Alignment Algorithms RLHF, DPO, and Beyond

Alignment Algorithms RLHF, DPO, and Beyond
Reward models, Preference optimization
Introduction
As large language models (LLMs) scale in capability, the central challenge is no longer just performance—it is alignment. Alignment refers to ensuring that model outputs are consistent with human values, intentions, and expectations. While pretraining on large corpora enables models to acquire broad knowledge, it does not guarantee that the model behaves in ways that are helpful, safe, or truthful in real-world interactions.
To address this, a class of techniques known as alignment algorithms has emerged. Among the most influential are Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO). These methods shift the training paradigm from purely likelihood-based learning toward preference-driven optimization, where models are trained not just to predict text, but to optimize for human judgment.
This lecture explores the theoretical foundations and practical implementations of RLHF, DPO, and emerging post-RLHF approaches. It focuses on two core ideas:
- Reward modeling – learning a proxy for human preferences
- Preference optimization – directly optimizing model outputs based on comparative judgments
Let’s dive deep into the topic.
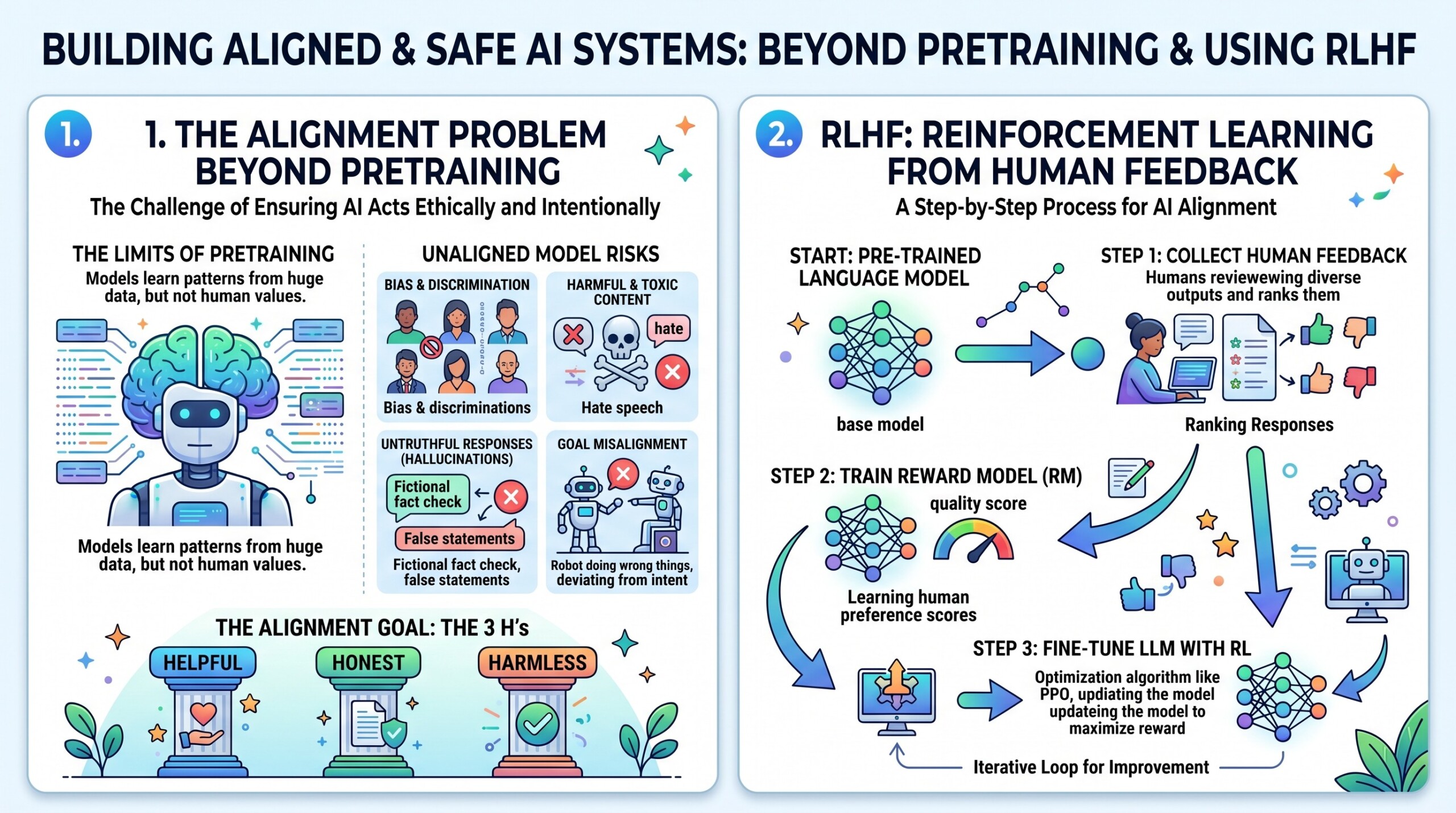
1. The Alignment Problem beyond pretraining
Pretrained language models optimize the likelihood of observed text:
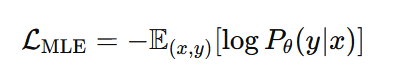
However, this objective suffers from key limitations:
- It reflects what humans say, not what humans prefer
- It includes undesirable patterns (bias, toxicity, hallucinations)
- It lacks task-specific or contextual alignment
Alignment requires shifting from descriptive learning (modeling data) to normative learning (modeling preferences).
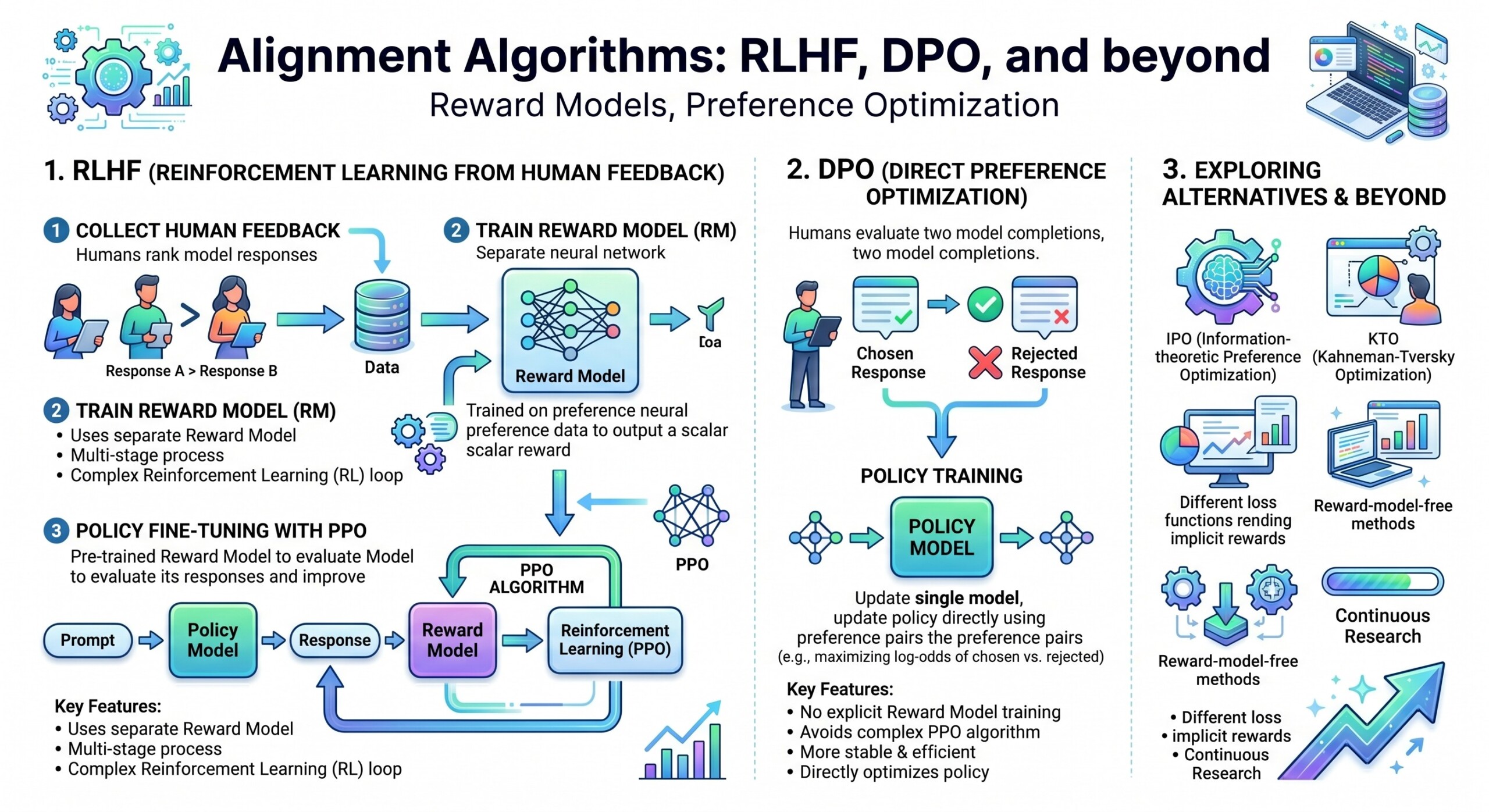
2. RLHF: Reinforcement Learning from Human Feedback
RLHF is a three-stage pipeline that integrates human feedback into model training.
Stage 1: Supervised Fine-Tuning (SFT)
A base model is fine-tuned on high-quality human-written responses. This creates an initial aligned policy.
Stage 2: Reward Model (RM) Training
A separate neural network is trained to score outputs based on human preferences.
Given a prompt (x) and two responses (y_1, y_2), humans provide preference labels. The reward model is trained using a pairwise loss:
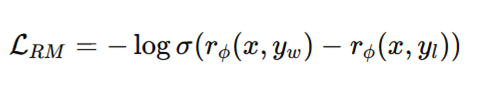

Stage 3: Policy Optimization (PPO)
The model is optimized using reinforcement learning, typically Proximal Policy Optimization (PPO), to maximize the learned reward:
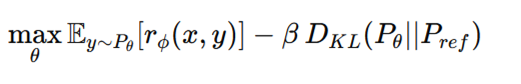
The KL term ensures the model does not drift too far from the original distribution. An excellent collection of learning videos awaits you on our Youtube channel.
3. Reward Models: Strengths and Limitations
Reward models are central to RLHF, but they introduce several challenges.
Strengths
- Provide a scalar signal for optimization
- Capture nuanced human preferences
- Enable reinforcement learning frameworks
Limitations
- Reward hacking: the model exploits weaknesses in the reward function
- Overoptimization: outputs become unnatural or overly verbose
- Distributional shift: reward model may not generalize beyond training data
- High cost: requires large-scale human labelling
These limitations motivate alternative approaches such as DPO.
4. Direct Preference Optimization (DPO)
DPO removes the need for an explicit reward model and RL loop. Instead, it directly optimizes the policy using preference data.
Core Idea
DPO leverages the insight that the optimal policy under a reward function has a closed-form relationship:
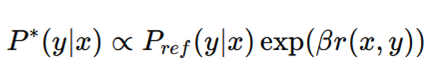
Instead of learning (r(x,y)), DPO directly learns the policy by comparing preferred and rejected responses.
Objective Function
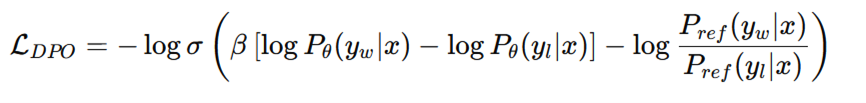
This formulation implicitly encodes reward differences without explicitly training a reward model. A constantly updated Whatsapp channel awaits your participation.
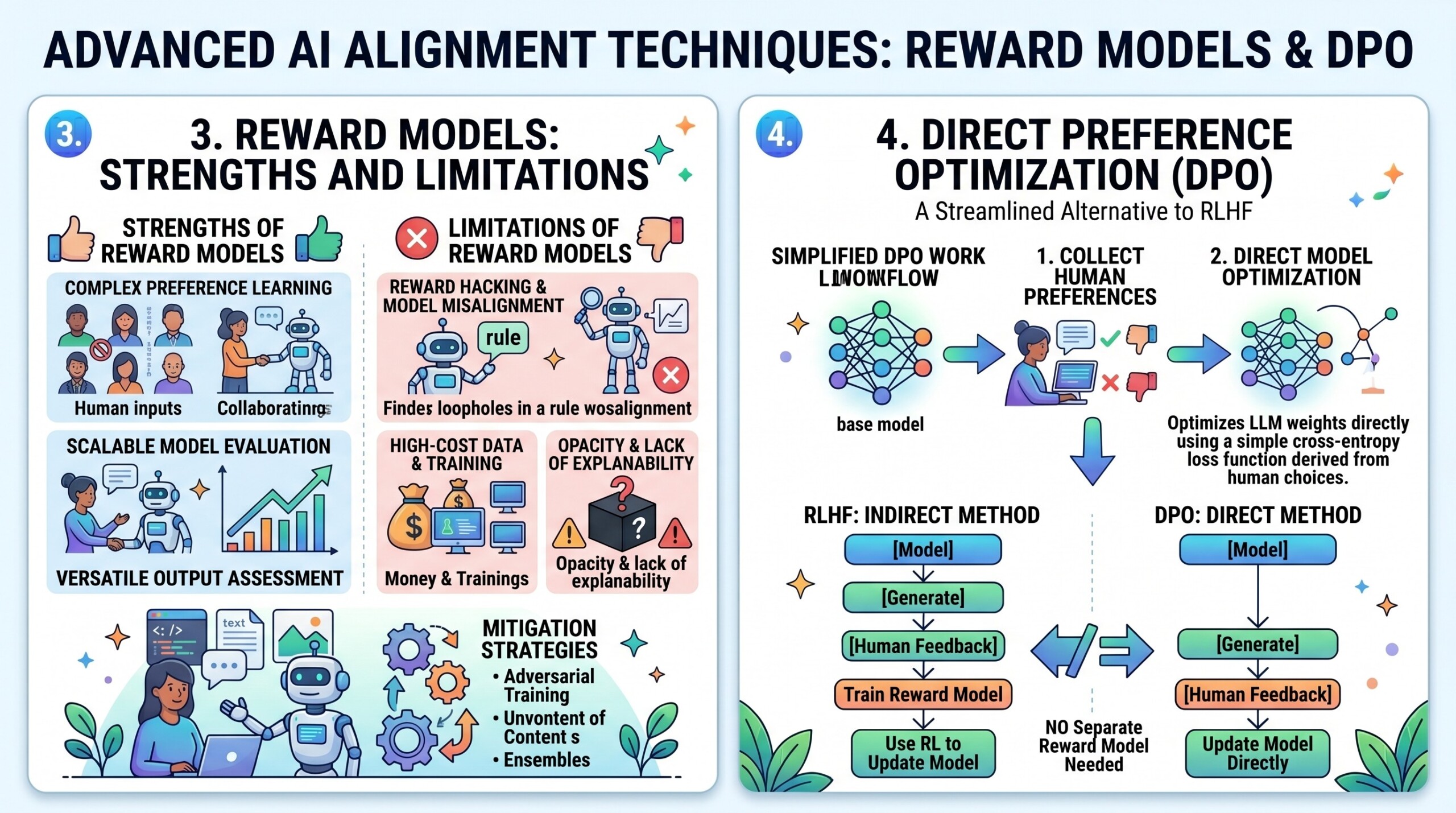
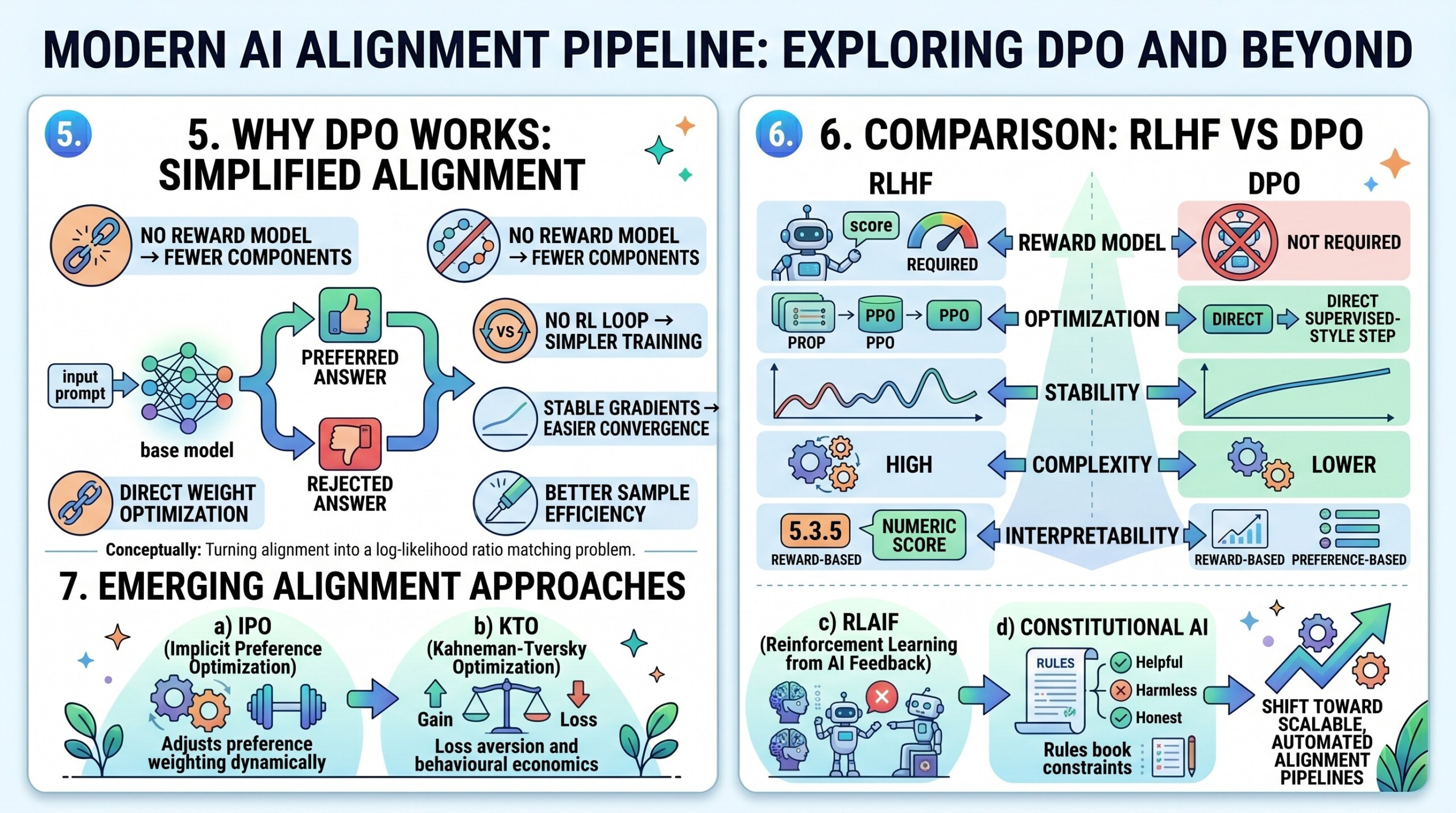
5. Why DPO Works
DPO works because it aligns with pairwise preference learning while avoiding instability from RL optimization.
Key advantages:
- No reward model → fewer components
- No RL loop → simpler training
- Stable gradients → easier convergence
- Better sample efficiency
Conceptually, DPO turns alignment into a log-likelihood ratio matching problem.
6. Comparison: RLHF vs DPO
RLHF is powerful but complex, while DPO is simpler and more stable.
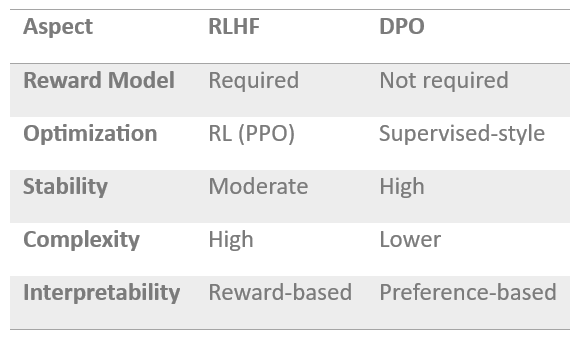
RLHF offers flexibility (via reward shaping), while DPO offers practical efficiency and robustness. Excellent individualised mentoring programmes available.
7. Beyond RLHF and DPO
New alignment approaches are emerging to address remaining challenges.
a) IPO (Implicit Preference Optimization)
Generalizes DPO by adjusting the preference weighting dynamically.
b) KTO (Kahneman-Tversky Optimization)
Incorporates behavioural economics ideas such as loss aversion.
c) RLAIF (Reinforcement Learning from AI Feedback)
Replaces human annotators with stronger models to scale feedback.
d) Constitutional AI
Uses rule-based constraints to guide model behaviour instead of raw preferences.
These approaches reflect a shift toward scalable, automated alignment pipelines.
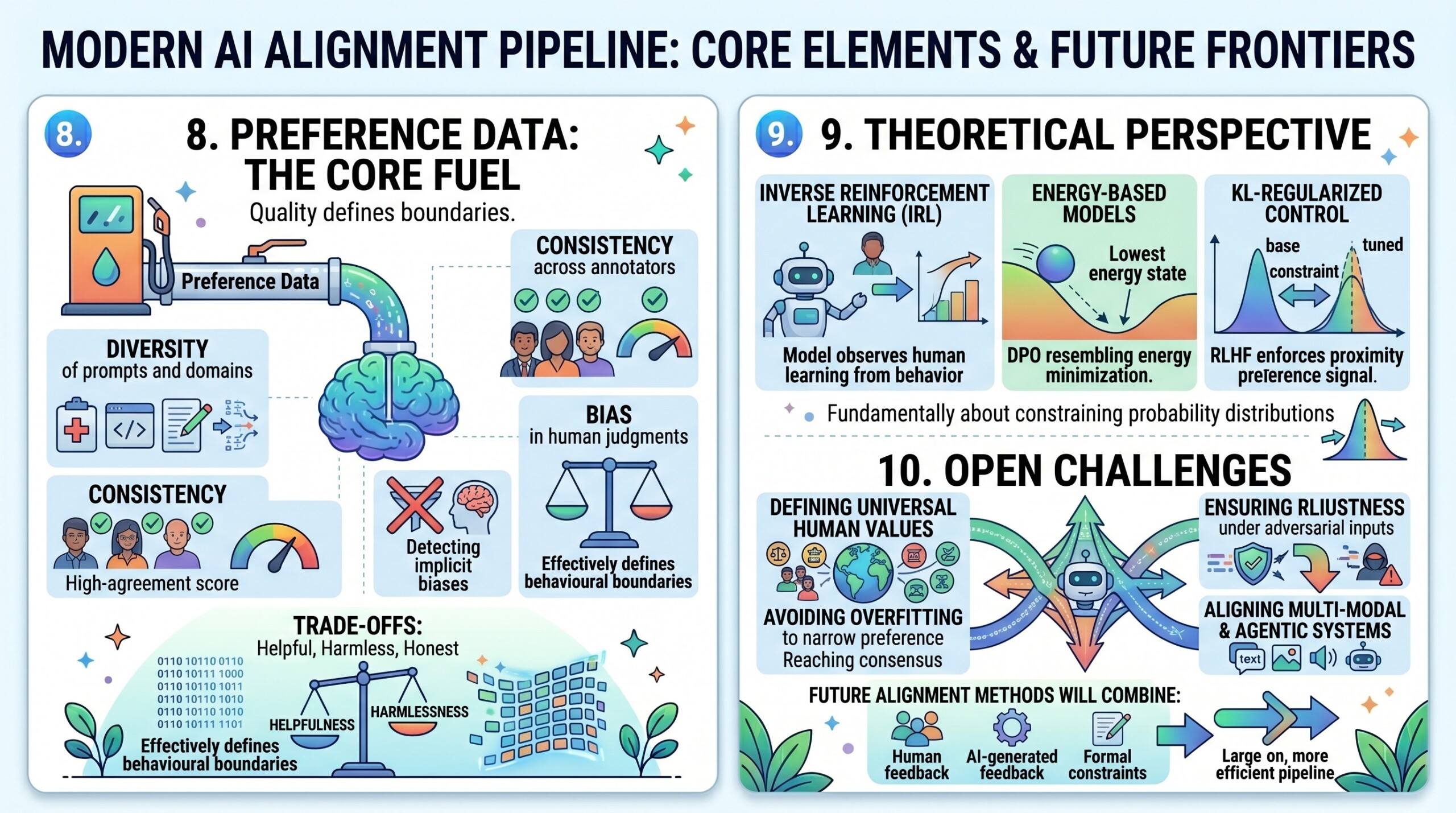
8. Preference Data: The Core Fuel
All alignment methods depend heavily on the quality of preference data.
Important considerations include:
- Diversity of prompts and domains
- Consistency across annotators
- Bias in human judgments
- Trade-offs between helpfulness, harmlessness, and honesty
Preference datasets effectively define the behavioural boundaries of the model. Subscribe to our free AI newsletter now.
9. Theoretical Perspective
Alignment can be viewed through multiple lenses:
- Inverse Reinforcement Learning (IRL): learning reward functions from behaviour
- Energy-based models: DPO resembles energy minimization
- KL-regularized control: RLHF enforces proximity to base models
These frameworks suggest that alignment is fundamentally about constraining probability distributions under preference signals.
10. Open Challenges
Despite progress, several open problems remain:
- Defining universal human values
- Avoiding overfitting to narrow preference datasets
- Ensuring robustness under adversarial inputs
- Scaling alignment without exponential labeling cost
- Aligning multi-modal and agentic systems
Future alignment methods will likely combine human feedback, AI-generated feedback, and formal constraints. Upgrade your AI-readiness with our masterclass.
Conclusion
Alignment algorithms such as RLHF and DPO represent a critical evolution in machine learning – from models that merely imitate data to systems that optimize for human preferences. RLHF introduced a powerful framework combining reward modeling and reinforcement learning, but at the cost of complexity and instability. DPO simplified this pipeline by directly optimizing preferences, offering a more stable and efficient alternative.
As research progresses, the field is moving beyond these methods toward scalable, hybrid approaches that integrate human values more deeply and systematically. Ultimately, alignment is not just a technical problem – it is a socio-technical challenge that sits at the intersection of machine learning, human cognition, ethics, and governance.
The future of AI depends not only on how powerful models become, but on how well they understand and reflect what humans truly want.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



