State Space Models (S4, Mamba) & Sequence Alternatives

State Space Models (S4, Mamba) & Sequence Alternatives
Linear-time sequence modelling; Transformer alternatives
Introduction
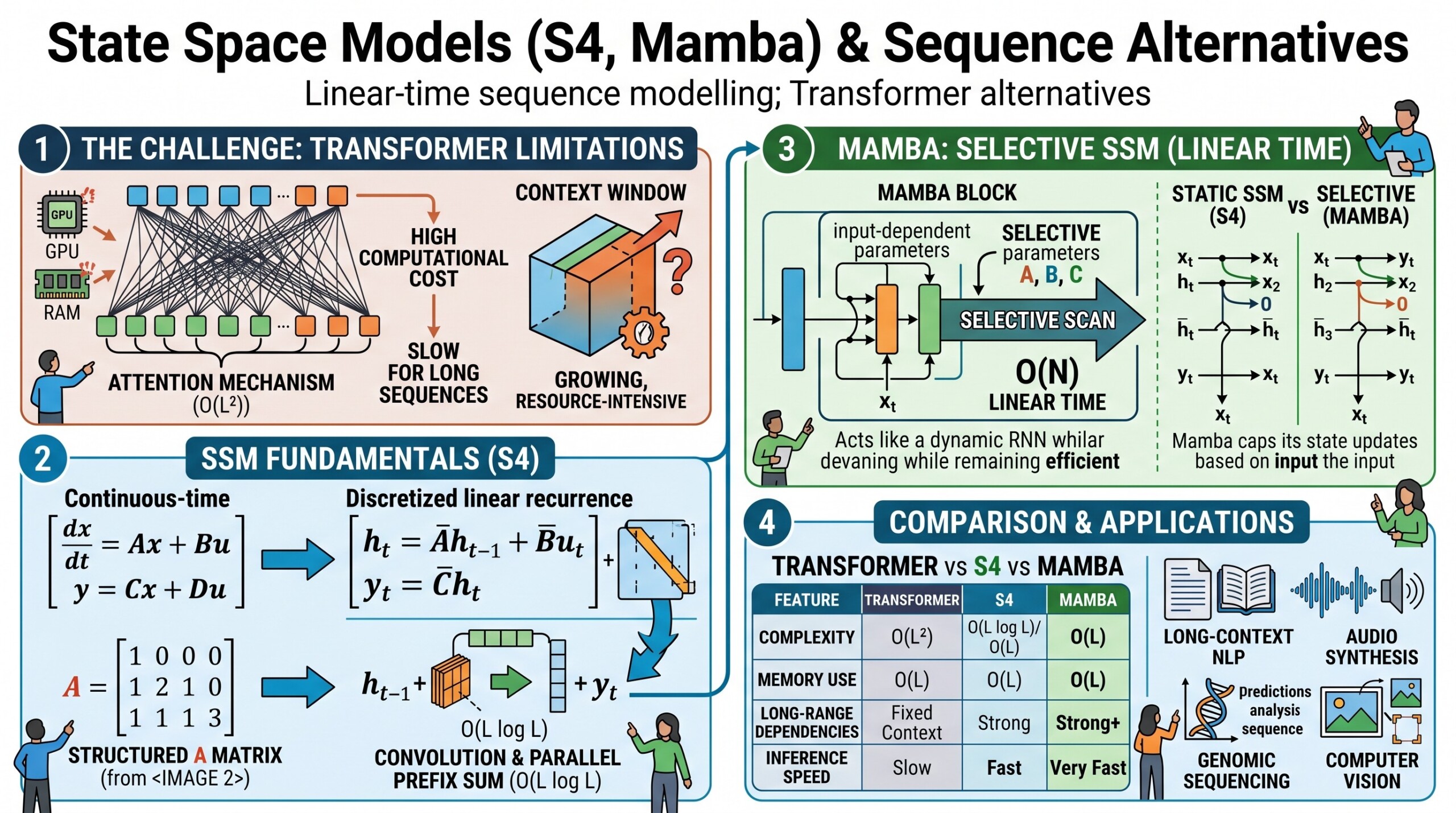
Modern artificial intelligence systems often need to understand sequences: words in a sentence, frames in a video, sensor readings over time, DNA bases in a genome, audio waveforms, financial time series, user actions, medical records, and many more. For the last several years, the Transformer has dominated sequence modelling because its attention mechanism can compare every token with every other token. This gives it strong contextual reasoning power, but it also creates a major limitation: standard attention has quadratic cost with sequence length, meaning longer sequences become increasingly expensive in memory and computation.
This is where State Space Models, especially S4 and Mamba, become important. They belong to a family of models that try to process long sequences more efficiently, often in linear time with respect to sequence length. Instead of explicitly comparing every token with every other token, they maintain and update a hidden state as the sequence progresses. S4 showed that structured state space models could handle very long-range dependencies efficiently, while Mamba improved the idea by making the state updates input-dependent, allowing the model to selectively remember or forget information. S4 was introduced as an efficient structured state space sequence model for long-range modelling, and Mamba later proposed selective state spaces with linear scaling and strong performance across language, audio, and genomics.
The key lecture question is: Can we build sequence models that preserve much of the Transformer’s power while avoiding its quadratic bottleneck? State Space Models are one of the most serious answers to that question.
Let’s dive deep into the topic now.
1. The sequence modelling problem: why Transformers became dominant
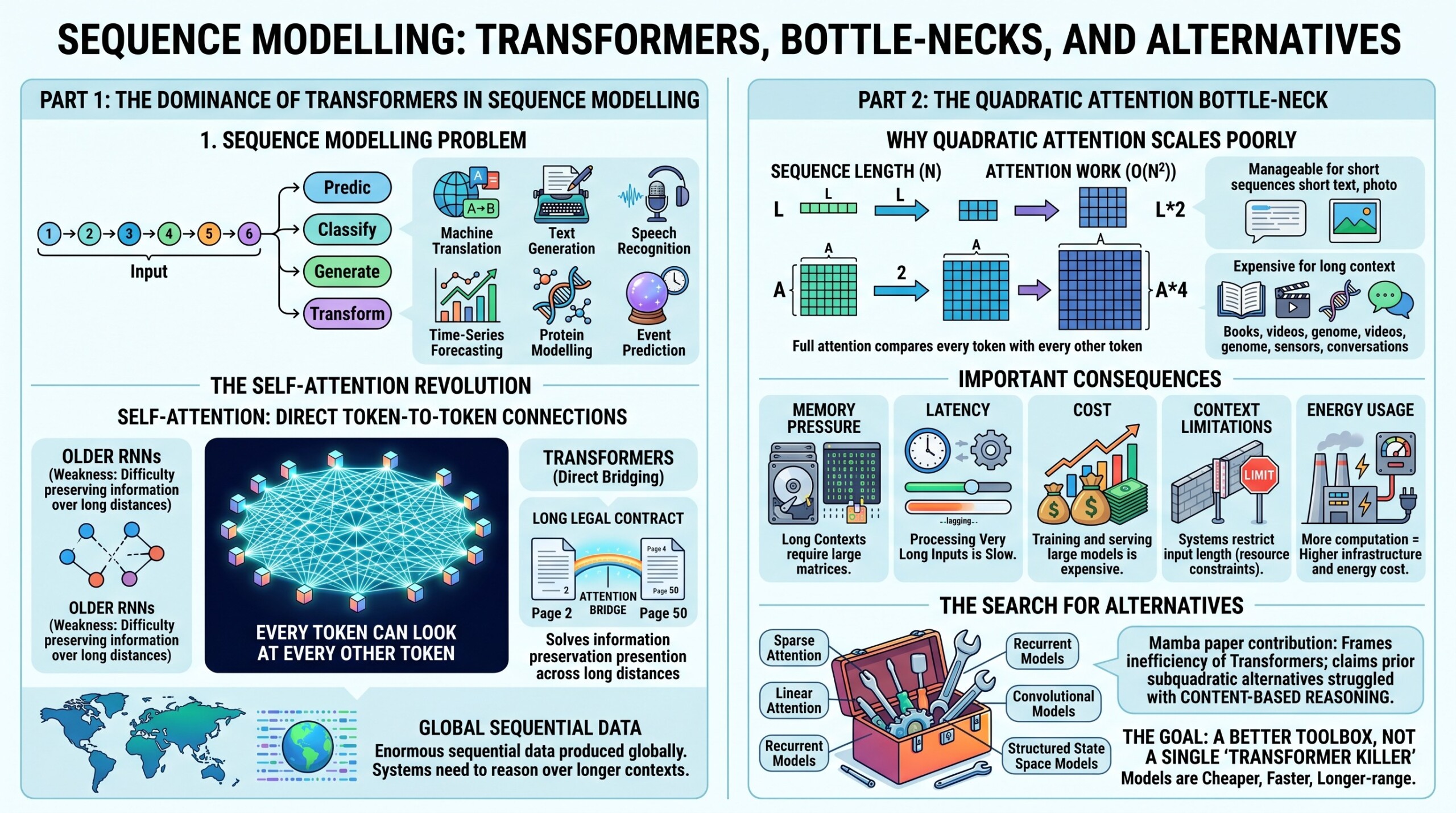
A sequence model takes an ordered input and tries to predict, classify, generate, or transform it. Examples include machine translation, text generation, speech recognition, time-series forecasting, protein modelling, and event prediction.
The Transformer became dominant because of self-attention. In self-attention, every token can directly look at every other token. This solves a major weakness of older recurrent neural networks, which had difficulty preserving information across long distances. For example, in a long legal contract, the meaning of a clause on page 50 may depend on a definition on page 2. Attention can create a direct bridge between these positions.
However, this power comes with a cost. If a sequence has n tokens, full attention roughly compares every token with every other token, producing n × n interactions. This is manageable for short sequences but becomes expensive for long-context applications such as full books, long videos, genomic sequences, high-frequency sensor streams, or long conversations.
The challenge is therefore not merely academic. The world produces enormous sequential data, and AI systems increasingly need to reason over longer and longer contexts.
2. Why quadratic attention is a bottleneck
The standard Transformer attention mechanism scales poorly as sequence length increases. Doubling the sequence length does not merely double the attention work; it can roughly quadruple it. This affects both training and inference.
Important consequences include:
- Memory pressure: Long contexts require large attention matrices.
- Latency: Processing very long inputs becomes slow.
- Cost: Training and serving large models becomes expensive.
- Context limitations: Many systems restrict input length because of resource constraints.
- Energy usage: More computation means higher infrastructure and energy cost.
This is why researchers have explored alternatives such as sparse attention, linear attention, recurrent models, convolutional models, and structured state space models. The Mamba paper explicitly frames its contribution against the inefficiency of Transformers and prior subquadratic alternatives, arguing that many earlier efficient models struggled to match attention on language because they lacked strong content-based reasoning.
The search is not for “one model to kill Transformers,” but for a better toolbox: models that are cheaper, faster, longer-range, and suitable for different data types. An excellent collection of learning videos awaits you on our Youtube channel.
3. What is a State Space Model?
A State Space Model is a mathematical system that describes how an internal state evolves over time in response to inputs. The basic idea comes from control theory, signal processing, and dynamical systems.
At a high level:
- There is an input sequence.
- The model maintains a hidden state.
- Each new input updates that hidden state.
- The output is produced from the current state.
A simplified form is:
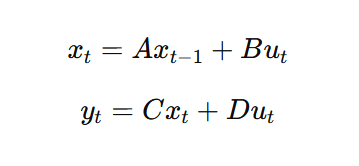
Where:

In plain language, the model asks: What should I remember from the past, how should I update that memory with the new input, and what output should I produce now?
This gives SSMs a natural advantage for long sequences. They do not need to create all pairwise token comparisons. Instead, they update a compact state across the sequence.
4. S4: Structured State Space Models
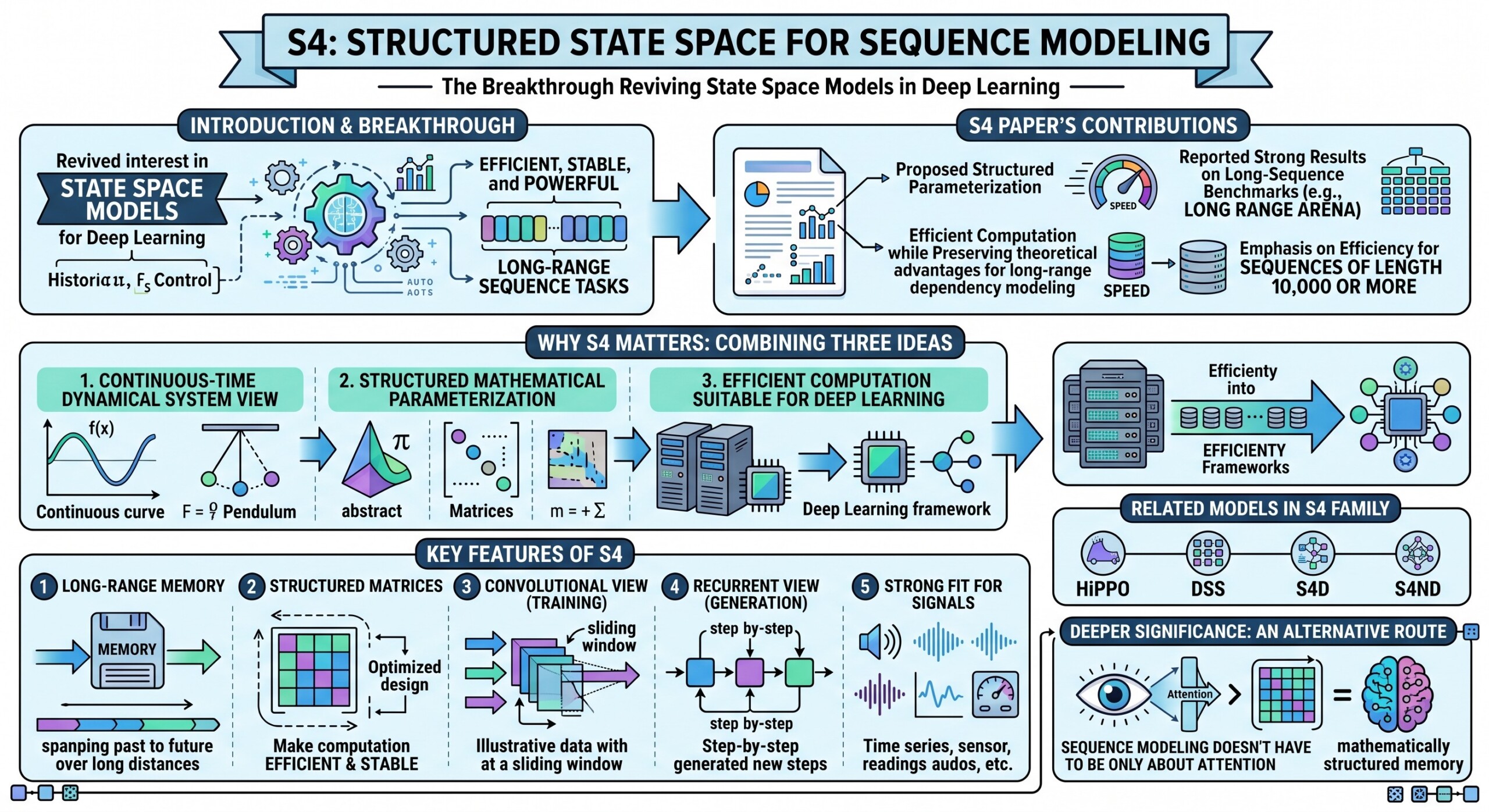
S4, or Structured State Space for Sequence Modeling, was one of the major breakthroughs that revived interest in state space models for deep learning. It showed that state space models could be made efficient, stable, and powerful for long-range sequence tasks.
The S4 paper proposed a structured parameterization that made state space computation much more efficient while preserving theoretical advantages for long-range dependency modelling. It reported strong results on long-sequence benchmarks, including Long Range Arena tasks, and emphasized efficiency for sequences of length 10,000 or more.
S4 matters because it combined three ideas:
- A continuous-time dynamical system view
- A structured mathematical parameterization
- Efficient computation suitable for deep learning
Key features of S4
- Long-range memory: S4 is designed to preserve information over long distances.
- Structured matrices: It uses carefully designed state matrices to make computation efficient and stable.
- Convolutional view: During training, the model can often be implemented efficiently as a convolution over the sequence.
- Recurrent view: During generation or step-by-step processing, it can work like a recurrent model.
- Strong fit for signals: It performs especially well on continuous or signal-like data such as audio, time series, and sensor streams.
The official S4 implementation repository also describes S4 as part of a family of structured state space models, including related models such as HiPPO, DSS, S4D, and S4ND.
S4’s deeper significance is that it showed sequence modelling did not have to be only about attention. There was another route: mathematically structured memory. A constantly updated Whatsapp channel awaits your participation.
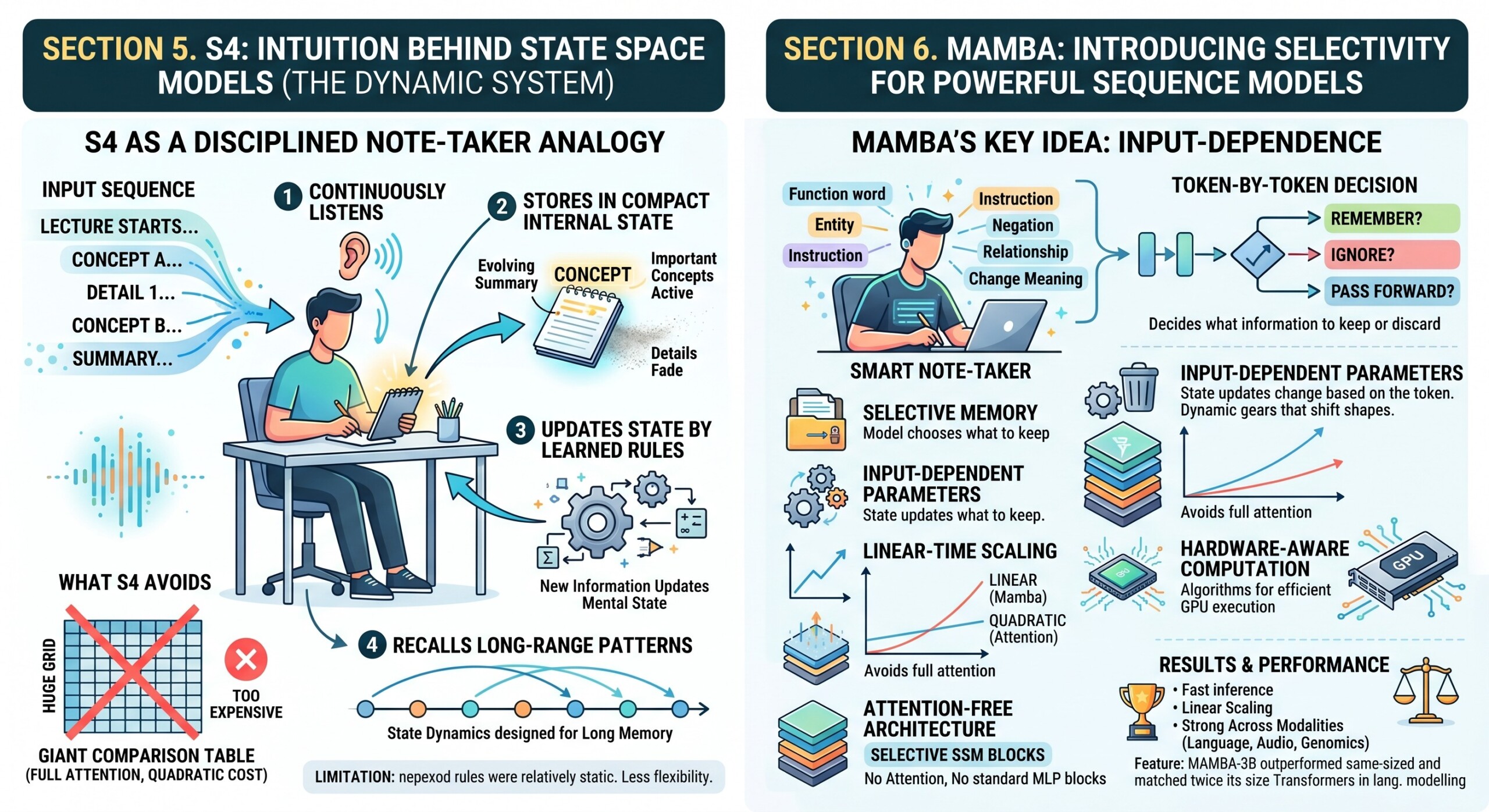
5. The intuition behind S4: memory as a dynamic system
To understand S4 intuitively, imagine listening to a long lecture. You do not remember every word with equal weight. Instead, your mind maintains an evolving summary. Important concepts remain active; less important details fade. New information updates your mental state.
S4 tries to model something similar. It does not compare every word to every other word. It builds a dynamic representation of the past and updates it as new input arrives.
A useful classroom analogy
Think of S4 as a very disciplined note-taker:
- It continuously listens to the incoming sequence.
- It stores important information in a compact internal state.
- It updates that state according to learned rules.
- It can recall long-range patterns because its state dynamics are designed for long memory.
- It avoids writing a giant comparison table between every pair of tokens.
This makes S4 attractive for long sequences where full attention is too expensive.
However, S4 also had a limitation: the transition rules were relatively static. The model was efficient, but it did not have the same kind of flexible, content-based routing that attention provides. That limitation helped motivate Mamba.
6. Mamba: selective state space models
Mamba is a newer architecture that builds on the state space tradition but introduces a key idea: selectivity.
In earlier SSMs, the state update parameters were more fixed. Mamba makes parts of the state space model depend on the input itself. This allows the model to decide, token by token, what to remember, what to ignore, and what to pass forward. The Mamba paper identifies the static nature of earlier SSMs as a weakness, especially for discrete and information-dense data such as text, and proposes input-dependent selective state spaces to address it.
This is crucial. Language is not just a smooth signal. Some words are function words, some are entities, some are instructions, some are negations, some define relationships, and some completely change the meaning of a sentence. A good language model must treat different tokens differently.
What Mamba adds
- Selective memory: The model can choose which information to keep or discard.
- Input-dependent parameters: State updates can change depending on the token.
- Linear-time scaling: It avoids full quadratic attention.
- Hardware-aware computation: Mamba uses algorithms designed for efficient modern GPU execution.
- Attention-free architecture: The original Mamba architecture removes attention and even standard MLP blocks in favor of selective SSM blocks.
The Mamba paper reports fast inference, linear scaling in sequence length, and strong performance across modalities such as language, audio, and genomics. It also reports that Mamba-3B outperformed Transformers of the same size and matched Transformers twice its size in language modelling evaluations. Excellent individualised mentoring programmes available.
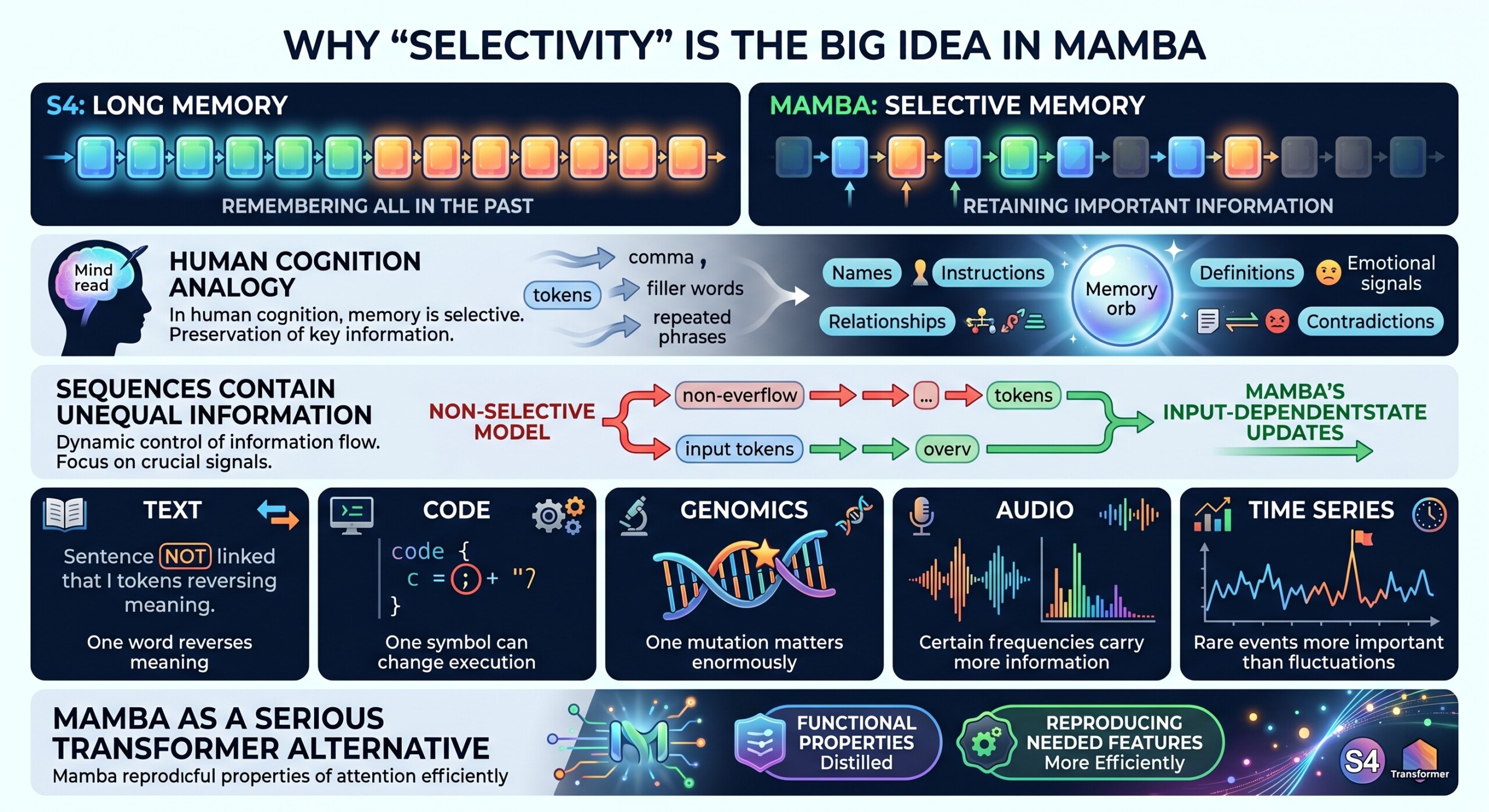
7. Why “selectivity” is the big idea in Mamba
The simplest way to understand Mamba is this:
S4 gave sequence models long memory. Mamba gave them selective memory.
In human cognition, memory is selective. When reading a paragraph, you do not store every comma, filler word, and repeated phrase with equal importance. You preserve names, instructions, causal relationships, definitions, emotional signals, and contradictions.
Mamba tries to introduce this kind of selective behavior into state space modelling.
Selectivity helps because sequences contain unequal information
- In text, one word like “not” can reverse meaning.
- In code, one symbol can change execution.
- In genomics, one mutation can matter enormously.
- In audio, certain frequencies or transitions carry more information.
- In time series, rare events may be more important than normal fluctuations.
A non-selective model may process all tokens too uniformly. Mamba’s input-dependent state updates allow it to dynamically control information flow.
This is one reason Mamba attracted attention as a serious Transformer alternative. It does not simply say, “Attention is expensive, so let us remove it.” It asks, “What functional property of attention is necessary, and can we reproduce some of it more efficiently?”
8. Comparing Transformers, S4, and Mamba
Transformers, S4, and Mamba all model sequences, but they do so using different philosophies.
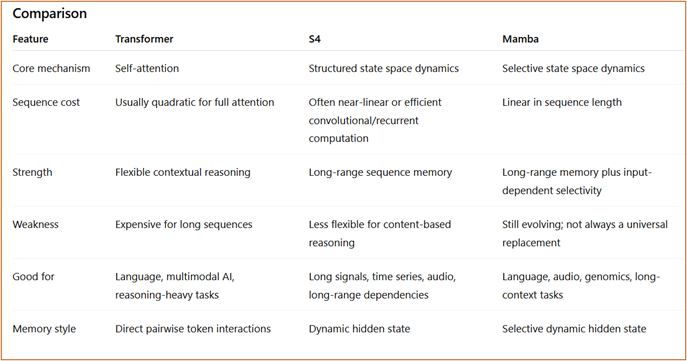
Important teaching distinction
- Attention asks: “Which previous tokens should this token look at?”
- SSMs ask: “How should the hidden state evolve as the sequence arrives?”
- Mamba asks: “How should the model selectively update memory depending on the current input?”
This distinction is central to understanding why these models are not merely engineering tricks. They represent different theories of sequence modelling. Subscribe to our free AI newsletter now.
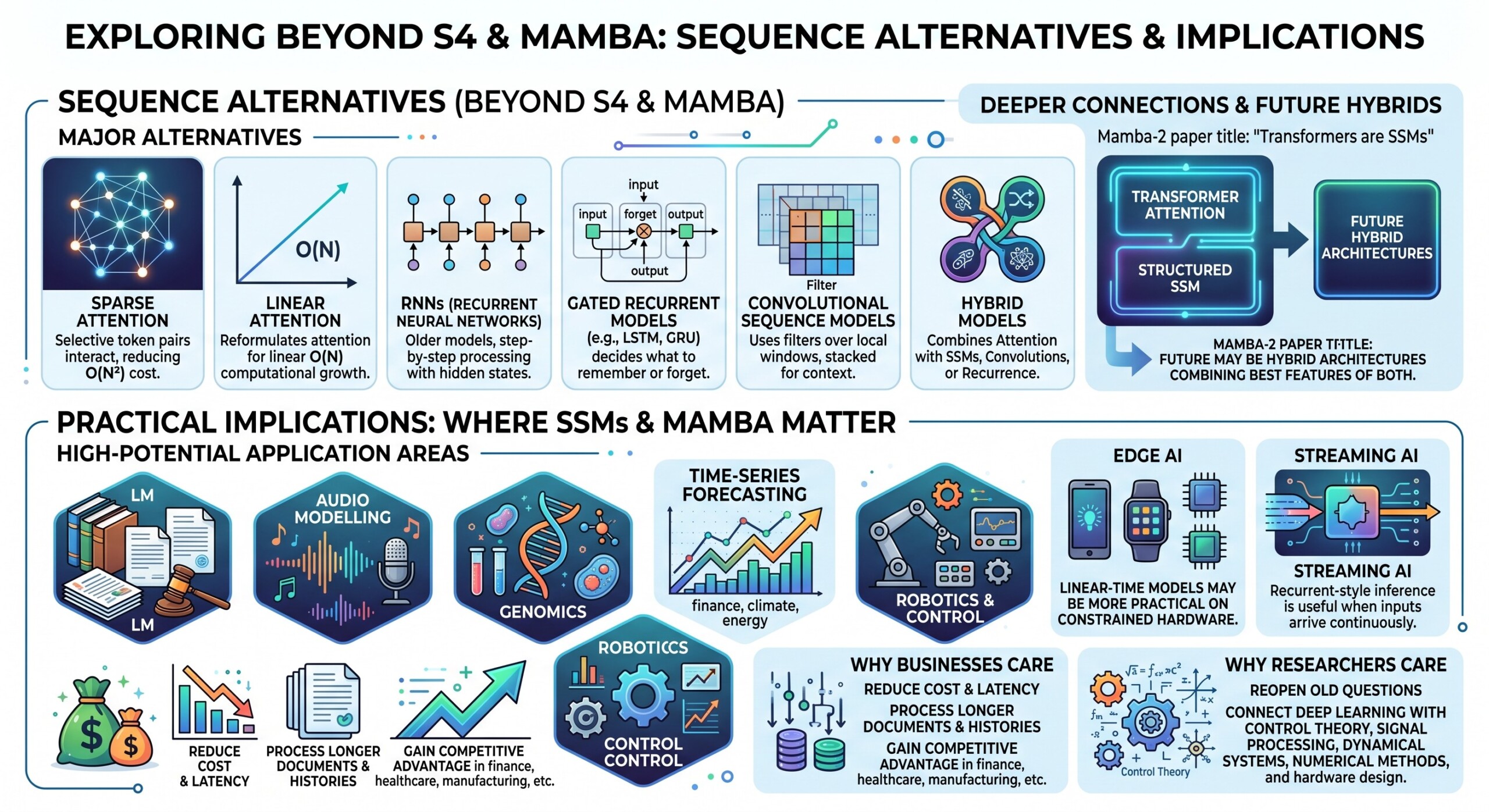
9. Other sequence alternatives beyond S4 and Mamba
State Space Models are not the only Transformer alternatives. Several other approaches try to reduce the cost of sequence modelling.
Major alternatives
- Sparse attention: Instead of every token attending to every other token, only selected token pairs interact.
- Linear attention: Reformulates attention so that computation grows linearly rather than quadratically.
- Recurrent neural networks: Process sequences step by step with hidden states; older but still conceptually important.
- Gated recurrent models: Use gates to decide what to remember or forget, as in LSTM and GRU.
- Convolutional sequence models: Use filters over local windows and stack layers to capture longer context.
- Hybrid models: Combine attention with SSMs, convolutions, or recurrence.
Recent work such as Mamba-2 explores deeper connections between Transformers and SSMs. The Mamba-2 paper, titled Transformers are SSMs, presents a framework connecting structured state space models and attention-like mechanisms, and uses that connection to design a new architecture at the intersection of SSMs and structured attention.
This is important because the future may not be “Transformer versus SSM.” It may be hybrid architectures that combine the best features of both.
10. Practical implications: where SSMs and Mamba matter
State Space Models are especially important when sequences are long, dense, or continuous. They are also valuable when inference cost matters.
High-potential application areas
- Long-context language modelling: Handling books, legal documents, research papers, and long conversations.
- Audio modelling: Audio is naturally sequential and often very long.
- Genomics: DNA and protein sequences can be extremely long.
- Time-series forecasting: Finance, climate, IoT, manufacturing, energy, and healthcare data.
- Robotics and control: State space ideas have natural roots in control systems.
- Edge AI: Linear-time models may be more practical on constrained hardware.
- Streaming AI: Recurrent-style inference is useful when inputs arrive continuously.
Why businesses should care
For enterprises, the value is not theoretical. Efficient sequence models can reduce cost and latency. They can make it possible to process longer documents, longer customer histories, longer machine logs, and longer sensor streams. In sectors such as finance, healthcare, manufacturing, telecom, and education, the ability to analyze long sequences efficiently can become a competitive advantage.
Why researchers should care
For researchers, SSMs reopen old questions in new ways. They connect deep learning with control theory, signal processing, dynamical systems, numerical methods, and hardware-aware algorithm design. This makes the field intellectually rich and practically powerful. Upgrade your AI-readiness with our masterclass.
Conclusion
State Space Models represent one of the most important developments in modern sequence modelling. The Transformer remains extremely powerful, especially because attention provides flexible token-to-token interaction. But full attention becomes expensive as sequences grow. This has created a strong need for alternatives that can process long contexts more efficiently.
S4 showed that structured state space models could model long-range dependencies with impressive efficiency. It brought rigorous mathematical structure into deep sequence modelling and demonstrated that long memory could be achieved without full attention. Mamba then advanced the field by adding selectivity: the ability to update memory depending on the input token. This made SSMs more suitable for information-dense data such as language and positioned Mamba as one of the most serious linear-time alternatives to Transformers.
The future is unlikely to be a simple replacement story. Transformers, SSMs, Mamba-like models, sparse attention, linear attention, recurrent systems, and hybrid architectures will all have roles. The key lesson is that sequence modelling is entering a new phase: from brute-force attention over all tokens to more efficient, selective, structured, and hardware-aware models.
Transformers taught AI to look everywhere. State Space Models teach AI to remember efficiently. Mamba teaches AI to remember selectively.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



