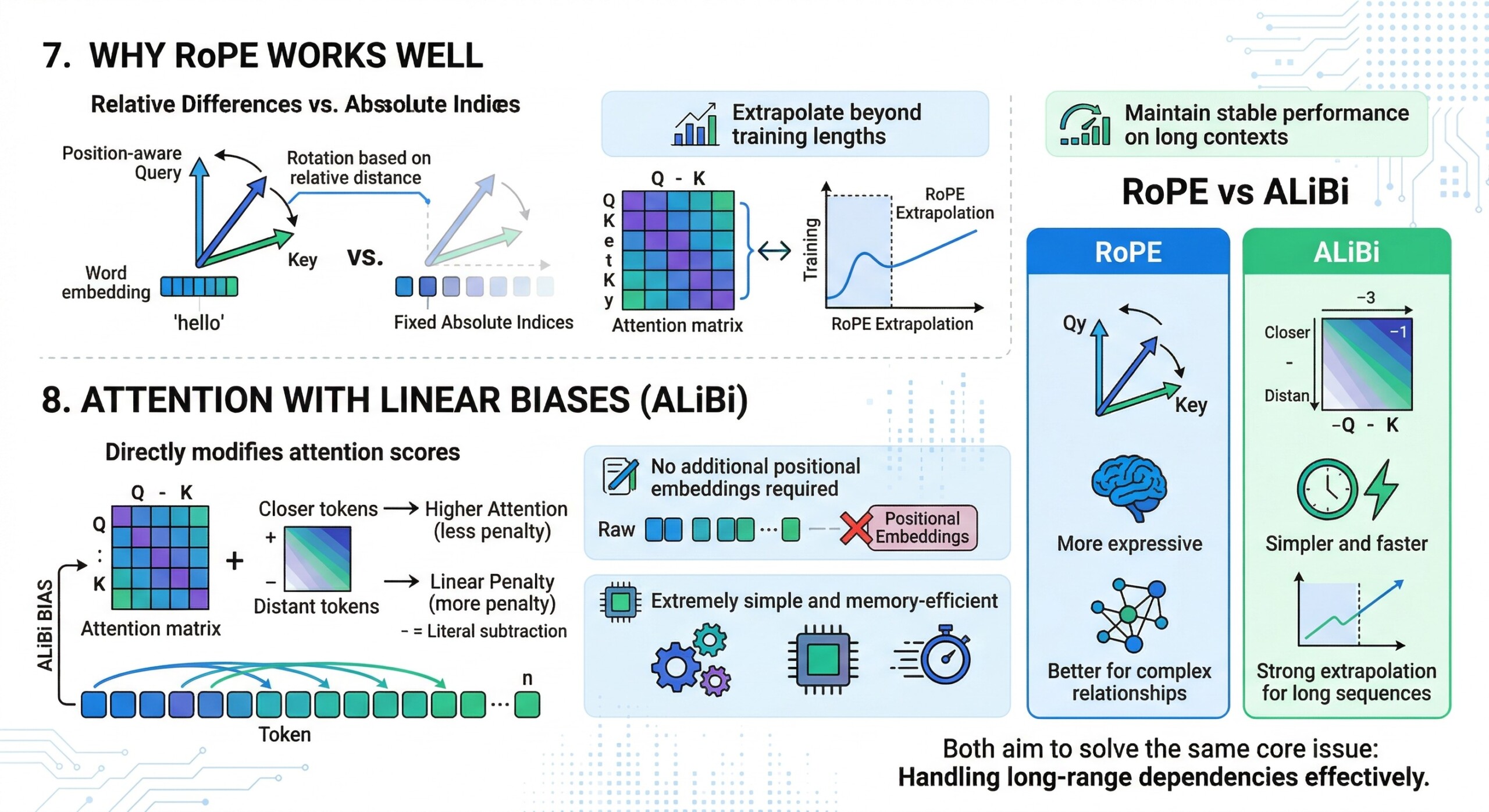
7. Why RoPE works well
RoPE encodes position in a way that makes attention scores depend on relative differences between positions, not absolute indices.
This allows models to:
- Extrapolate beyond training lengths
- Maintain stable performance on long contexts
8. Attention with Linear Biases (ALiBi)
ALiBi modifies attention scores by adding a linear bias based on token distance.
Instead of embedding positions, it directly adjusts attention weights:
- Closer tokens get higher attention
- Distant tokens are penalized linearly
Key advantage:
- No additional positional embeddings required
- Extremely simple and memory-efficient Subscribe to our free AI newsletter now.
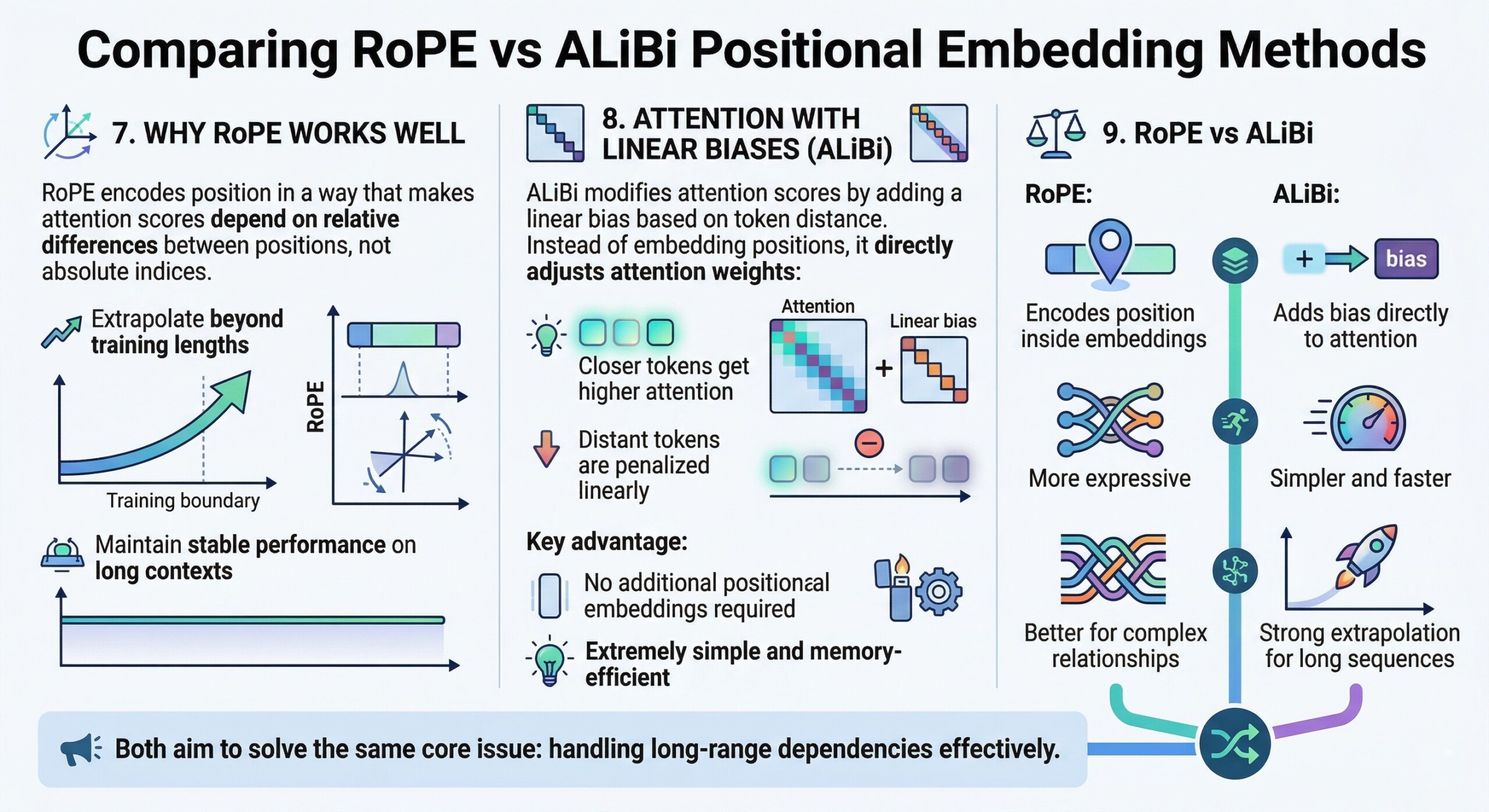
9. RoPE vs ALiBi
- RoPE:
- Encodes position inside embeddings
- More expressive
- Better for complex relationships
- ALiBi:
- Adds bias directly to attention
- Simpler and faster
- Strong extrapolation for long sequences
Both aim to solve the same core issue: handling long-range dependencies effectively.
10. Sequence representation in modern transformers
Modern architectures combine:
- Token embeddings
- Positional encoding (RoPE or ALiBi)
- Multi-head attention
This enables models to represent sequences as context-aware vector spaces, where meaning depends on both content and position. Upgrade your AI-readiness with our masterclass.
Conclusion
Positional encoding is a foundational component of transformer models, enabling them to understand sequence order despite their parallel architecture. While early approaches relied on absolute positions, modern systems increasingly favour relative methods for better scalability and generalization.
Techniques like RoPE and ALiBi represent a shift toward more efficient and flexible sequence modeling. RoPE integrates position directly into vector geometry, while ALiBi simplifies the process by biasing attention.
As models continue to scale and handle longer contexts, the evolution of positional encoding will remain central to improving performance, efficiency, and real-world applicability.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



