Training Stability & Gradient Dynamics

Training Stability & Gradient Dynamics
Gradient explosion/vanishing, Initialization, normalization
Introduction
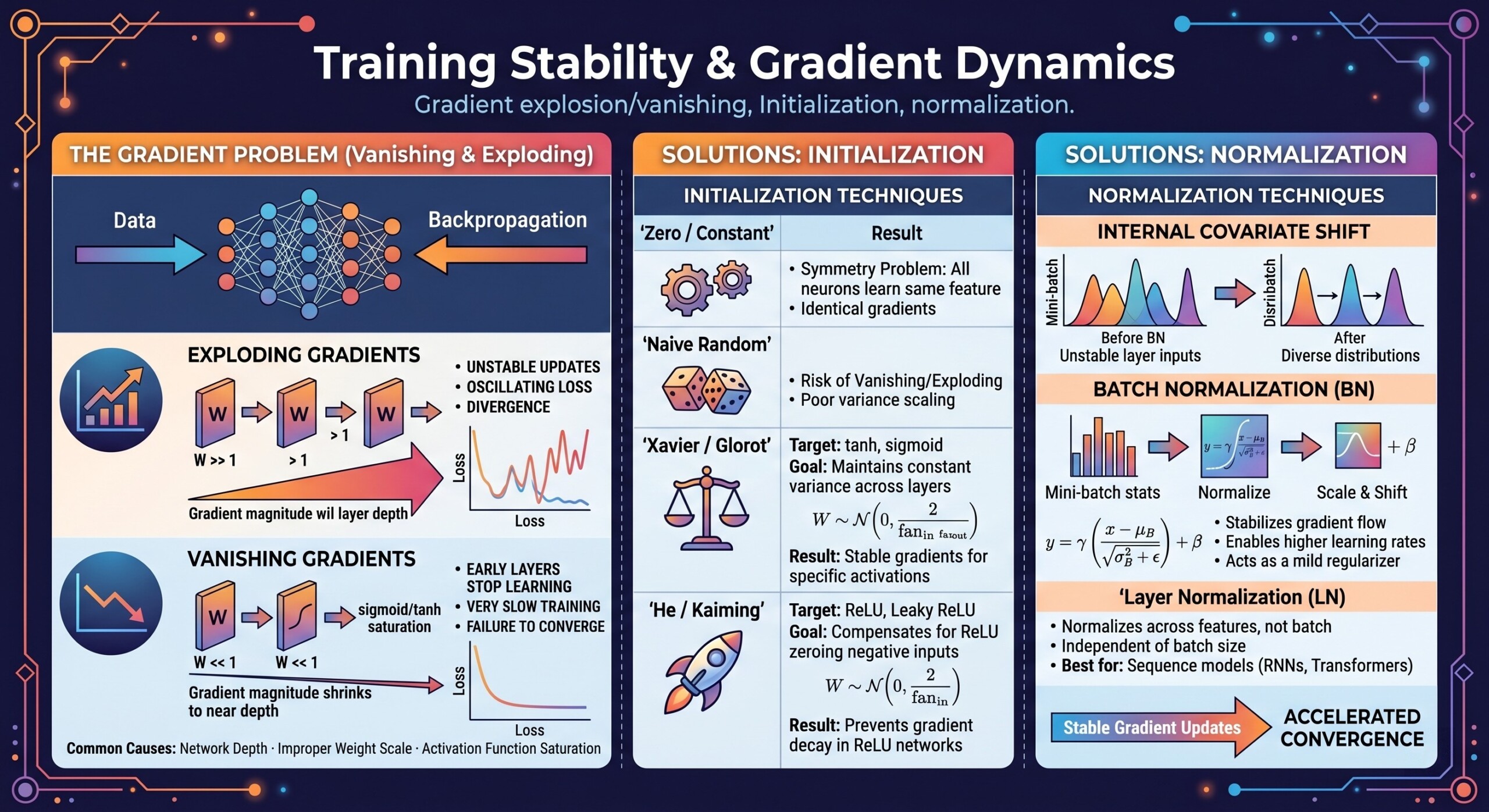
Training deep neural networks is not just about choosing the right architecture or dataset, but fundamentally about ensuring that learning remains stable across layers and over time. At the heart of this stability lies the behavior of gradients, the signals that guide weight updates during backpropagation. If these gradients behave erratically – becoming too small or too large – the entire training process can stall or diverge. This makes understanding gradient dynamics a critical requirement for anyone building or deploying deep learning systems.
As networks grow deeper and more complex, issues like vanishing gradients, exploding gradients, poor weight initialization, and lack of proper normalization become more pronounced. These problems are not just theoretical but directly impact convergence speed, model accuracy, and reproducibility. In this lecture, we explore the underlying mechanics of these challenges and the practical techniques used to address them.
Let’s dive deep into the topic.
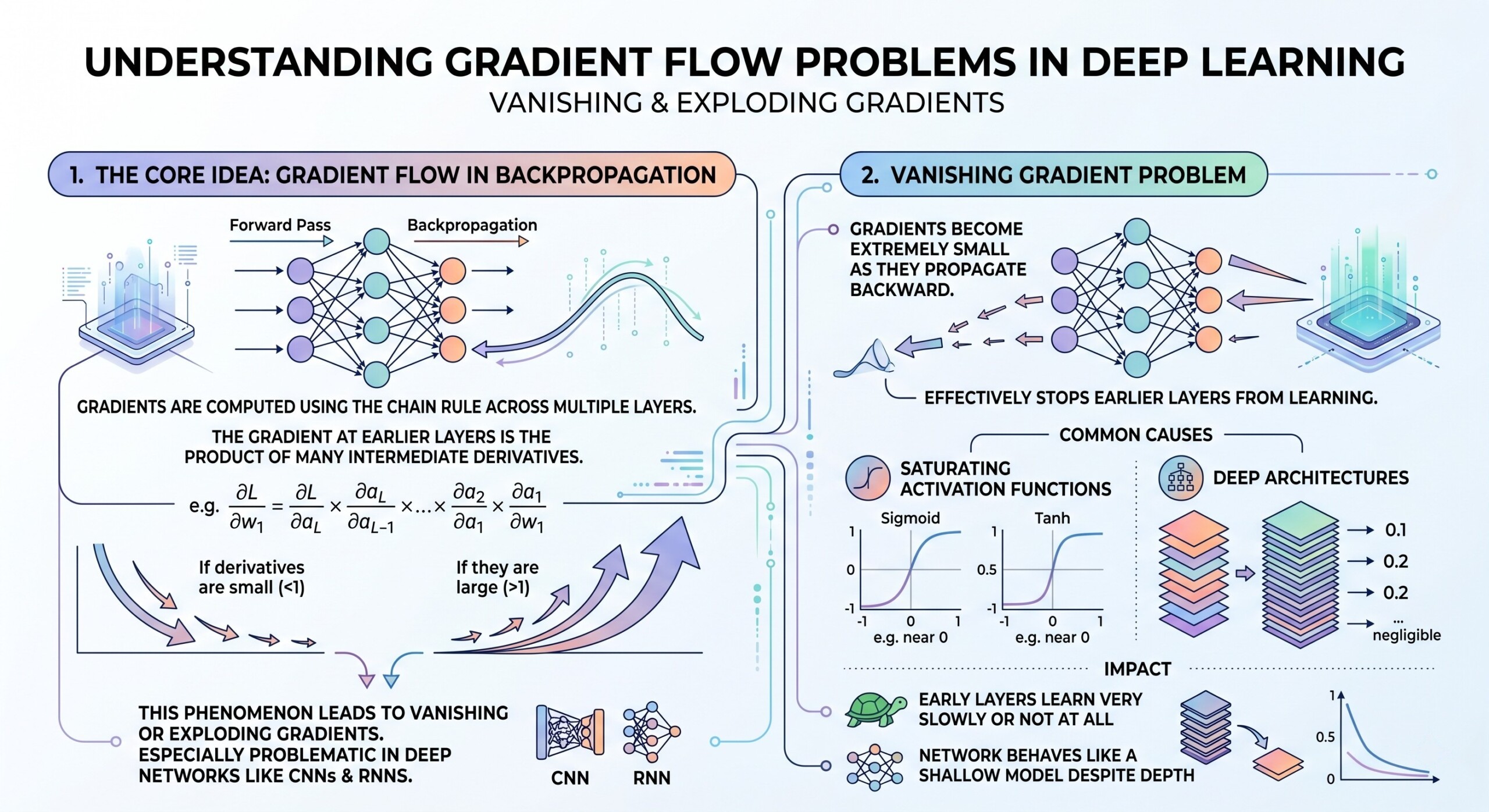
1. The Core Idea: Gradient Flow in Backpropagation
In deep learning, gradients are computed using the chain rule across multiple layers. This means that the gradient at earlier layers is the product of many intermediate derivatives. If these derivatives are small (<1), gradients shrink exponentially. If they are large (>1), gradients grow exponentially.
This phenomenon directly leads to vanishing or exploding gradients and is especially problematic in deep networks like CNNs and RNNs.
2. Vanishing Gradient problem
Vanishing gradients occur when gradients become extremely small as they propagate backward. This effectively stops earlier layers from learning.
Common causes:
- Activation functions like sigmoid or tanh squash values between small ranges.
- Deep architectures with many layers amplify the shrinking effect.
Impact:
- Early layers learn very slowly or not at all.
- Network behaves like a shallow model despite depth. An excellent collection of learning videos awaits you on our Youtube channel.
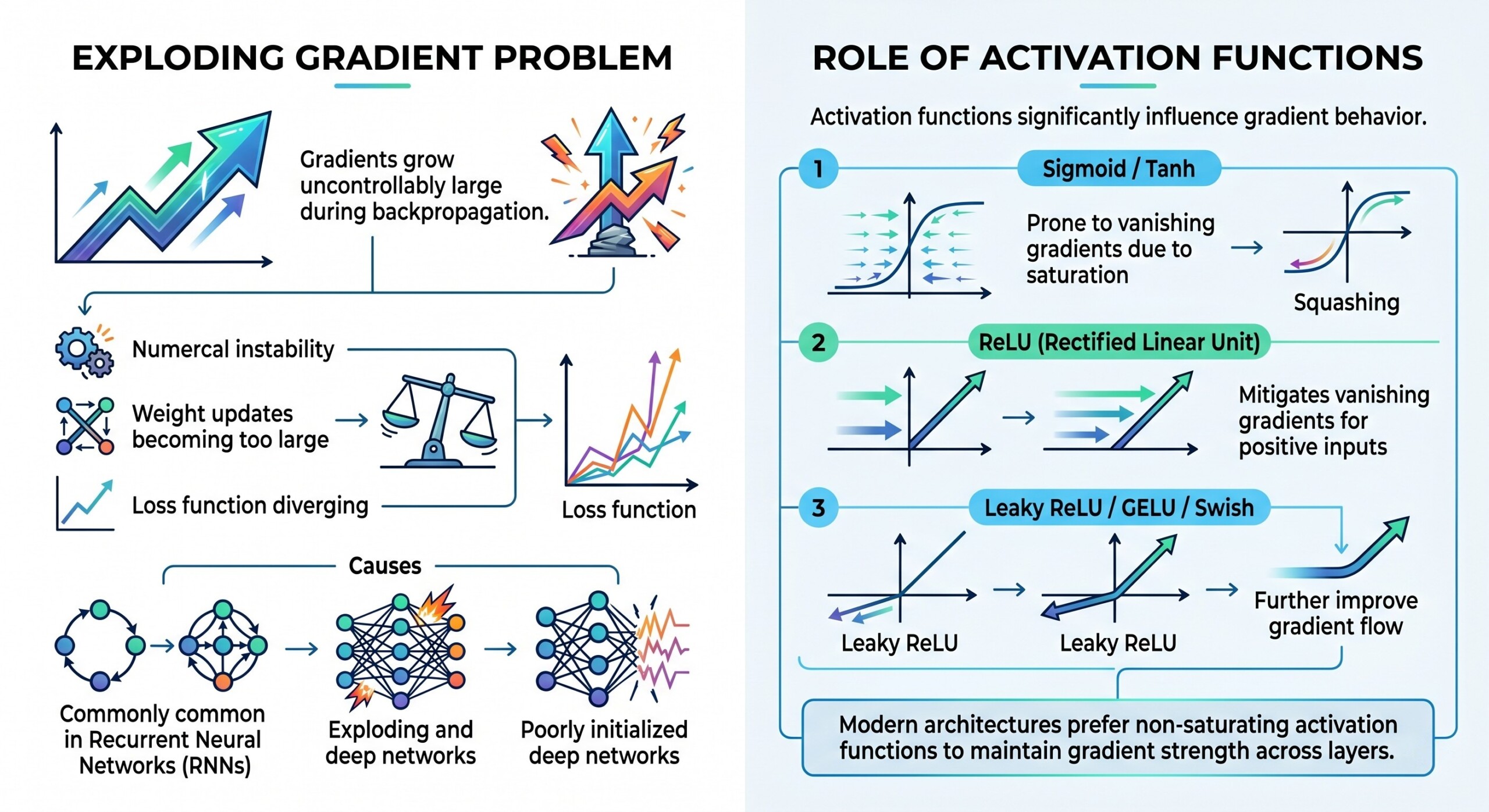
3. Exploding Gradient problem
Exploding gradients are the opposite issue – gradients grow uncontrollably large during backpropagation.
This leads to:
- Numerical instability
- Weight updates becoming too large
- Loss function diverging
This is particularly common in:
- Recurrent Neural Networks (RNNs)
- Poorly initialized deep networks
4. Role of Activation functions
Activation functions significantly influence gradient behavior.
- Sigmoid / Tanh → prone to vanishing gradients due to saturation
- ReLU (Rectified Linear Unit) → mitigates vanishing gradients for positive inputs
- Leaky ReLU / GELU / Swish → further improve gradient flow
Modern architectures prefer non-saturating activation functions to maintain gradient strength across layers. A constantly updated Whatsapp channel awaits your participation.
5. Weight Initialization: Why It matters
Improper initialization can either shrink or amplify gradients from the very beginning.
Key idea:
Weights should be initialized so that variance of activations remains stable across layers.
Common strategies:
- Xavier Initialization → for tanh/sigmoid
- He Initialization → for ReLU-based networks
These methods ensure that:
- Forward activations don’t explode/vanish
- Backward gradients remain stable
6. Xavier Initialization (Glorot Initialization)
Xavier initialization sets weights based on the number of input and output neurons:
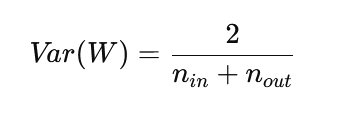
This balances signal flow in both forward and backward passes, making it suitable for symmetric activation functions like tanh. Excellent individualised mentoring programmes available.
7. He Initialization for Deep Networks
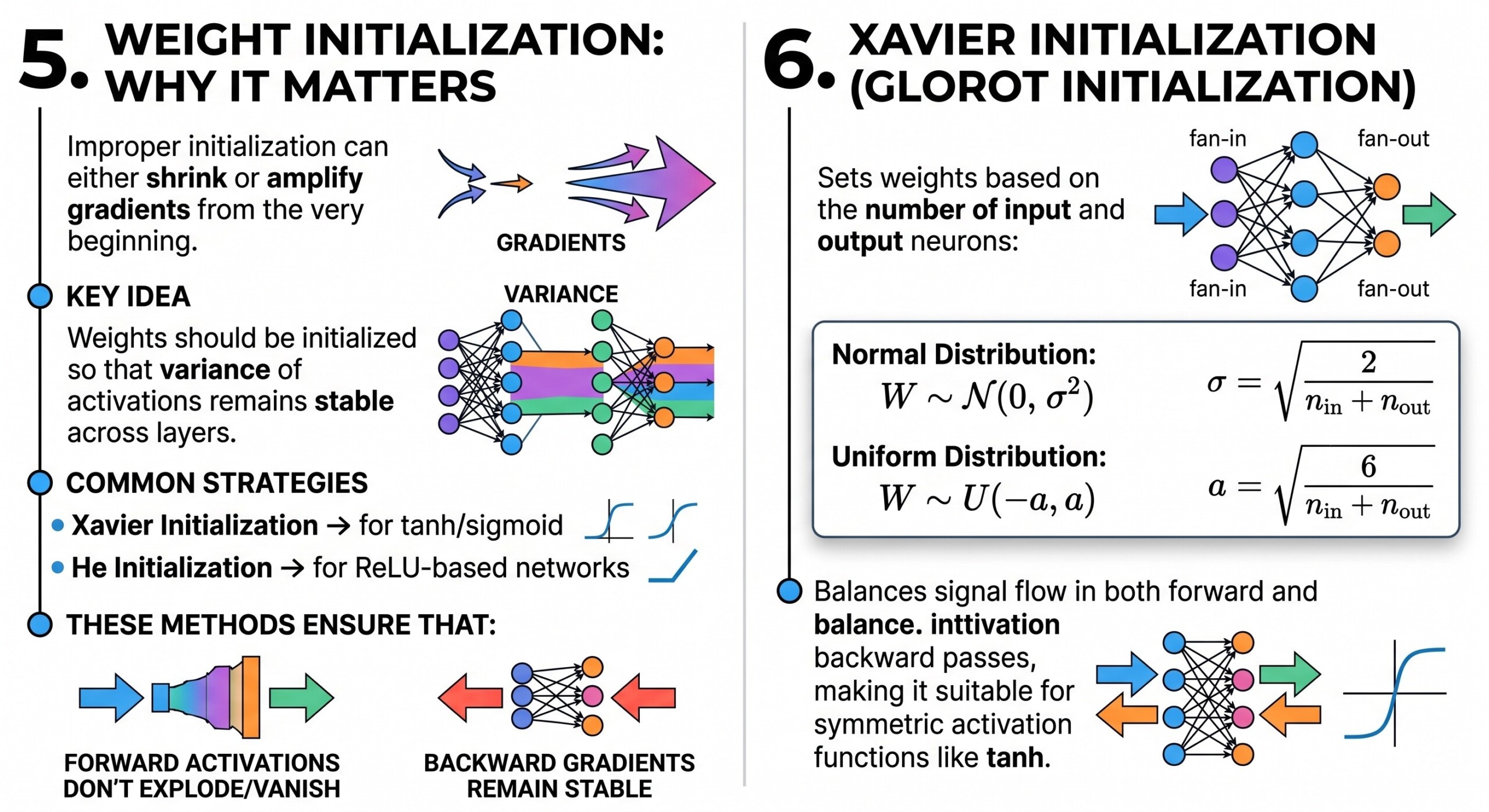
For ReLU-based networks, He initialization is more effective:
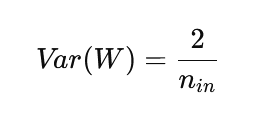
Since ReLU zeroes out half the activations, this initialization compensates by increasing variance slightly, ensuring gradients don’t vanish.
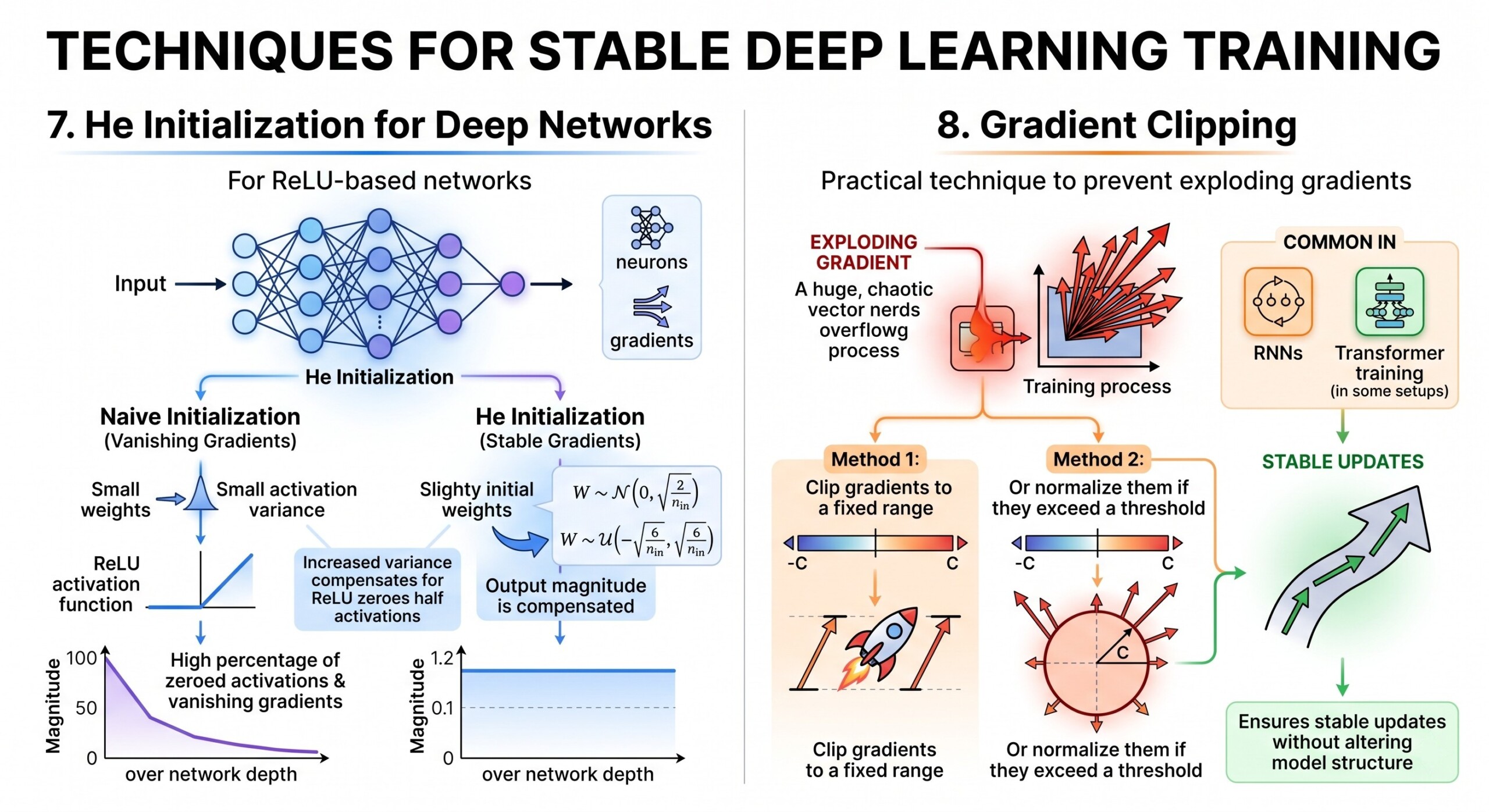
8. Gradient Clipping
A practical technique to prevent exploding gradients.
Instead of allowing gradients to grow indefinitely:
- Clip gradients to a fixed range
- Or normalize them if they exceed a threshold
Common in:
- RNNs
- Transformer training (in some setups)
This ensures stable updates without altering model structure. Subscribe to our free AI newsletter now.
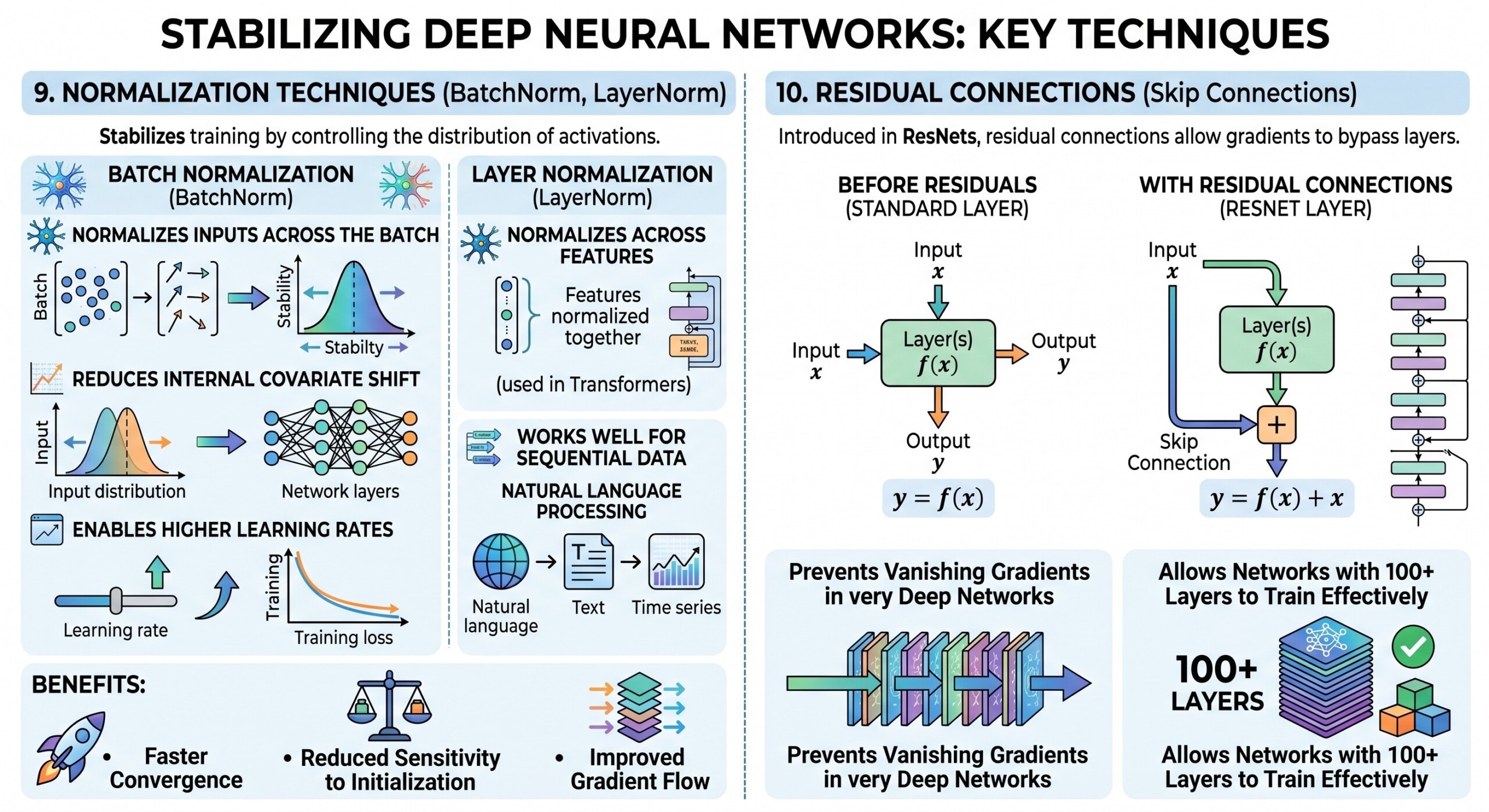
9. Normalization Techniques (BatchNorm, LayerNorm)
Normalization stabilizes training by controlling the distribution of activations.
Batch Normalization:
- Normalizes inputs across the batch
- Reduces internal covariate shift
- Enables higher learning rates
Layer Normalization:
- Normalizes across features (used in Transformers)
- Works well for sequential data
Benefits:
- Faster convergence
- Reduced sensitivity to initialization
- Improved gradient flow
10. Residual Connections (Skip Connections)
Introduced in ResNets, residual connections allow gradients to bypass layers.
Instead of learning:
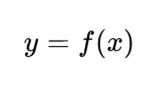
The Model learns:
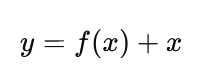
This simple idea:
- Prevents vanishing gradients in very deep networks
- Allows networks with 100+ layers to train effectively
Upgrade your AI-readiness with our masterclass.
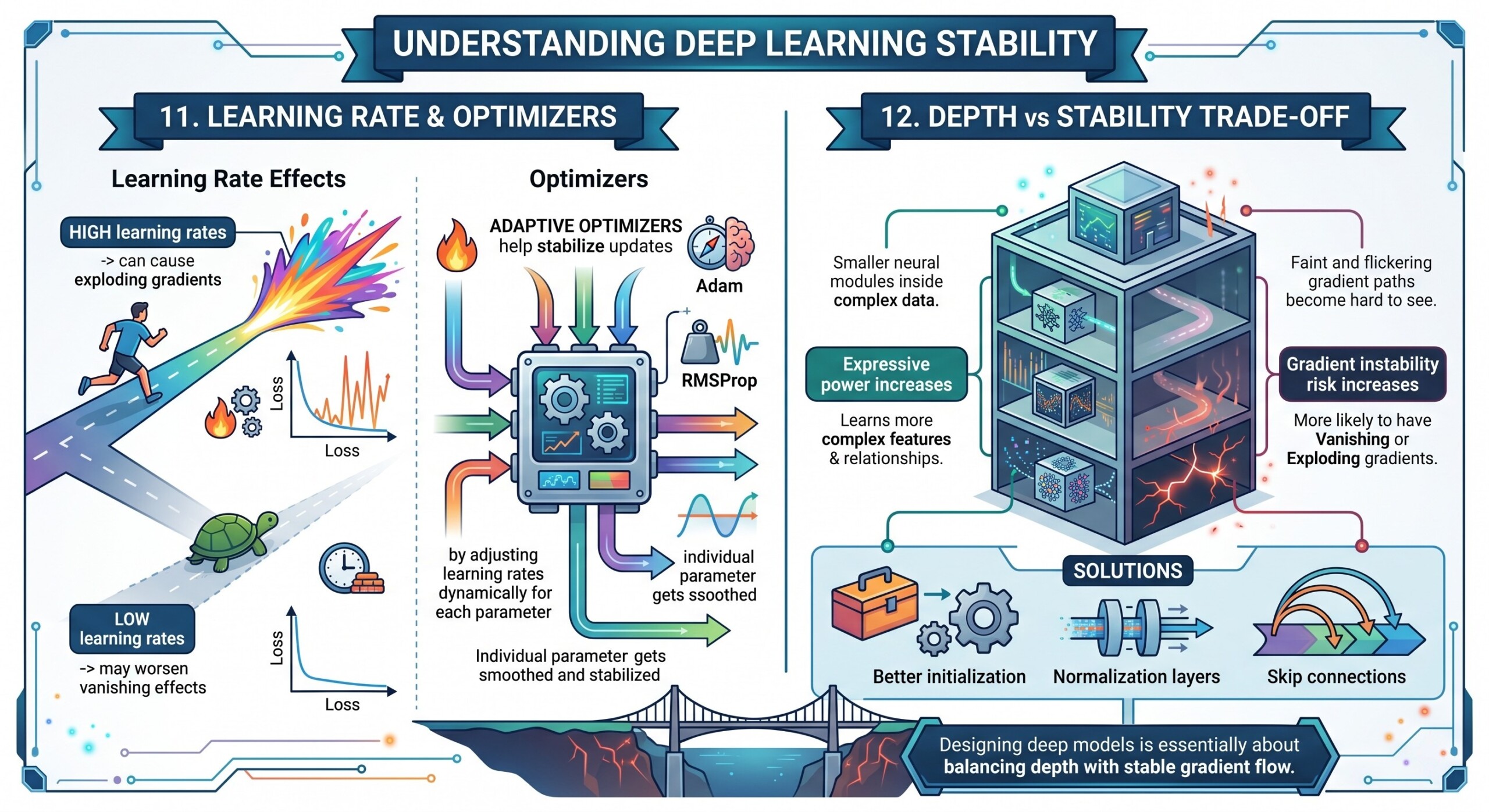
11. Learning Rate and Optimizers
Gradient stability is also influenced by optimization.
- High learning rates → can cause exploding gradients
- Low learning rates → may worsen vanishing effects
Adaptive optimizers like:
- Adam
- RMSProp
help stabilize updates by adjusting learning rates dynamically for each parameter.
12. Depth vs Stability Trade-off
As networks become deeper:
- Expressive power increases
- Gradient instability risk increases
Modern architectures solve this using:
- Better initialization
- Normalization layers
- Skip connections
Designing deep models is essentially about balancing depth with stable gradient flow.
Conclusion
Training stability is one of the most critical and often underestimated aspects of deep learning. Gradient explosion and vanishing are not just mathematical curiosities; they are real bottlenecks that can prevent models from learning altogether. Techniques like proper initialization, normalization, activation design, and gradient control form the backbone of modern deep learning systems.
Understanding gradient dynamics gives practitioners a deeper intuition into why certain architectures work while others fail. As models scale in size and complexity – from CNNs to Transformers – the principles discussed here become even more essential. Ultimately, stable gradients are what make deep learning actually work in practice, turning theoretical architectures into reliable, high-performing systems.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



