Scaling Laws & Compute-Optimal Training

Scaling Laws & Compute-Optimal Training
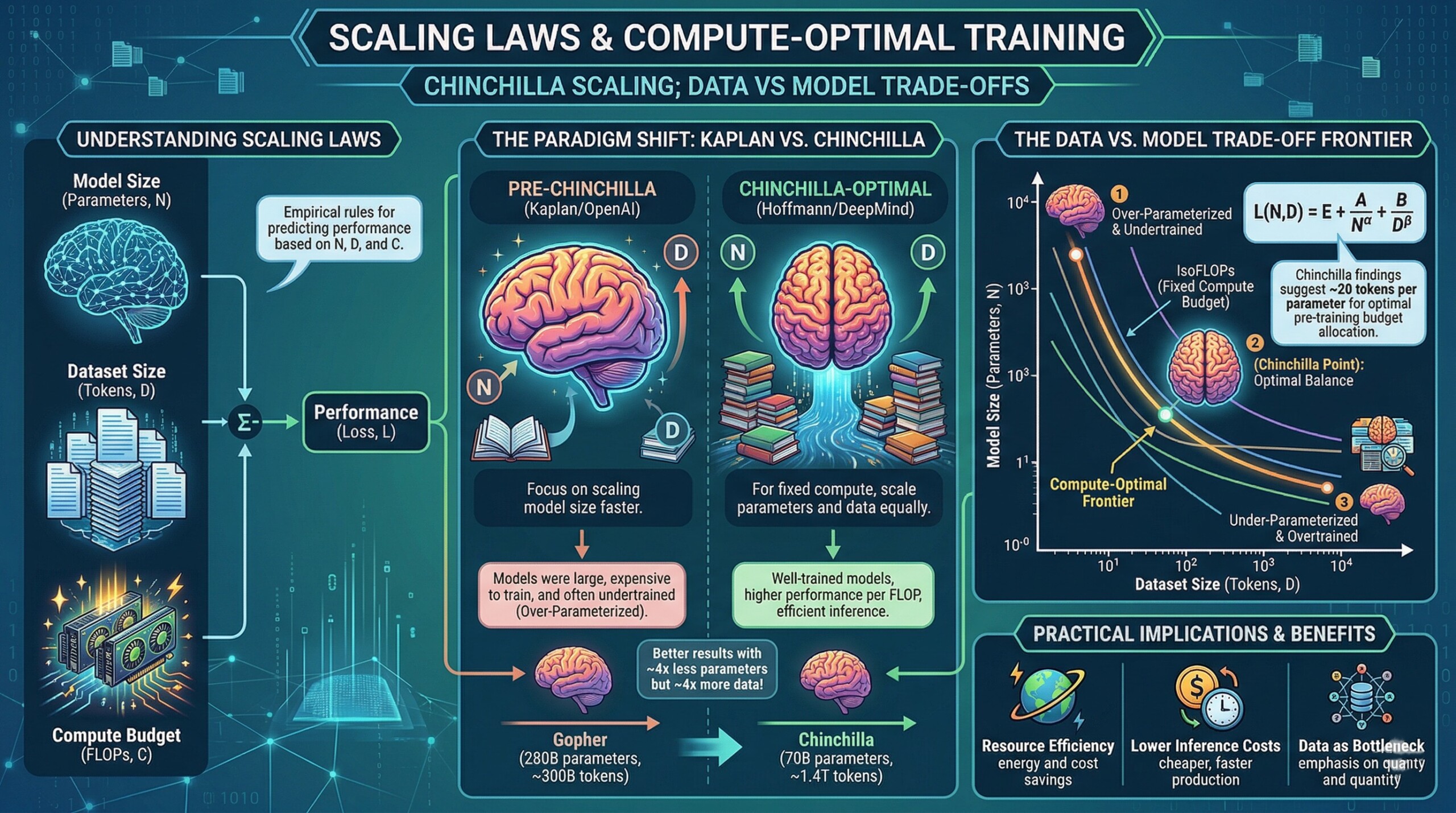
Chinchilla scaling; Data vs model trade-offs
Introduction
Over the past decade, the rapid advancement of artificial intelligence – especially large language models (LLMs) – has been driven by a simple but powerful idea: scale matters. Larger models, trained on more data with more compute, tend to perform better. This observation led researchers to formalize scaling laws, mathematical relationships that predict how performance improves as we increase model size, dataset size, and computational resources.
Early breakthroughs in scaling were demonstrated by models like GPT-3, which showed that increasing parameters into the hundreds of billions could unlock impressive capabilities such as few-shot learning and emergent reasoning. However, this approach came with a major drawback: it was extremely compute-intensive and inefficient. Researchers began to question whether simply making models bigger was the most effective path forward.
This led to a pivotal shift in thinking with the introduction of compute-optimal training, most notably through the Chinchilla model. Instead of blindly scaling parameters, Chinchilla demonstrated that balancing model size with the right amount of training data leads to far better performance for the same compute budget. This insight fundamentally changed how modern AI systems are designed and trained.
Let’s dive deep into the topic.
1. The core idea of Scaling Laws
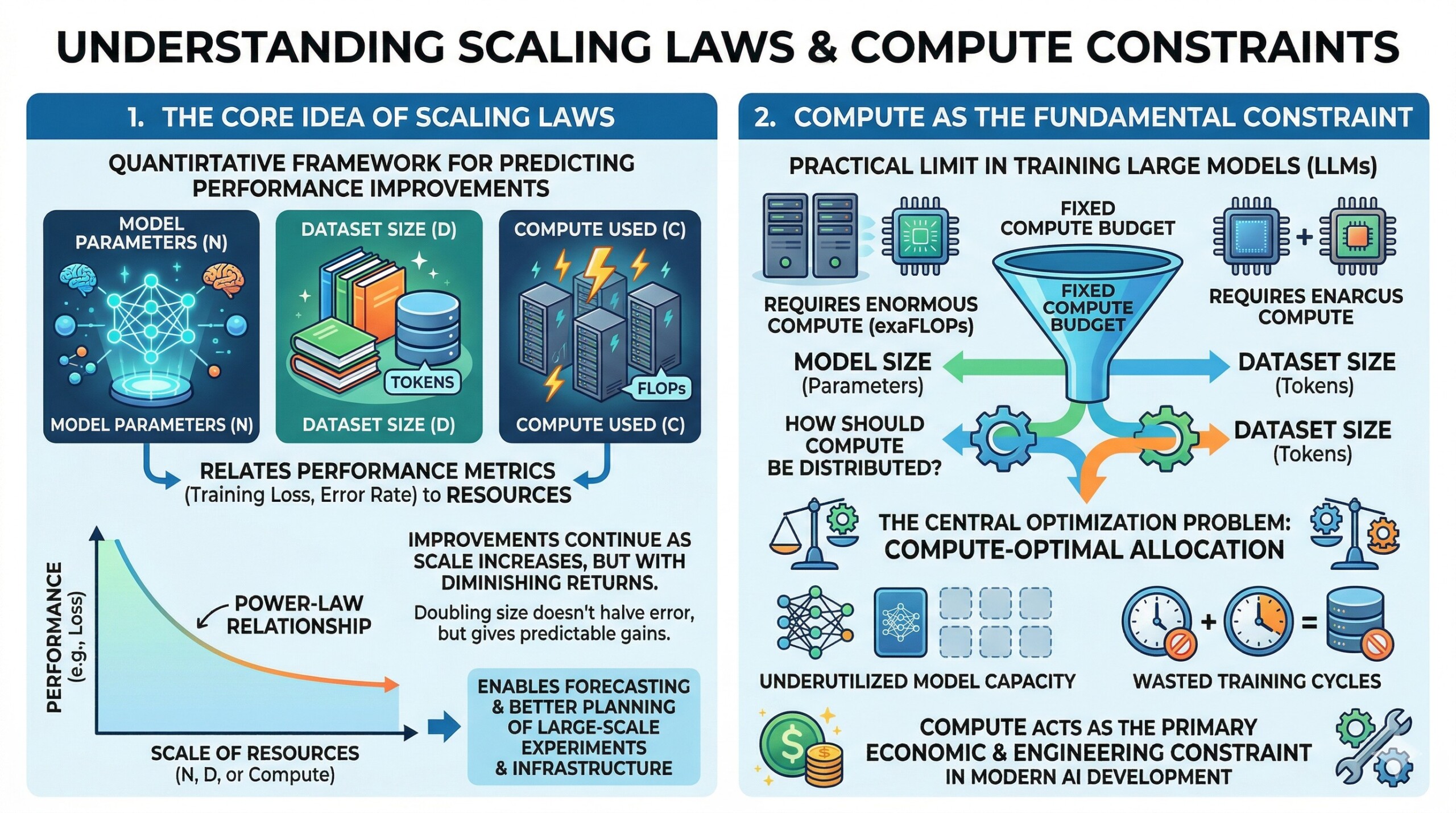
Scaling laws provide a quantitative framework for understanding how machine learning model performance improves as key resources are increased. Specifically, they relate performance metrics such as training loss or error rate to three primary variables:
- Model parameters (N)
- Dataset size (D)
- Compute used during training (C, often measured in FLOPs)
Empirical studies have shown that performance often follows a power-law relationship, where improvements continue as scale increases, but with diminishing returns. This means that doubling model size or data does not halve the error, but still yields predictable gains.
These laws are powerful because they allow researchers to forecast performance improvements before training, enabling better planning of large-scale experiments and infrastructure investments.
2. Compute as the fundamental constraint
In practice, the limiting factor in training large models is not theoretical understanding but available computational resources. Training modern LLMs requires enormous amounts of compute, often measured in exaFLOPs.
Given a fixed compute budget, the central optimization problem becomes:
How should compute be distributed between model size (parameters) and dataset size (tokens)?
This introduces the concept of compute-optimal allocation, where the goal is to maximize performance under a fixed compute constraint. Poor allocation leads to inefficiencies such as underutilized model capacity or wasted training cycles.
Thus, compute acts as the primary economic and engineering constraint in modern AI development. An excellent collection of learning videos awaits you on our Youtube channel.
3. Kaplan Scaling Laws (early insight)
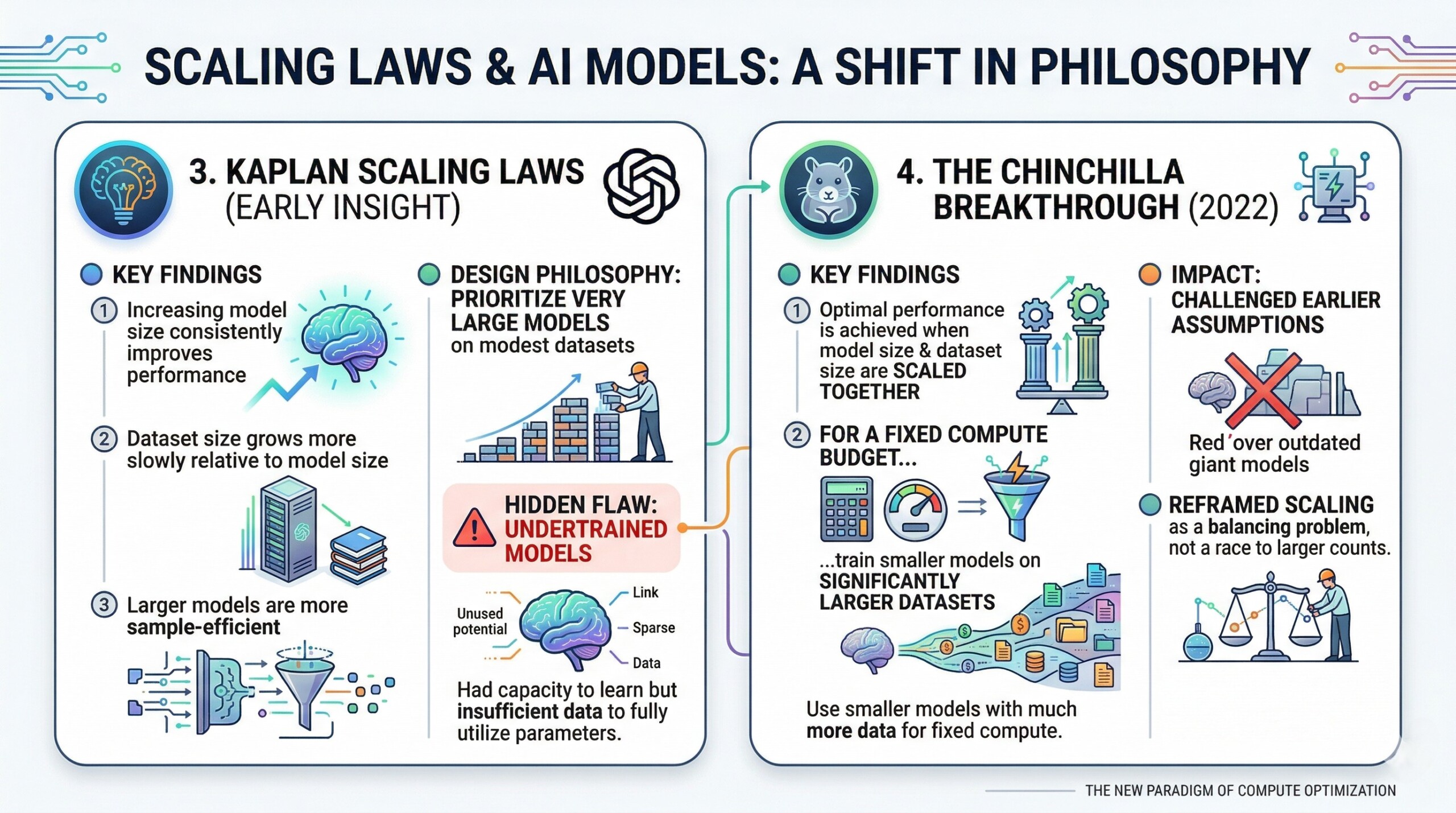
Early influential work, such as the OpenAI scaling laws (Kaplan et al.), suggested that:
- Increasing model size consistently improves performance
- Dataset size grows more slowly relative to model size
- Larger models are more sample-efficient
This led to a design philosophy where researchers prioritized very large models trained on relatively modest datasets.
However, this approach had a hidden flaw: many of these large models were undertrained, meaning they had the capacity to learn more but were not exposed to sufficient data to fully utilize their parameters.
4. The Chinchilla breakthrough
The introduction of the Chinchilla model (2022) marked a major shift in scaling philosophy. Researchers demonstrated that:
- Optimal performance is achieved when model size and dataset size are scaled together
- For a fixed compute budget, it is better to train smaller models on significantly larger datasets
This finding directly challenged earlier assumptions and showed that many large models (including predecessors) were inefficiently trained.
Chinchilla reframed scaling as a balancing problem, not a race toward ever-larger parameter counts. A constantly updated Whatsapp channel awaits your participation.
5. The Chinchilla Scaling Rule
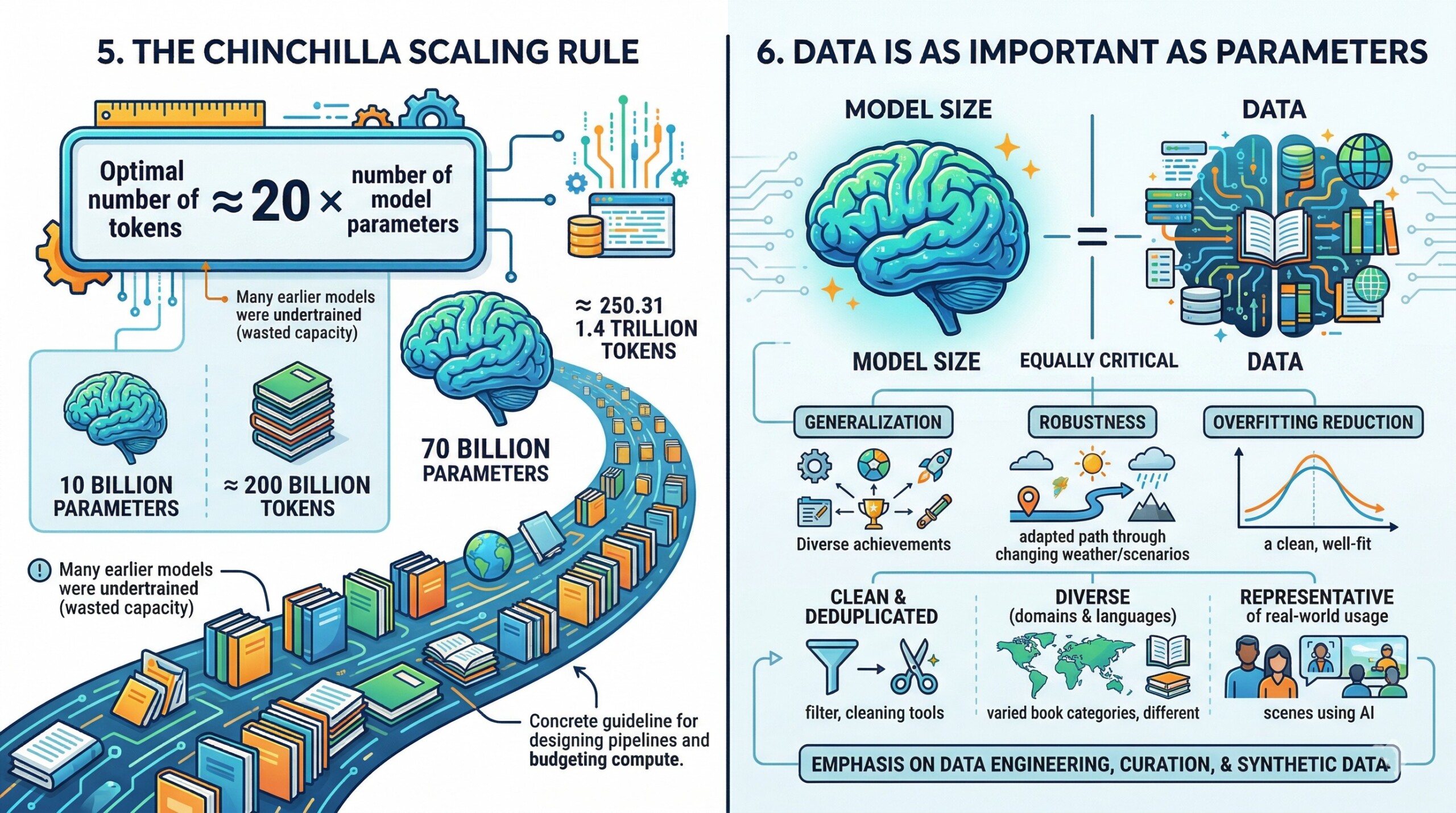
One of the most practical contributions of the Chinchilla work is a simple rule of thumb:
Optimal number of training tokens ≈ 20 × number of model parameters
For example:
- A 10 billion parameter model should be trained on roughly 200 billion tokens
- A 70 billion parameter model would ideally require ~1.4 trillion tokens
This rule highlights that many earlier models were trained on far fewer tokens than optimal, leading to wasted model capacity.
It provides a concrete guideline for designing training pipelines and budgeting compute effectively.
6. Data is as Important as Parameters
A major conceptual shift introduced by Chinchilla is the recognition that:
Data is not secondary to model size—it is equally critical
Increasing dataset size improves:
- Generalization across tasks
- Robustness to distribution shifts
- Reduction in overfitting
Moreover, data quality and diversity become crucial at scale. Simply increasing token count is not enough—datasets must be:
- Clean and deduplicated
- Diverse across domains and languages
- Representative of real-world usage
This has led to a growing emphasis on data engineering, curation, and synthetic data generation as core competencies in AI development. Excellent individualised mentoring programmes available.
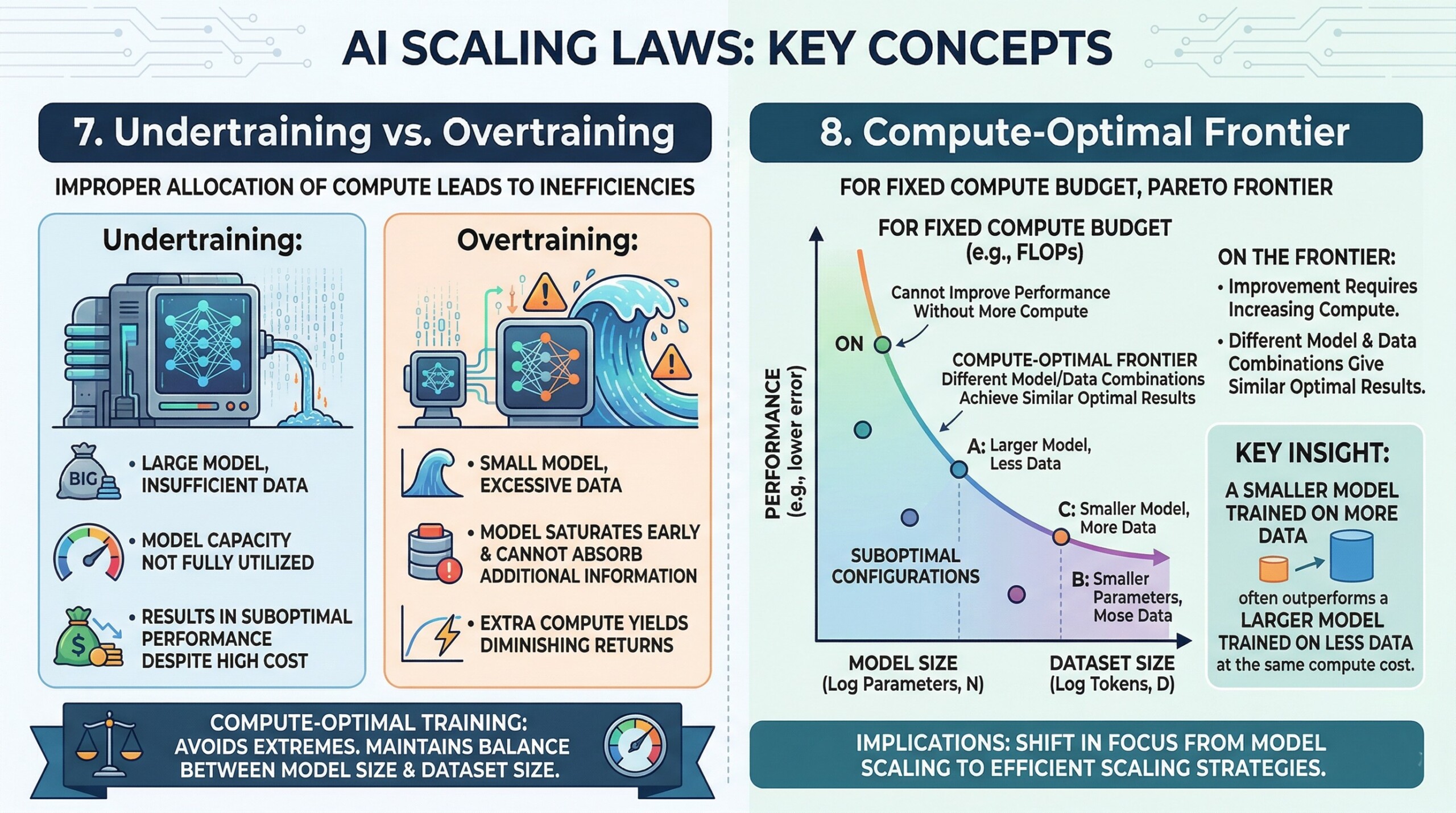
7. Undertraining vs Overtraining
Improper allocation of compute leads to two major inefficiencies:
- Undertraining:
- Large model, insufficient data
- Model capacity is not fully utilized
- Results in suboptimal performance despite high cost
- Overtraining:
- Small model, excessive data
- Model saturates early and cannot absorb additional information
- Extra compute yields diminishing returns
Compute-optimal training aims to avoid both extremes by maintaining the right balance between model size and dataset size, ensuring that every unit of compute contributes meaningfully to learning.
8. Compute-Optimal frontier
For any fixed compute budget, there exists a set of optimal configurations that balance parameters and data. This forms what can be thought of as a compute-optimal frontier (or Pareto frontier).
On this frontier:
- You cannot improve performance without increasing compute
- Different combinations of model size and data can achieve similar optimal results
A key insight is:
A smaller model trained on more data often outperforms a larger model trained on less data at the same compute cost.
This has major implications for both research and industry, as it shifts focus from model scaling to efficient scaling strategies. Subscribe to our free AI newsletter now.
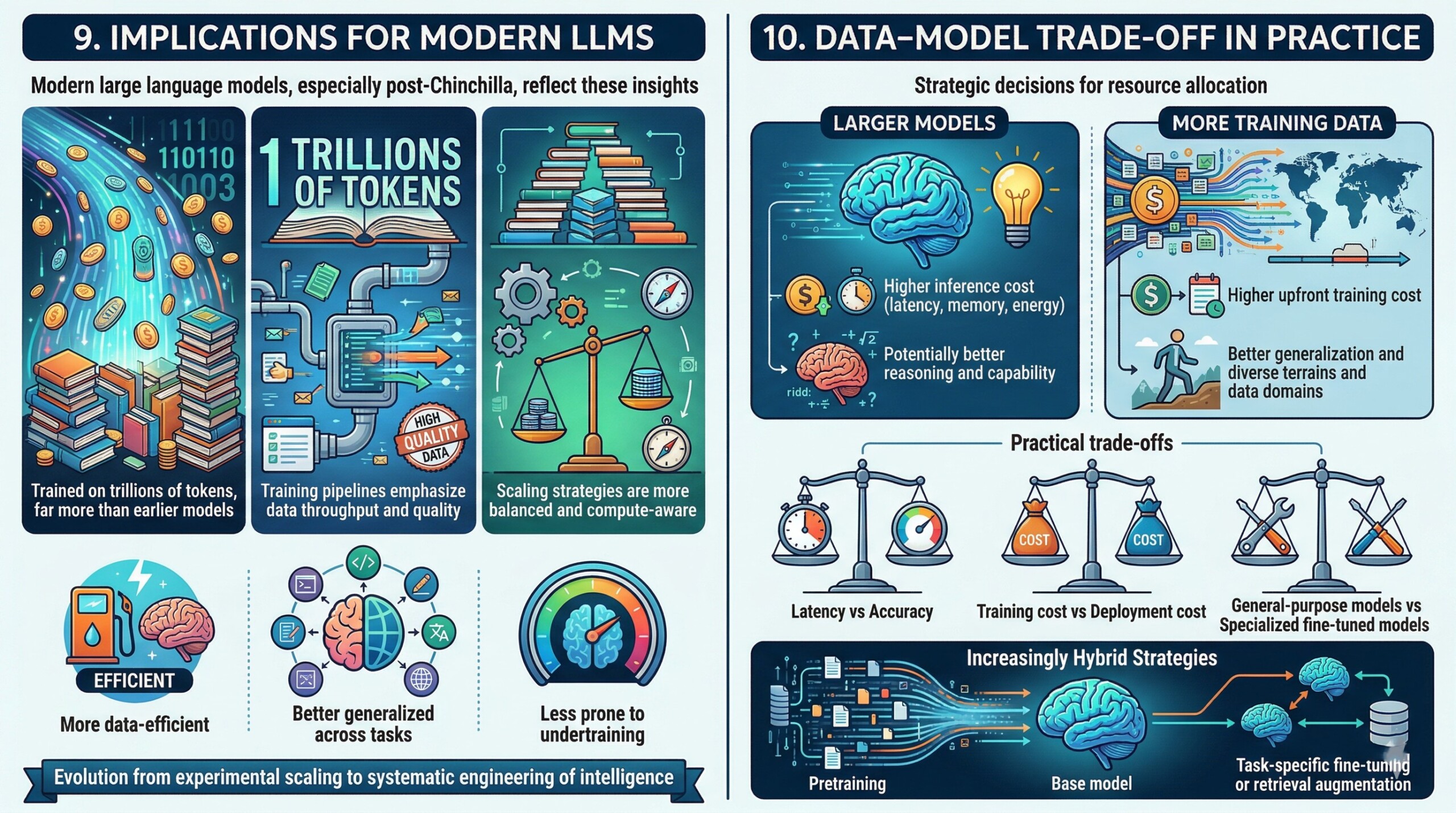
9. Implications for modern LLMs
Modern large language models, especially those developed after Chinchilla, reflect these insights:
- They are trained on trillions of tokens, far more than earlier models
- Training pipelines emphasize data throughput and quality
- Scaling strategies are more balanced and compute-aware
Even as models continue to grow in size, they are now:
- More data-efficient
- Better generalized across tasks
- Less prone to undertraining
This evolution represents a maturation of the field from experimental scaling to systematic engineering of intelligence.
10. Data–Model Trade-off in practice
In real-world deployments, organizations must make strategic decisions about how to allocate resources:
- Larger models:
- Higher inference cost (latency, memory, energy)
- Potentially better reasoning and capability
- More training data:
- Higher upfront training cost
- Better generalization and robustness
This leads to practical trade-offs such as:
- Latency vs accuracy (important for real-time applications)
- Training cost vs deployment cost
- General-purpose models vs specialized fine-tuned models
Increasingly, organizations are exploring hybrid strategies:
- Moderate-sized base models
- Extensive pretraining
- Task-specific fine-tuning or retrieval augmentation. Upgrade your AI-readiness with our masterclass.
Conclusion
The transition from brute-force scaling to compute-optimal training represents a fundamental shift in AI thinking. Intelligence is no longer viewed as a simple function of size, but as an emergent property of balanced scaling across parameters, data, and compute.
This shift has made AI systems:
- More efficient
- More accessible
- More scientifically grounded
As the field progresses, the next frontier may not be bigger models, but smarter scaling – leveraging better data, better training strategies, and better alignment between resources and objectives.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



