Distributed Training & Large-Scale Systems

Distributed Training & Large-Scale Systems
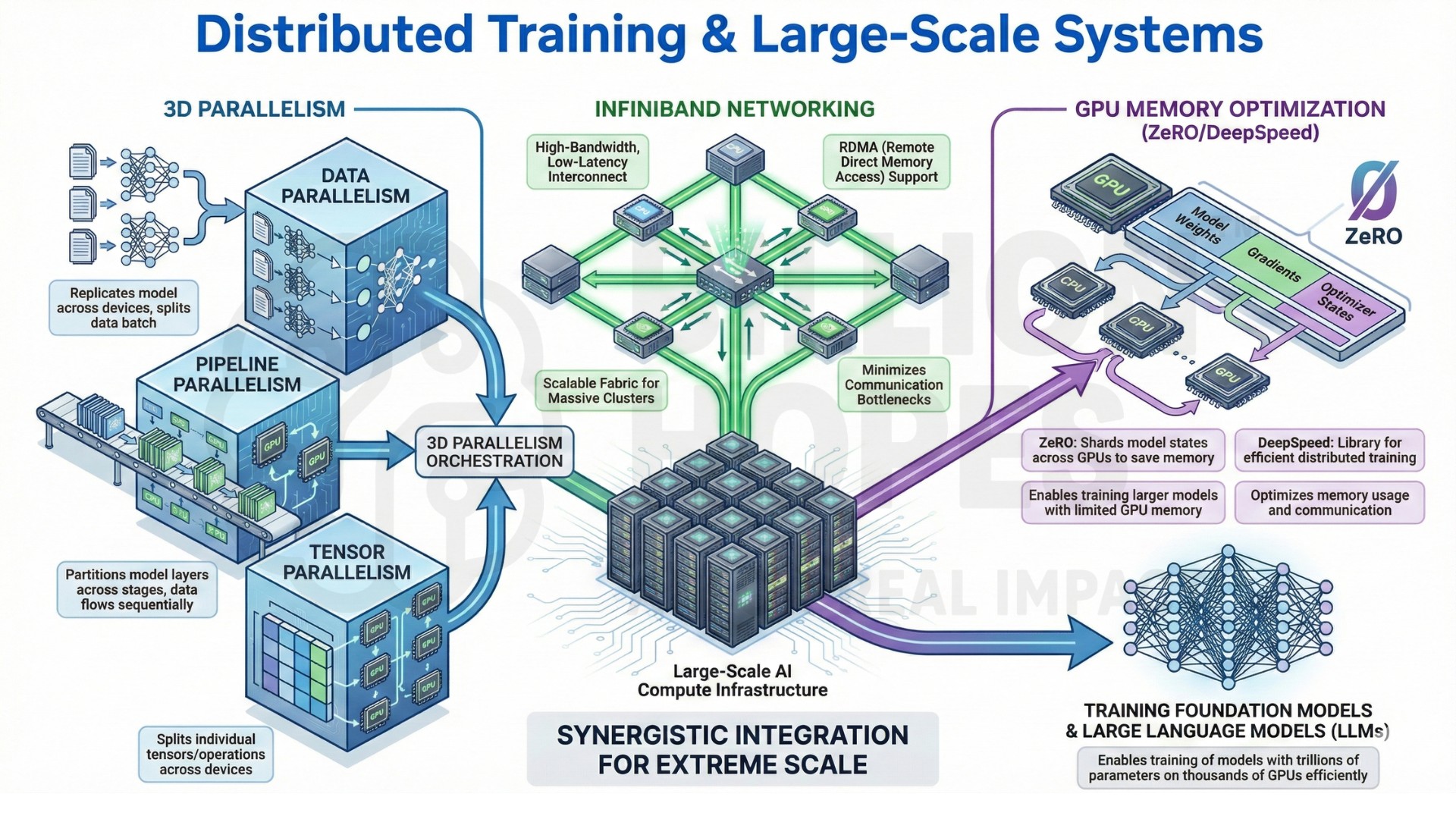
The engineering of 3D parallelism (Data, Pipeline, and Tensor),
InfiniBand networking, and GPU memory optimization (ZeRODeepSpeed)
Modern frontier AI models are no longer constrained by algorithms alone, but by the physics and engineering of distributed systems. Training state-of-the-art LLMs, multimodal models, and foundation models now depends on scaling computation across thousands of GPUs connected by high-speed networks. The bottleneck has shifted from model architecture to system-level efficiency: communication overhead, memory limits, and fault tolerance now shape what models can realistically be trained.
Distributed training reframes deep learning as a large-scale systems engineering problem. Techniques like 3D parallelism (data, pipeline, and tensor parallelism), InfiniBand-class networking, and memory optimization frameworks such as DeepSpeed ZeRO enable models that exceed single-node limits. This shift turns AI training into a co-design problem between algorithms, hardware, networking, and distributed software systems.
This evolution introduces AI systems whose capabilities are bounded as much by interconnect bandwidth, memory sharding, and synchronization efficiency as by model size. Scaling intelligence is now a distributed computing problem, not just a modeling one.
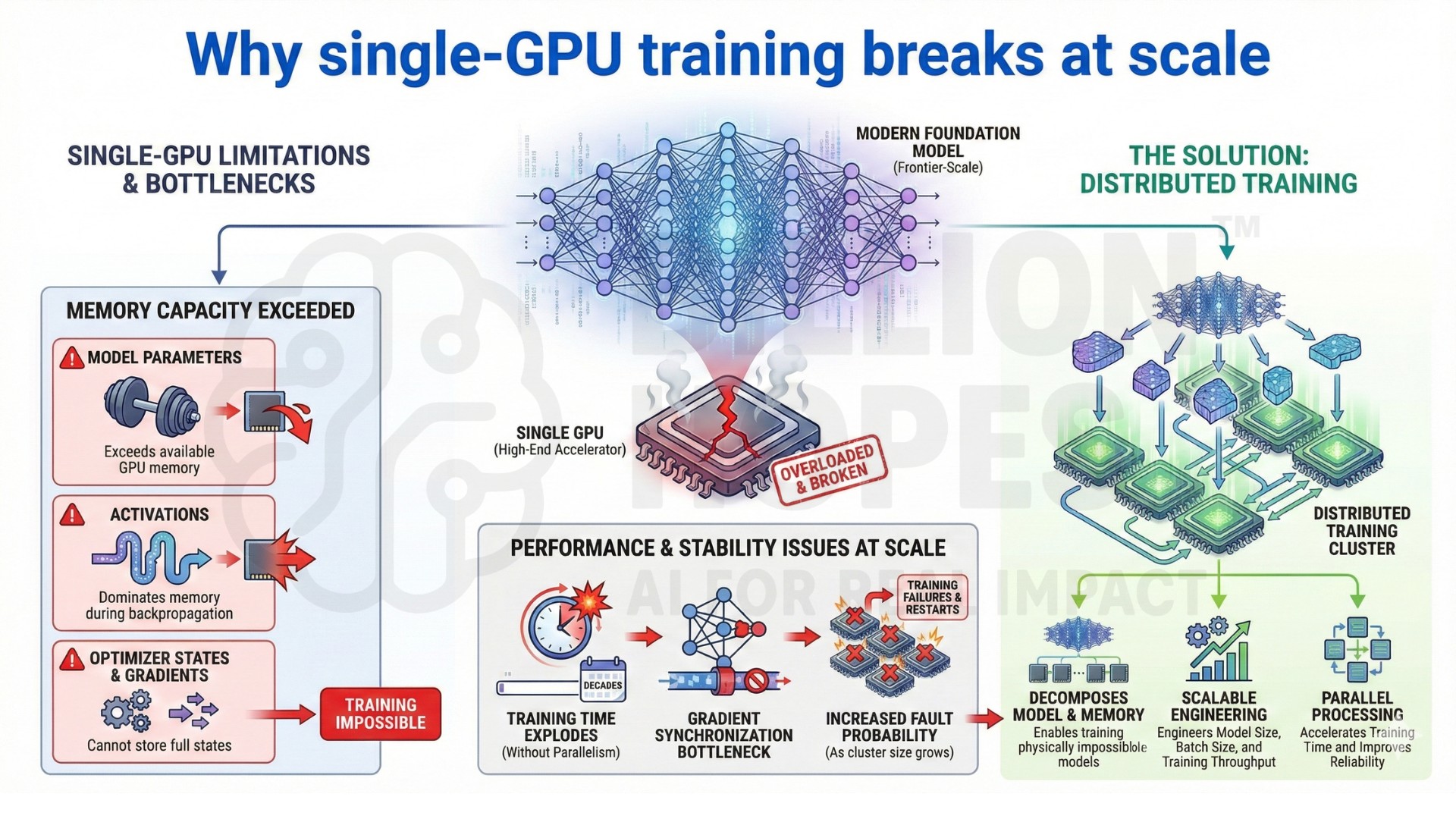
1. Why single-GPU training breaks at scale
Modern foundation models exceed the memory and compute limits of any single GPU. Even high-end accelerators cannot store full model parameters, activations, optimizer states, and gradients for frontier-scale training.
In large-scale settings:
• Model parameters exceed GPU memory capacity
• Activation memory dominates during backpropagation
• Gradient synchronization becomes a bottleneck
• Training time explodes without parallelism
• Faults become more likely as cluster size grows
Distributed training decomposes model computation and memory across devices, enabling models that are physically impossible to train on a single node. This changes how model size, batch size, and training throughput are engineered.
2. From single-node training to distributed systems engineering
Early deep learning treated GPUs as isolated accelerators. Modern training treats clusters as tightly-coupled distributed systems.
Distributed training introduces:
• Multi-node GPU clusters
• High-speed interconnects (InfiniBand-class fabrics)
• Collective communication primitives (all-reduce, all-gather)
• Synchronization and consistency protocols
• Fault tolerance and checkpointing strategies
This transition marks a shift from optimizing kernels on one GPU to orchestrating computation across thousands of devices with minimal communication overhead and predictable failure recovery. An excellent collection of learning videos awaits you on our Youtube channel.
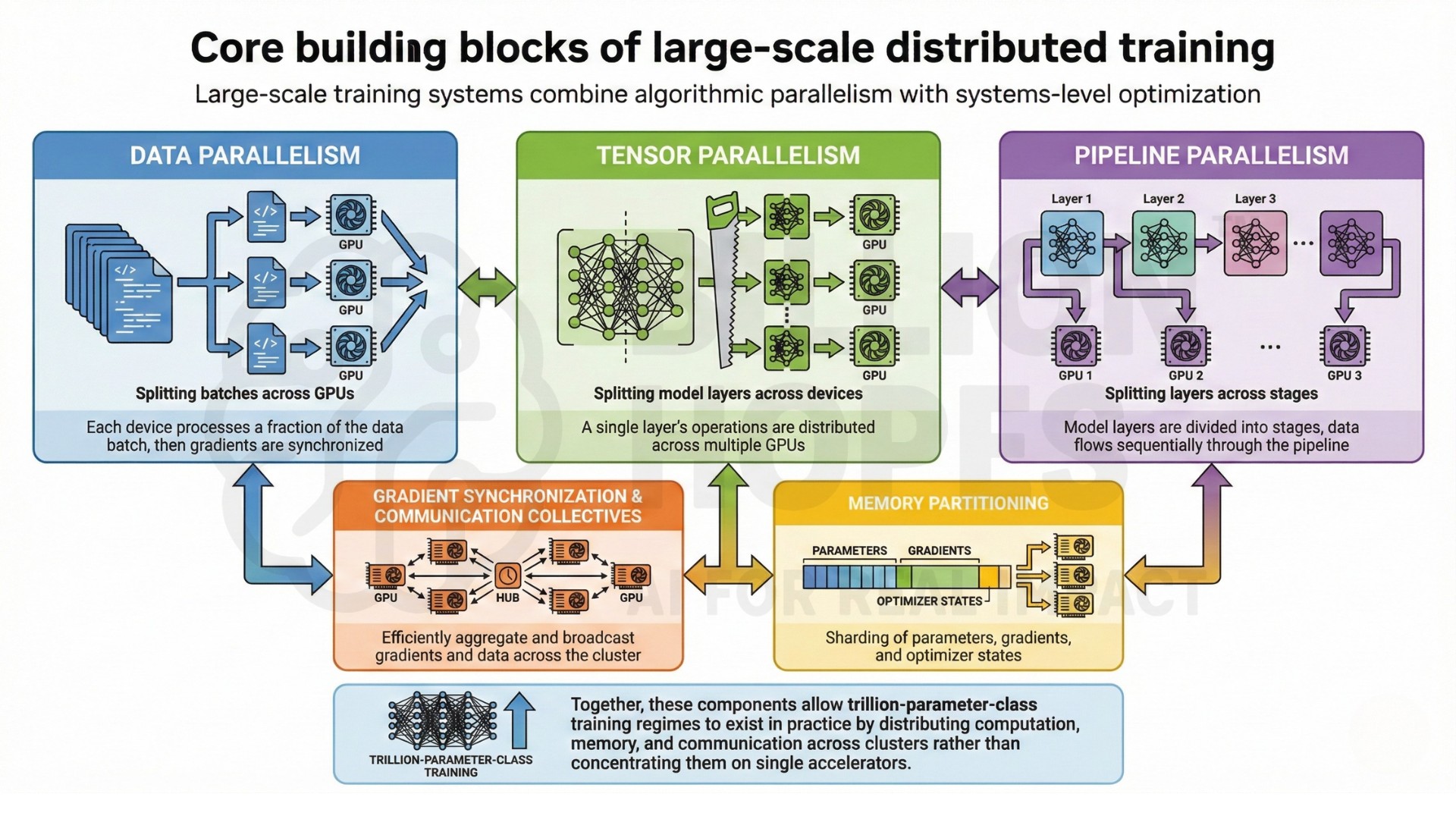
3. Core building blocks of large-scale distributed training
Large-scale training systems combine algorithmic parallelism with systems-level optimization:
- Data parallelism – splitting batches across GPUs
• Tensor parallelism – splitting model layers across devices
• Pipeline parallelism – splitting layers across stages
• Gradient synchronization and communication collectives
• Memory partitioning of parameters, gradients, and optimizer states
Together, these components allow trillion-parameter-class training regimes to exist in practice by distributing computation, memory, and communication across clusters rather than concentrating them on single accelerators.
4. What large-scale distributed systems are used for in practice
Distributed training underpins modern AI deployment and research:
- Frontier LLM and multimodal model training
• Pretraining large speech and vision foundation models
• Large-scale recommender systems
• Scientific and climate modeling with neural networks
• National-scale AI compute programs and sovereign AI stacks
Careers here focus on:
• Scaling training throughput efficiently
• Debugging distributed performance bottlenecks
• Designing fault-tolerant training pipelines
• Cost-aware cluster utilization
• Productionizing large-model training workflows
Distributed systems turn model training into an operational engineering discipline, not just a research activity. A constantly updated Whatsapp channel awaits your participation.
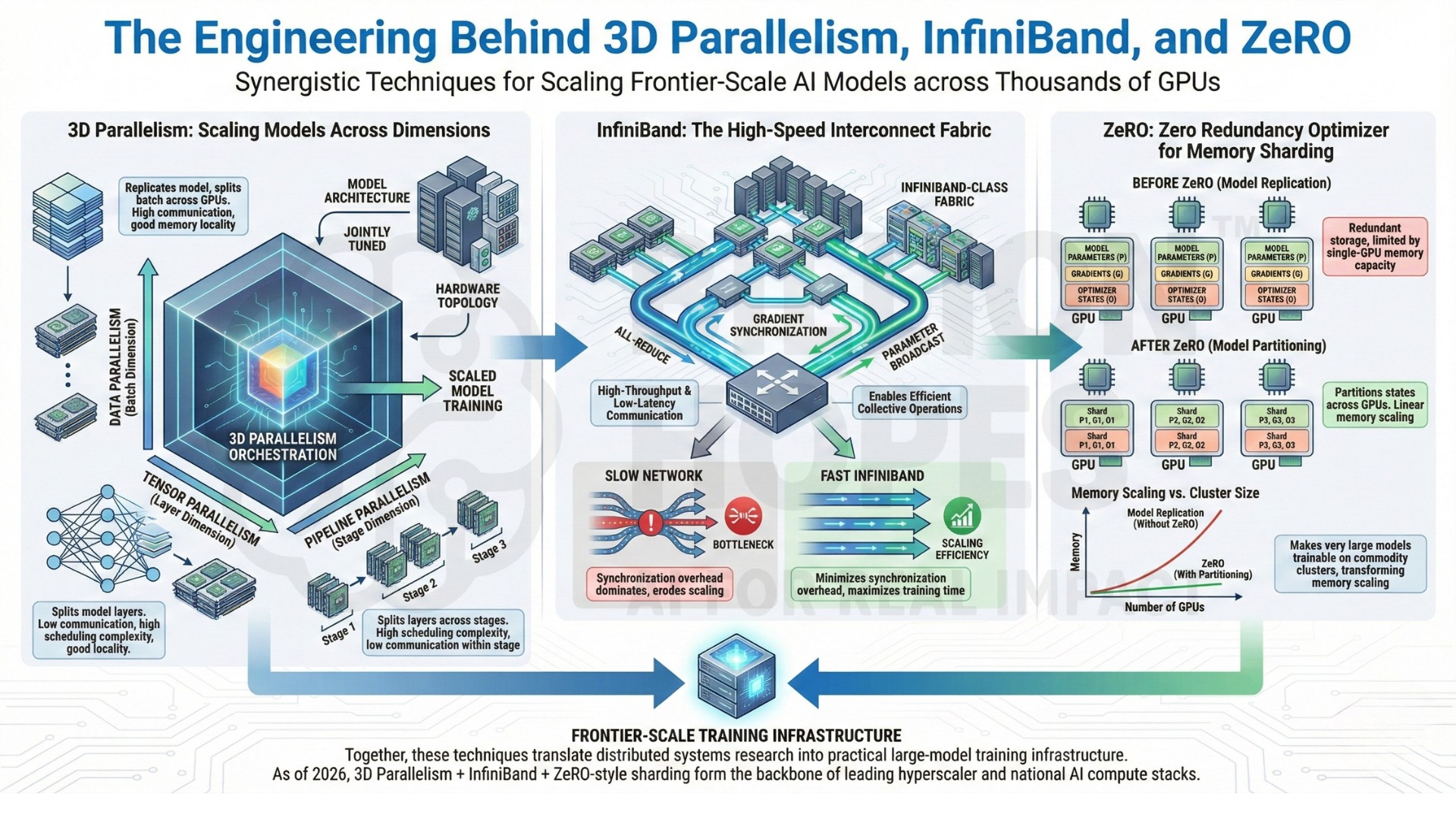
5. The engineering behind 3D parallelism, InfiniBand, and ZeRO
3D parallelism combines data parallelism, tensor parallelism, and pipeline parallelism to scale models across thousands of GPUs. Each dimension trades off communication cost, memory locality, and scheduling complexity. Real-world systems tune these three axes jointly to match model architecture and hardware topology.
InfiniBand-class interconnects enable high-throughput, low-latency GPU-to-GPU communication, making collective operations like all-reduce feasible at scale. Without fast networking, synchronization overhead dominates training time and erodes scaling efficiency.
DeepSpeed ZeRO partitions model states (parameters, gradients, optimizer states) across devices instead of replicating them on every GPU. This transforms memory scaling from quadratic to near-linear in cluster size, making very large models trainable on commodity clusters rather than only elite supercomputing facilities.
Together, these techniques translate distributed systems research into practical large-model training infrastructure.
(As of 2026, 3D parallelism + InfiniBand fabrics + ZeRO-style memory sharding form the backbone of most frontier-scale training stacks used by hyperscalers and national AI compute programs.)
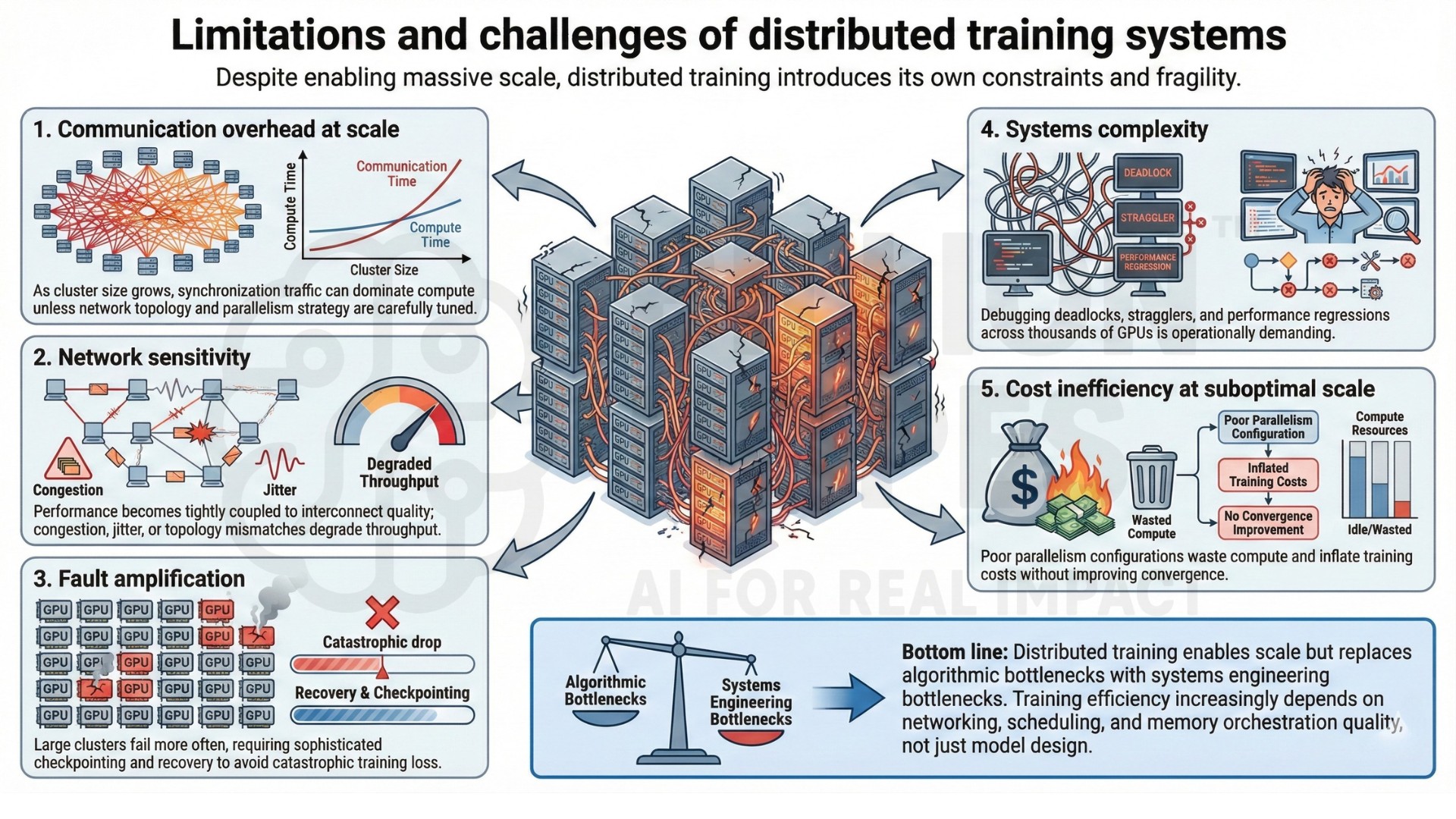
6. Limitations and challenges of distributed training systems
Despite enabling massive scale, distributed training introduces its own constraints and fragility.
Key limitations include:
• Communication overhead at scale – As cluster size grows, synchronization traffic can dominate compute unless network topology and parallelism strategy are carefully tuned.
• Network sensitivity – Performance becomes tightly coupled to interconnect quality; congestion, jitter, or topology mismatches degrade throughput.
• Fault amplification – Large clusters fail more often, requiring sophisticated checkpointing and recovery to avoid catastrophic training loss.
• Systems complexity – Debugging deadlocks, stragglers, and performance regressions across thousands of GPUs is operationally demanding.
• Cost inefficiency at suboptimal scale – Poor parallelism configurations waste compute and inflate training costs without improving convergence.
Bottom line: Distributed training enables scale but replaces algorithmic bottlenecks with systems engineering bottlenecks. Training efficiency increasingly depends on networking, scheduling, and memory orchestration quality, not just model design.
Excellent individualised mentoring programmes available.
7. Skills that define distributed training practitioners
Practitioners working at this layer combine ML with large-scale systems engineering:
- Distributed systems and networking fundamentals
• GPU architecture and memory hierarchy
• Parallel programming and collective communication
• Performance profiling and bottleneck analysis
• Fault tolerance and checkpointing design
This field sits at the intersection of machine learning engineering, high-performance computing, and cloud infrastructure.
8. Backgrounds and entry paths into large-scale systems work
Professionals often enter distributed AI systems from HPC, cloud infrastructure, or large-scale backend engineering. Many ML researchers transition after encountering scaling failures in single-node training setups.
Common entry paths include:
• ML engineering and infrastructure teams
• High-performance computing (HPC)
• Cloud platform and data center engineering
• Distributed systems research
• Large-scale recommender or search systems
A typical trigger is hitting memory, communication, or reliability ceilings when scaling models beyond a few GPUs. Subscribe to our free AI newsletter now.
9. Tensions and trade-offs in large-scale training
Distributed AI systems involve persistent trade-offs:
- Throughput versus convergence stability
• Communication cost versus parallelism granularity
• Memory sharding versus implementation complexity
• Cost efficiency versus peak performance
• Flexibility versus operational reliability
These trade-offs shape how clusters are configured and why optimal parallelism strategies differ between training, fine-tuning, and inference workloads.
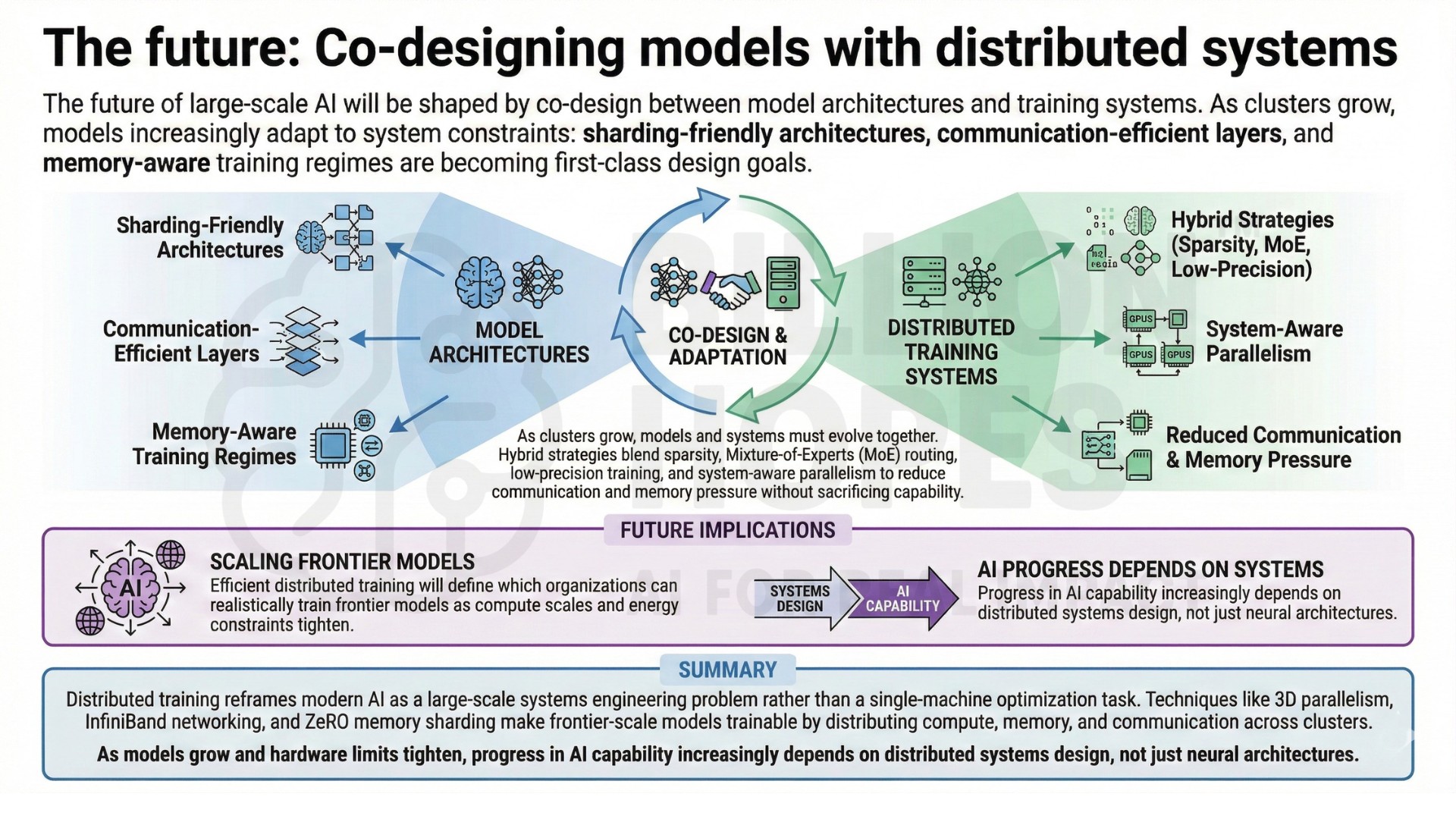
10. The future: Co-designing models with distributed systems
The future of large-scale AI will be shaped by co-design between model architectures and training systems. As clusters grow, models increasingly adapt to system constraints: sharding-friendly architectures, communication-efficient layers, and memory-aware training regimes are becoming first-class design goals.
Hybrid strategies that blend model sparsity, mixture-of-experts routing, low-precision training, and system-aware parallelism aim to reduce communication and memory pressure without sacrificing capability. As compute scales and energy constraints tighten, efficient distributed training will define which organizations can realistically train frontier models. Upgrade your AI-readiness with our masterclass.
Summary
Distributed training reframes modern AI as a large-scale systems engineering problem rather than a single-machine optimization task. Techniques like 3D parallelism, InfiniBand networking, and ZeRO memory sharding make frontier-scale models trainable by distributing compute, memory, and communication across clusters. As models grow and hardware limits tighten, progress in AI capability increasingly depends on distributed systems design, not just neural architectures.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



