Mechanistic Interpretability in Transformers

Mechanistic Interpretability in Transformers
Circuits, neurons, feature superposition & reverse-engineering model behaviour
Introduction
Modern AI systems – especially transformer-based models – can generate human-like text, solve complex problems, and even reason across domains. Yet, despite their impressive capabilities, they often behave like “black boxes.” We can see what goes in and what comes out, but we don’t fully understand how they arrive at their answers.
This lack of transparency raises important questions. Why does a model make a specific mistake? How does it store knowledge? Can we trust its reasoning in high-stakes scenarios like healthcare, finance, or governance? These concerns have led researchers to explore a field known as mechanistic interpretability – a disciplined attempt to reverse-engineer neural networks and understand their inner workings.
Mechanistic interpretability focuses on identifying the actual computational structures inside models: circuits, neurons, and features. Instead of treating AI as magic, it treats it like an engineered system – one whose internal components can be mapped, analyzed, and understood. This approach is especially relevant for transformers, where attention mechanisms and layered representations create rich but complex internal dynamics.
Let’s dive deep into the topic
1. What is Mechanistic Interpretability
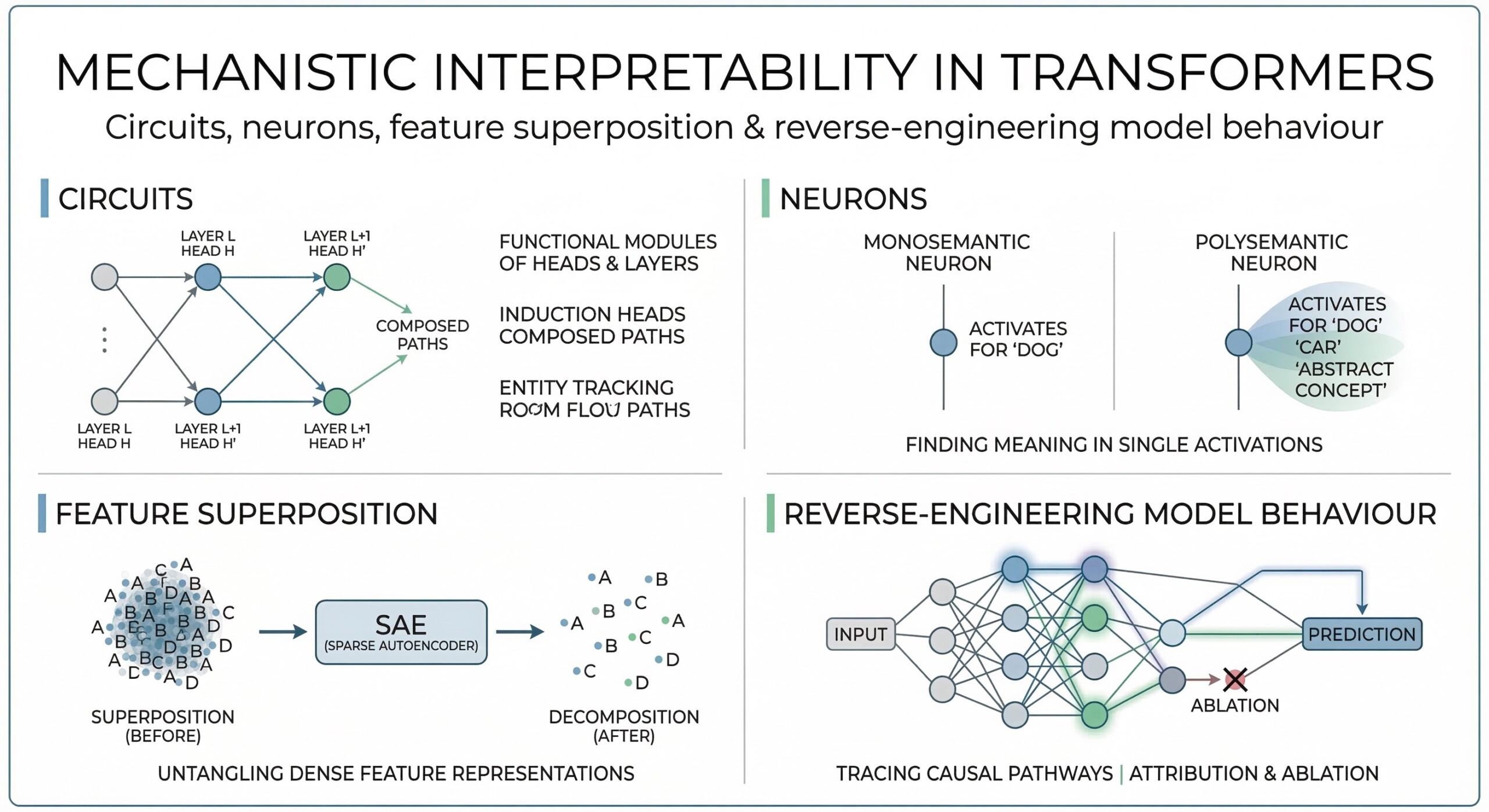
Mechanistic interpretability aims to uncover how a machine learning model computes its outputs by carefully analyzing its internal structure – such as weights, neuron activations, and the pathways through which information flows. Instead of treating the model as a black box, it focuses on opening it up and understanding the exact sequence of computations that lead from input to output.
In practice, this involves identifying which components inside the model are responsible for specific behaviours. Researchers examine how different layers transform representations, how attention mechanisms route information, and how groups of neurons (often called circuits) collaborate to perform tasks. The goal is to build a detailed, step-by-step understanding of the model’s internal logic.
Unlike traditional interpretability approaches – which often rely on correlations or visualizations – mechanistic interpretability seeks causal, mechanistic explanations. It aims to show what actually produces an output, often by intervening in the model and testing how changes affect results, similar to tracing how a circuit board functions internally.
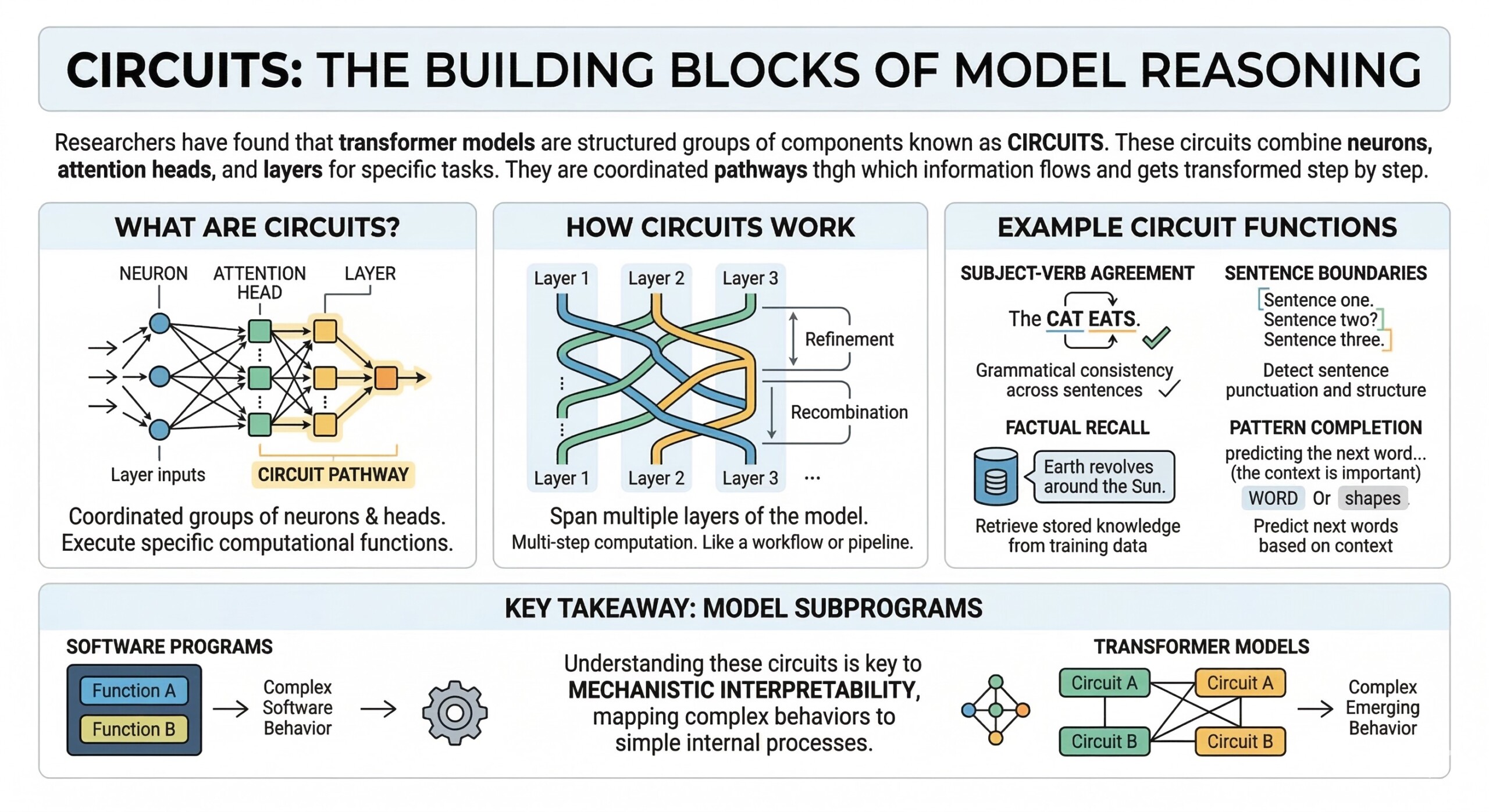
2. Circuits: The building blocks of model reasoning
Researchers have found that transformer models are not just collections of isolated neurons, but contain structured groups of components known as circuits. These circuits are combinations of neurons, attention heads, and layers that work together to perform specific computational tasks. Rather than a single unit handling a function, circuits operate as coordinated pathways through which information flows and gets transformed step by step.
Each circuit is responsible for a particular kind of reasoning or pattern recognition within the model. For example:
- A circuit might track subject-verb agreement, ensuring grammatical consistency across a sentence
- Another circuit may detect sentence boundaries or punctuation structure
- Some circuits specialize in factual recall, retrieving stored knowledge from training data
- Others handle pattern completion, such as predicting the next word in a sequence based on context
What makes circuits especially important is that they often span multiple layers of the model. Information is passed, refined, and recombined across these layers, forming a multi-step computation rather than a single operation. This means a circuit is less like a single switch and more like a pipeline or workflow inside the network.
In many ways, these circuits behave like subprograms embedded within the model. Just as a software program contains functions that handle specific tasks, transformer models contain circuits that execute distinct pieces of reasoning. Understanding these circuits is a key goal of mechanistic interpretability, as it allows researchers to map how complex behaviours emerge from simpler internal processes. An excellent collection of learning videos awaits you on our Youtube channel.
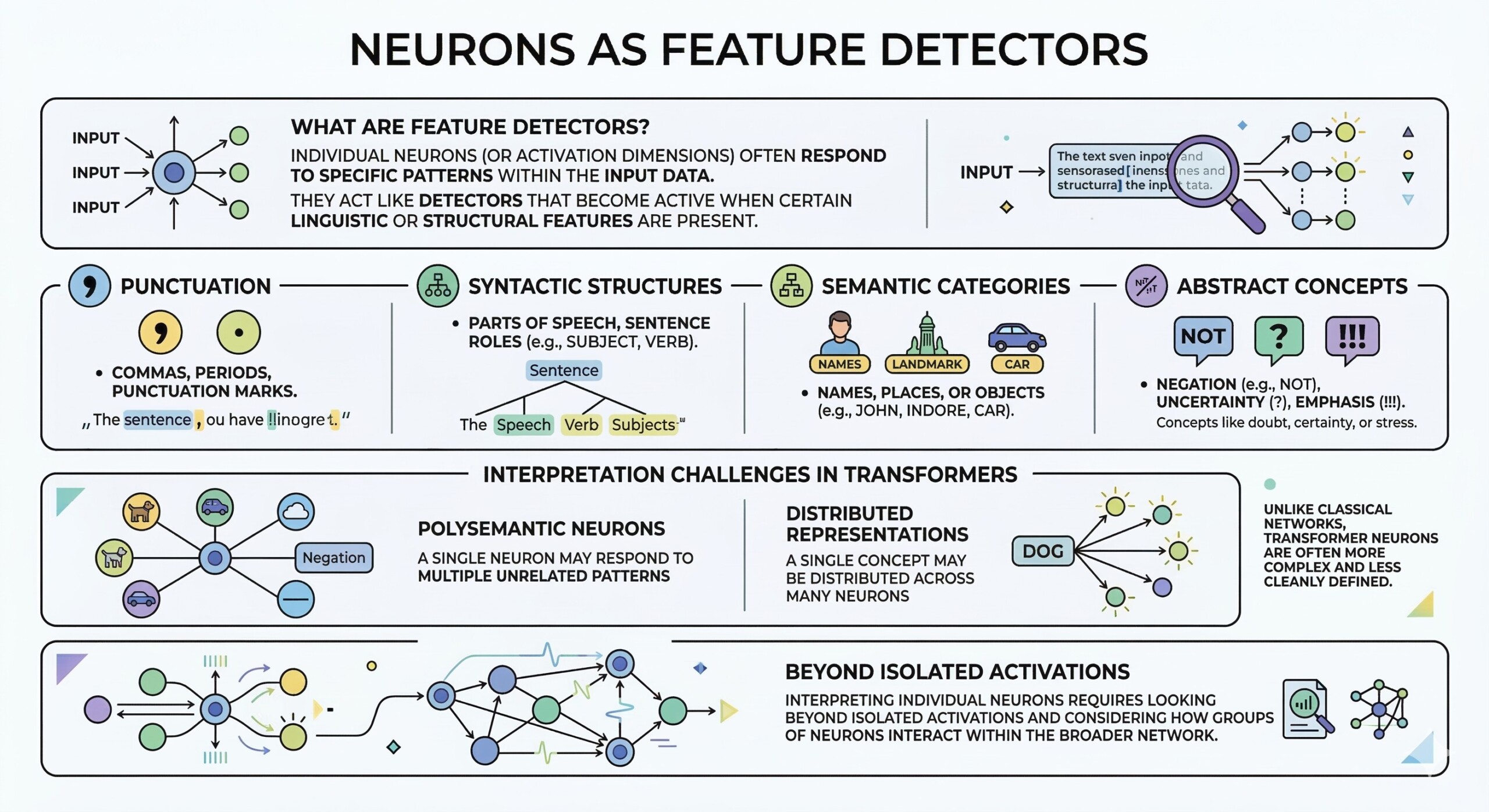
3. Neurons as feature detectors
Individual neurons (or dimensions in activations) often respond to specific patterns within the input data. These neurons can act like detectors that become active when certain linguistic or structural features are present. For example:
- Some neurons activate strongly for punctuation marks such as commas or periods
- Others respond to syntactic structures, like parts of speech or sentence roles
- Some are sensitive to semantic categories, such as names, places, or objects
- A few neurons even capture more abstract concepts like negation, uncertainty, or emphasis
This behaviour suggests that neurons can encode meaningful features of language and contribute to how the model understands and processes text. However, unlike classical neural networks – where neurons were sometimes easier to interpret as single-purpose units – transformer neurons are often more complex and less cleanly defined.
In many cases, a single neuron may respond to multiple unrelated patterns, or a single concept may be distributed across many neurons. This makes it difficult to assign a clear, one-to-one meaning to each neuron. As a result, interpreting individual neurons in transformers requires looking beyond isolated activations and considering how groups of neurons interact within the broader network.
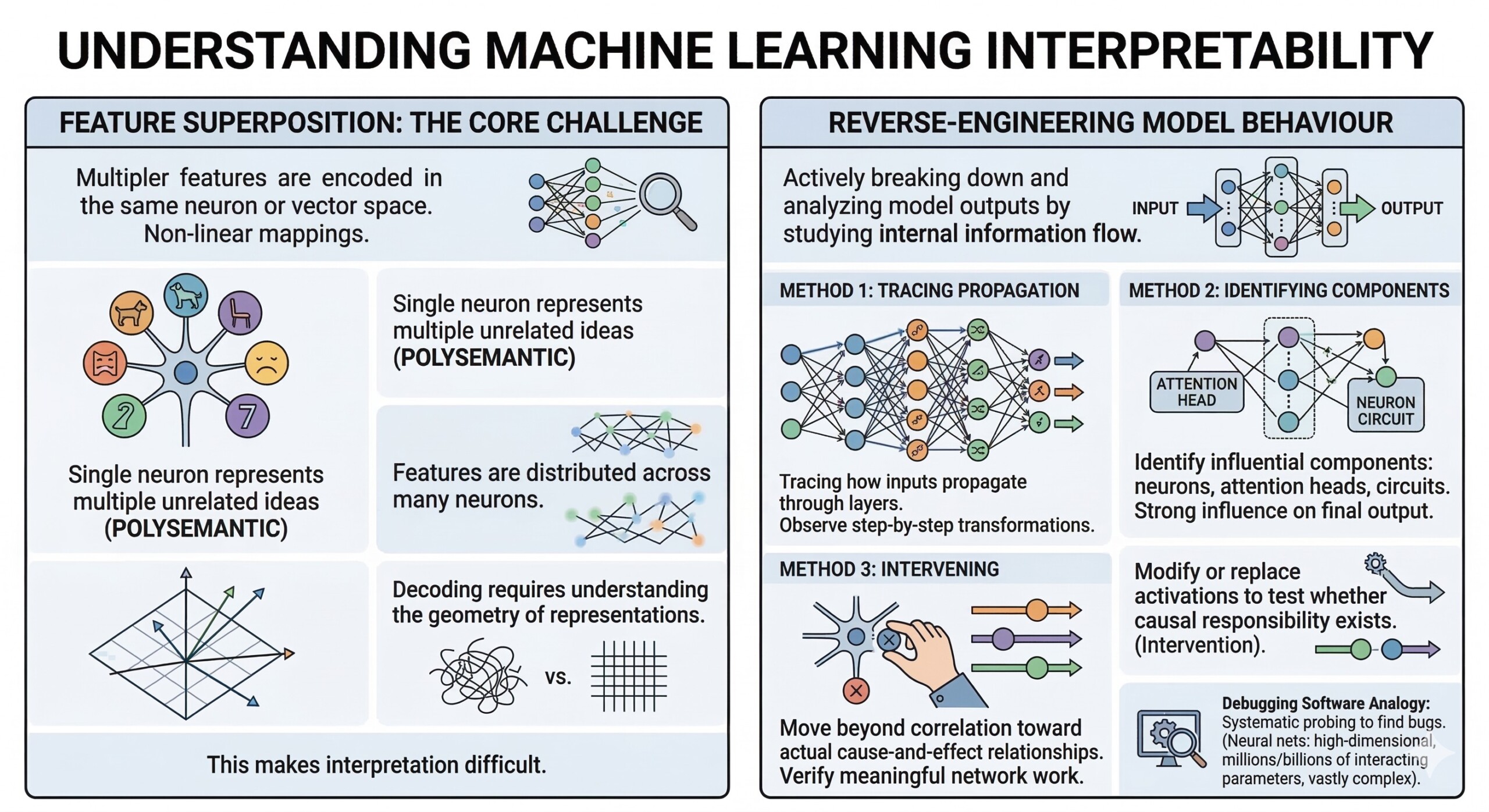
4. Feature Superposition: The core challenge
A key discovery is feature superposition – where multiple features are encoded in the same neuron or vector space. Instead of one neuron = one concept, transformers often compress many concepts into overlapping representations.
This makes interpretation difficult because:
- A single neuron may represent multiple unrelated ideas
- Features are distributed across many neurons
- Decoding requires understanding the geometry of representations A constantly updated Whatsapp channel awaits your participation.
5. Reverse-engineering model behaviour
Mechanistic interpretability involves actively breaking down and analyzing how a model produces its outputs by studying the flow of information inside it. Instead of only observing inputs and outputs, researchers trace the internal steps that connect the two. This includes:
- Tracing how inputs propagate through layers, observing how representations are transformed step by step
- Identifying which components – such as specific neurons, attention heads, or circuits – have the strongest influence on the final output
- Intervening in the model (for example, by modifying or replacing activations) to test whether certain components are causally responsible for a behaviour
These methods allow researchers to move beyond correlation and toward understanding actual cause-and-effect relationships within the model. By systematically probing and altering internal states, they can verify which parts of the network are doing meaningful work.
This process is similar to debugging software, where a developer steps through code to find where a bug or behaviour originates. However, in neural networks, the challenge is far greater because the system operates in a high-dimensional space with millions or billions of parameters interacting simultaneously, making the reverse-engineering process significantly more complex.
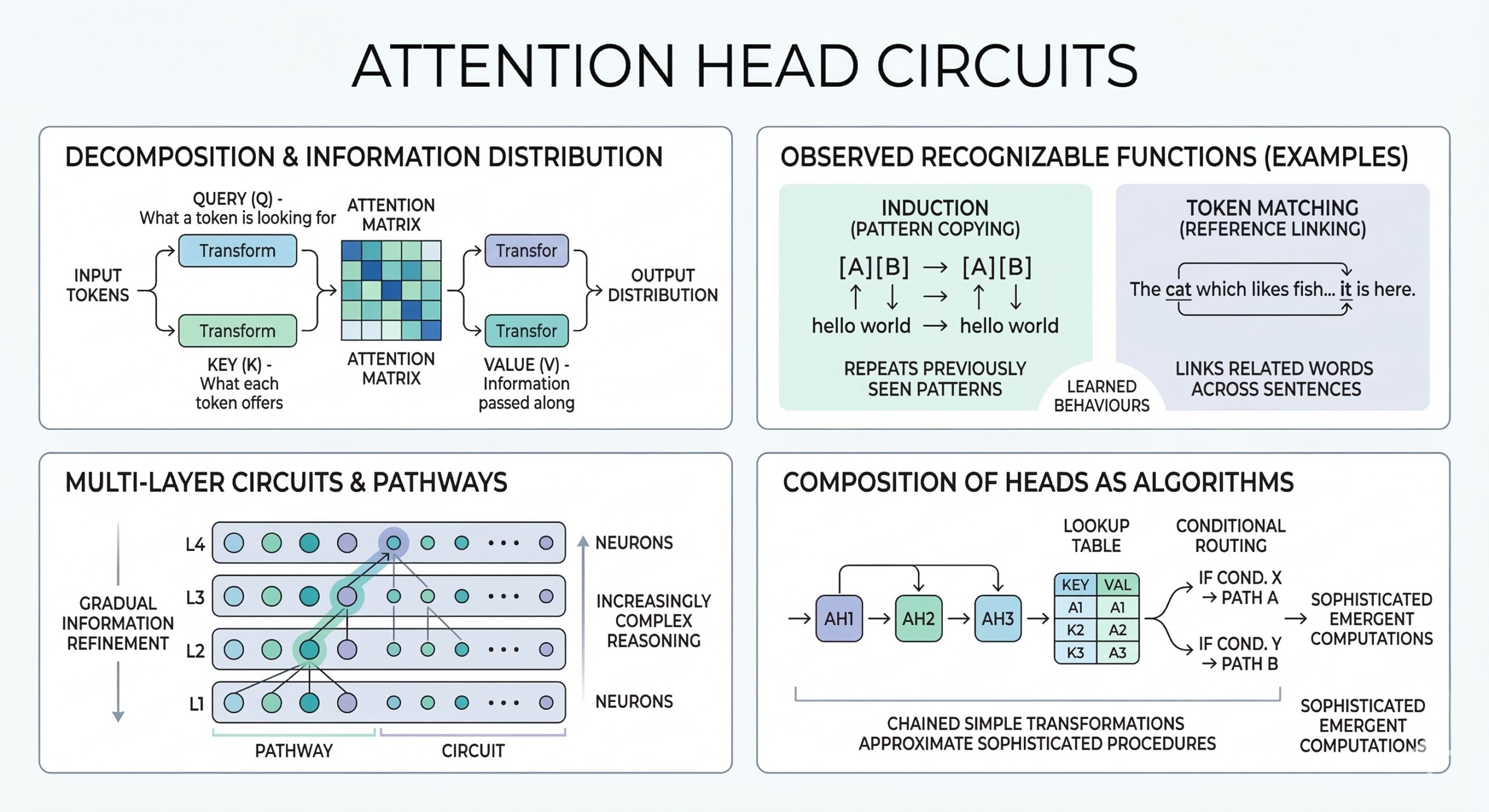
6. Technical deep dive: Attention head circuits
- Attention heads can be decomposed into query, key, and value transformations, which determine how each token in a sequence interacts with others. The query represents what a token is looking for, the key represents what each token offers, and the value carries the information that gets passed along. Together, these components define how attention distributes information across the sequence.
- Specific heads have been observed to implement recognizable functions such as induction (pattern copying) – where the model repeats previously seen patterns – or token matching, where it links related words or references across a sentence. These behaviours emerge naturally during training and can be consistently identified across models.
- Circuits built from attention heads and neurons often span multiple layers, forming multi-step computational pathways. Information is not processed in a single pass; instead, it is gradually refined, combined, and routed through different components, allowing the model to perform increasingly complex reasoning at deeper layers.
- The composition of multiple attention heads can effectively simulate algorithm-like operations, such as lookup tables or conditional routing. By chaining together simple transformations, the model can approximate structured procedures, demonstrating how seemingly simple components can give rise to sophisticated, emergent computations. Excellent individualised mentoring programmes available.
7. Linear representation & basis
- Transformer activations lie in high-dimensional vector spaces
- Features are often linearly encoded, meaning they can be extracted via projections
- Superposition arises when multiple features share the same basis vectors
- Sparse coding techniques attempt to disentangle these representations
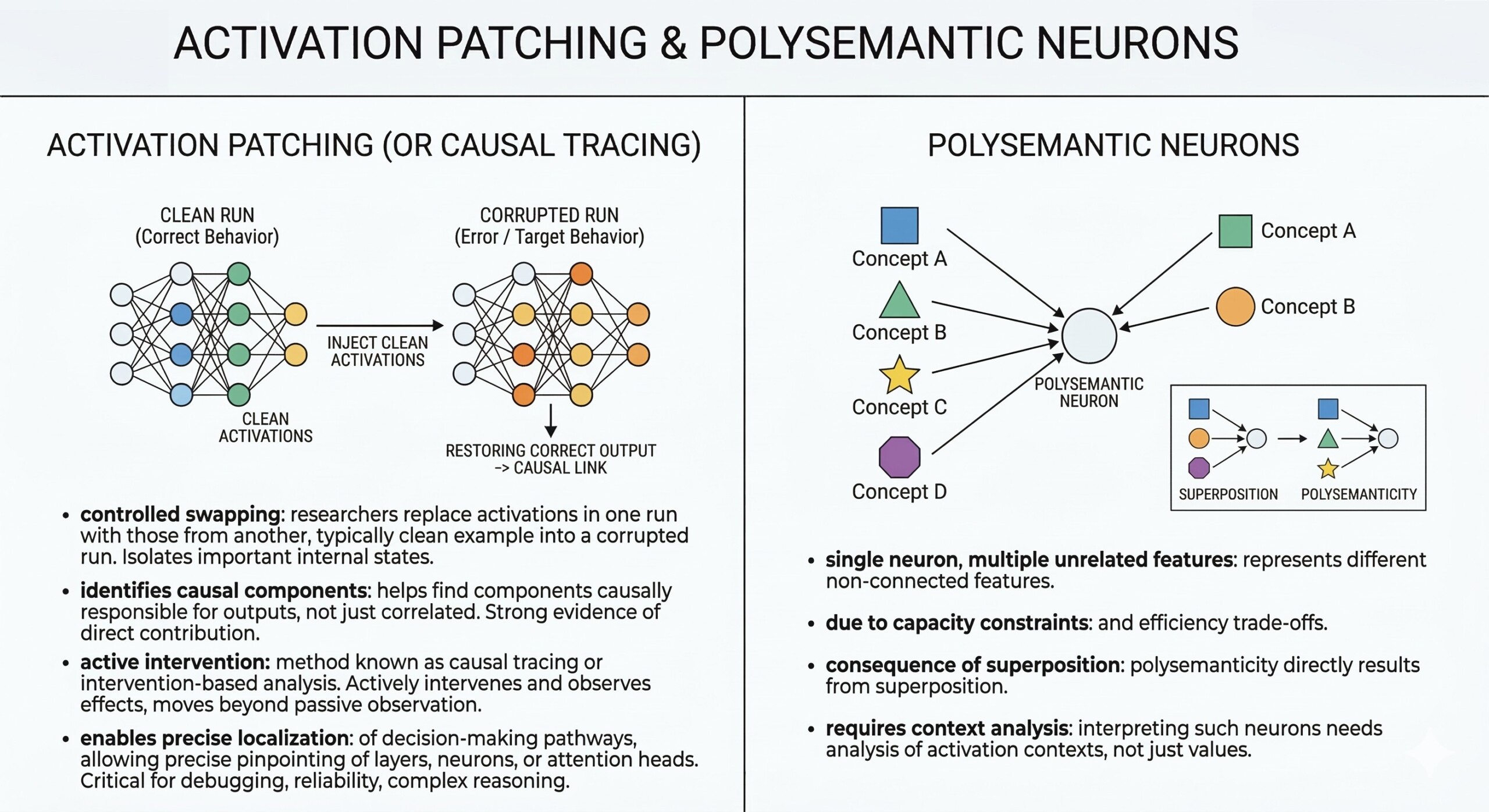
8. Activation patching
- Researchers replace activations in one run with those from another, typically by taking a “clean” example (where the model behaves correctly) and injecting parts of its internal activations into a “corrupted” run (where the model makes an error). This controlled swapping allows them to isolate which internal states matter for a given behaviour.
- This helps identify which components are causally responsible for outputs, rather than just correlated with them. If restoring a specific activation also restores the correct output, it provides strong evidence that this part of the model is directly contributing to the decision.
- This method is known as causal tracing or intervention-based analysis, because it actively intervenes in the model’s internal computation and observes the effects. It moves beyond passive observation and enables a more scientific, experiment-driven understanding of model behaviour.
- As a result, it enables precise localization of decision-making pathways, allowing researchers to pinpoint exactly which layers, neurons, or attention heads are involved in producing a specific output. This level of precision is critical for debugging models, improving reliability, and understanding how complex reasoning emerges. Subscribe to our free AI newsletter now.
9. Polysemantic neurons
- A single neuron can represent multiple unrelated features
- This occurs due to capacity constraints and efficiency trade-offs
- Polysemanticity is a direct consequence of superposition
- Interpreting such neurons requires analyzing activation contexts, not just values
10. Why this matters for AI safety and alignment
Understanding internal mechanisms helps in several important ways by making model behaviour more transparent and predictable:
- It allows researchers to detect hidden biases or failure modes, uncovering patterns the model may have learned unintentionally from data, such as skewed associations or systematic errors
- It helps prevent hallucinations and unsafe outputs by identifying where incorrect or fabricated information originates within the model’s internal processes
- It enables the development of more reliable and controllable AI systems, where specific behaviours can be guided, adjusted, or constrained based on a clear understanding of how the model works
- It supports efforts to align models with human intentions and ethical constraints, ensuring that outputs are not only accurate but also responsible and consistent with societal values
By moving from surface-level observations to deeper causal understanding, mechanistic interpretability provides tools to diagnose, correct, and improve model behavior. It allows developers to intervene more precisely rather than relying on trial-and-error fixes.
Mechanistic interpretability is therefore not just an academic pursuit—it is a practical necessity for building trustworthy, safe, and accountable AI systems that can be confidently deployed in real-world applications. Upgrade your AI-readiness with our masterclass.
Conclusion
Mechanistic interpretability represents a shift in how we engage with AI systems. Instead of accepting them as opaque tools, we begin to treat them as complex but understandable machines. By studying circuits, neurons, and feature representations, researchers are slowly uncovering the hidden logic behind transformer models.
However, this field is still in its early stages. The complexity of modern models means that full understanding remains a distant goal. Yet, even partial insights are proving valuable – offering ways to debug, improve, and align AI systems more effectively. As AI continues to shape society, mechanistic interpretability may become one of the most important tools we have to ensure these systems remain transparent, accountable, and aligned with human values.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



