Synthetic Data, Simulation & AI Testing Environments Careers

Synthetic Data, Simulation & AI Testing Environments Careers
Generating artificial datasets for training and validation; Simulation platforms for AI system testing; Scenario modeling and stress testing
Introduction
As artificial intelligence moves from experimental demos into real-world products, one question has become central: how do we train and test AI systems safely, fairly, and at scale when real-world data is limited, expensive, private, biased, risky, or incomplete?
This is where synthetic data, simulation, and AI testing environments are becoming career-defining fields. Synthetic data refers to artificial data designed to mimic real-world patterns. It may be generated using statistical methods, rules, simulations, generative AI, digital twins, or agent-based models. IBM describes synthetic data as artificial data that mimics real-world data and can retain the statistical properties of the original data it is based on.
Simulation platforms are equally important. In robotics, autonomous vehicles, manufacturing, defence, healthcare, finance, and enterprise AI, companies cannot test every dangerous, rare, expensive, or ethically sensitive scenario in the real world. Instead, they build virtual worlds, digital twins, controlled synthetic environments, and stress-testing pipelines. NVIDIA Isaac Sim, for example, is positioned as a robotics simulation and synthetic data generation framework built on Omniverse libraries for physically based virtual environments.
By 2026, this career space is expanding because AI systems are becoming more powerful, more regulated, more multimodal, and more safety-critical. The NIST AI Risk Management Framework emphasizes managing risks to individuals, organizations, and society across the AI lifecycle, which directly increases the need for better testing, validation, monitoring, and risk measurement practices.
The emerging career opportunity is clear: future AI teams will not only need people who can build models. They will need professionals who can generate the right data, simulate the right worlds, test the right failures, and prove that AI systems are reliable before they are deployed.
Let’s dive deep into this.
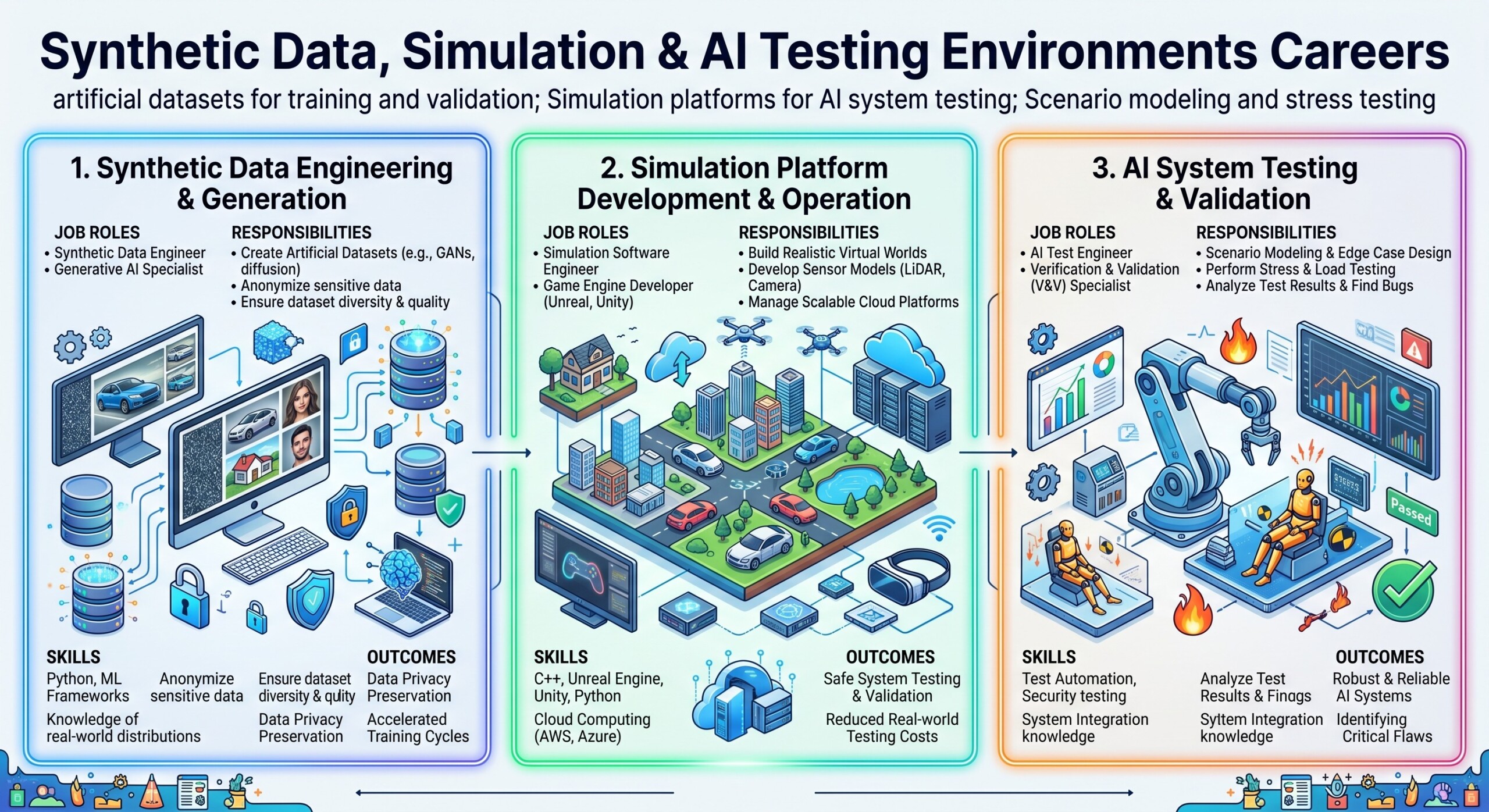
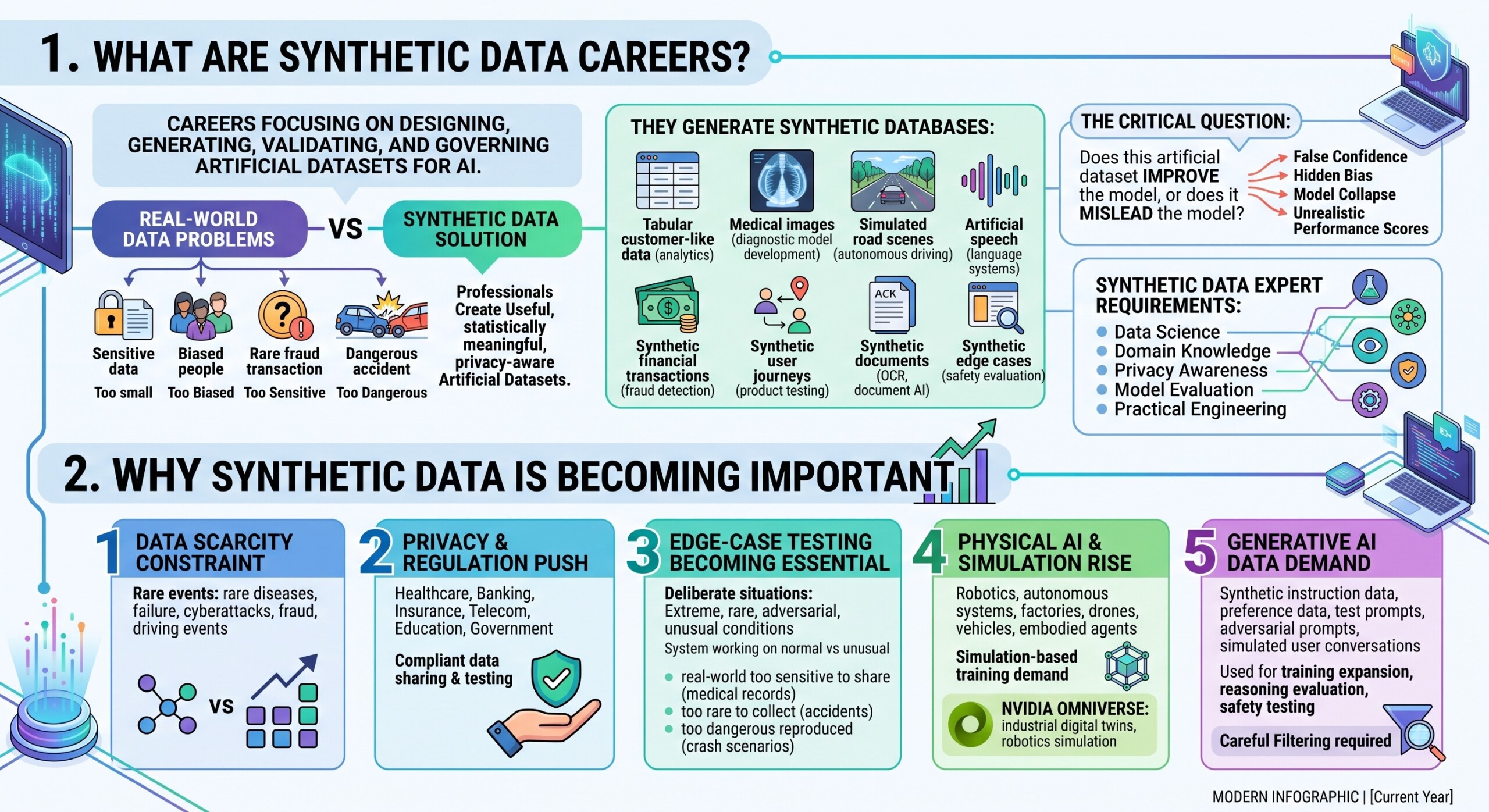
1. What Are Synthetic Data Careers?
Synthetic data careers focus on designing, generating, validating, and governing artificial datasets used for AI training, testing, benchmarking, and privacy-preserving analytics.
In traditional AI development, teams depend heavily on real-world data. But real-world data has many problems. It may be too small, too biased, too sensitive, too expensive to label, or too dangerous to collect. For example, a self-driving car company may not have enough real footage of rare accident scenarios. A hospital may not be able to freely share patient records. A bank may need fraud examples that are rare but extremely important. A robotics company may need thousands of warehouse layouts that do not yet exist physically.
Synthetic data professionals solve this gap by creating artificial but useful datasets.
They may generate:
- tabular customer-like data for analytics and testing,
- medical images for diagnostic model development,
- simulated road scenes for autonomous driving,
- artificial speech for language and voice systems,
- synthetic financial transactions for fraud detection,
- synthetic user journeys for product testing,
- synthetic documents for OCR and document AI,
- synthetic edge cases for safety evaluation.
The career is not simply about “making fake data.” It is about making useful, statistically meaningful, privacy-aware, bias-aware, and task-relevant artificial data.
A good synthetic data expert must ask:
Does this artificial dataset improve the model, or does it mislead the model?
That question is critical because synthetic data can help AI systems generalize, but poor synthetic data can also create false confidence, hidden bias, model collapse, or unrealistic performance scores. This is why synthetic data careers require a combination of data science, domain knowledge, privacy awareness, model evaluation, and practical engineering.
2. Why Synthetic Data is becoming important
Synthetic data is rising because AI is becoming data-hungry while real-world data is becoming harder to collect, label, share, and legally use.
There are several reasons for this growth.
First, data scarcity is a real constraint. Many industries do not have enough high-quality labeled data. Rare diseases, rare machine failures, rare cyberattacks, rare fraud patterns, and rare driving events do not appear frequently enough in real datasets. Synthetic data can create additional examples to improve model training and evaluation.
Second, privacy and regulation are pushing organizations toward safer data practices. Healthcare, banking, insurance, telecom, education, and government systems often contain sensitive personal data. Synthetic data can sometimes allow teams to test software, train models, and share datasets without exposing real identities, though it still requires careful privacy testing.
Third, edge-case testing is becoming essential. Many AI systems work well on normal inputs but fail under unusual conditions. Synthetic data allows teams to create extreme, rare, adversarial, or unusual situations deliberately.
Synthetic data is especially useful when real-world data is:
- too sensitive to share, such as medical or financial records;
- too rare to collect in sufficient quantity, such as accidents or fraud events;
- too dangerous or expensive to reproduce, such as crash scenarios, robot failures, or industrial hazards.
Fourth, the rise of physical AI — robotics, autonomous systems, smart factories, drones, vehicles, and embodied agents — has increased demand for simulation-based training and synthetic data. NVIDIA Omniverse is described as a set of libraries and microservices for building industrial digital twins and robotics simulation applications.
Fifth, generative AI itself has created demand for synthetic instruction data, preference data, test prompts, adversarial prompts, and simulated user conversations. In language-model development, synthetic data may be used to expand training sets, evaluate reasoning, create domain-specific examples, and test safety boundaries. But it must be carefully filtered, because low-quality synthetic data can amplify errors. An excellent collection of learning videos awaits you on our Youtube channel.
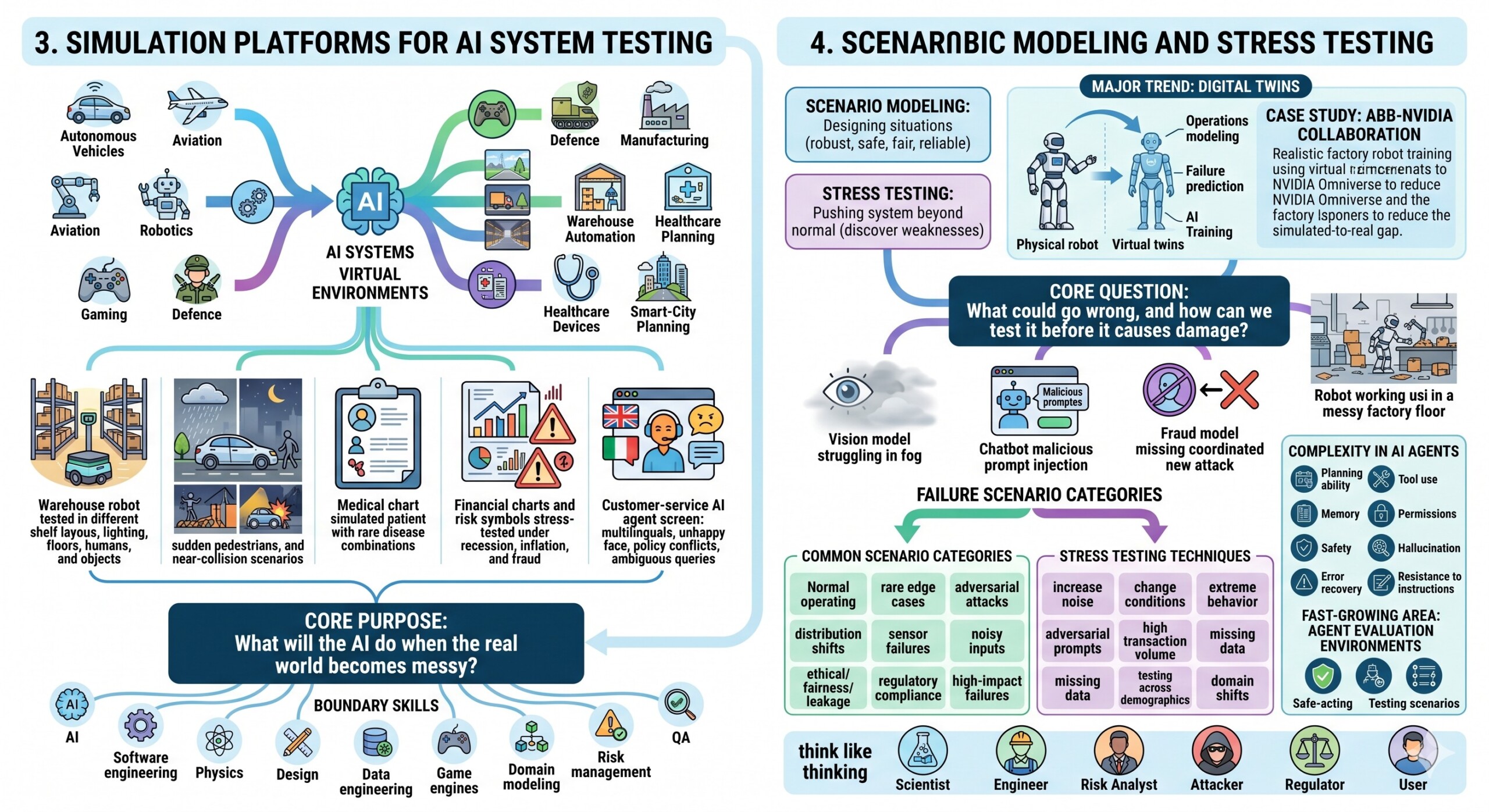
3. Simulation Platforms for AI System Testing
Simulation careers focus on building virtual environments where AI systems can be trained, tested, stressed, and improved before being released into the real world.
Simulation is already central to autonomous vehicles, aviation, robotics, gaming, defence, manufacturing, logistics, warehouse automation, healthcare devices, and smart-city planning. A simulation environment may represent a road, factory floor, warehouse, hospital, financial market, cyber network, call centre, or digital customer journey.
In these environments, AI systems can be exposed to thousands or millions of scenarios.
For example:
- A warehouse robot can be tested against different shelf layouts, lighting conditions, floor surfaces, human movement patterns, and object shapes.
- A self-driving system can be tested in rain, fog, night-time driving, sudden pedestrian crossings, construction zones, and near-collision situations.
- A healthcare AI system can be tested on simulated patient profiles covering rare disease combinations.
- A financial risk model can be stress-tested under recession, inflation, liquidity shock, and fraud attack scenarios.
- A customer-service AI agent can be tested against angry users, ambiguous queries, multilingual requests, policy conflicts, and prompt injection attempts.
The core purpose of simulation is to answer a practical question:
What will the AI system do when the real world becomes messy?
This is why simulation professionals often work at the boundary of AI, software engineering, physics, design, data engineering, game engines, domain modeling, risk management, and quality assurance.
A major trend is the use of digital twins. A digital twin is a virtual representation of a real-world process, machine, factory, city, network, or system. It allows teams to model operations, test changes, predict failures, and train AI agents. In 2026, digital twins are becoming especially important in manufacturing, robotics, energy, logistics, infrastructure, healthcare, and defence.
The ABB–NVIDIA collaboration reported in 2026 is a good example of this direction. ABB partnered with NVIDIA to improve factory robot training through more realistic virtual simulations using Omniverse, aiming to reduce the gap between simulated and real-world robot performance.
4. Scenario Modeling and Stress Testing
Scenario modeling is the discipline of designing situations that test whether an AI system is robust, safe, fair, and reliable under different conditions. Stress testing pushes the system beyond normal operating conditions to discover weaknesses before real users or real environments expose them.
This field is becoming extremely important because average performance is no longer enough.
An AI model may perform well on a benchmark but fail in rare or high-risk cases. A chatbot may answer ordinary questions well but fail under manipulation. A vision model may identify objects in daylight but fail under fog. A fraud model may catch known fraud types but miss a new coordinated attack. A robot may work in a clean test lab but fail in a noisy factory.
Scenario modeling asks:
What could go wrong, and how can we test it before it causes damage?
Common scenario categories include:
- normal operating scenarios,
- rare edge cases,
- adversarial attacks,
- distribution shifts,
- sensor failures,
- noisy or incomplete inputs,
- ethical and fairness scenarios,
- privacy leakage scenarios,
- regulatory compliance scenarios,
- high-impact failure scenarios.
Stress testing may involve:
- increasing input noise,
- changing environmental conditions,
- generating extreme user behavior,
- testing adversarial prompts,
- simulating high transaction volumes,
- introducing missing data,
- testing model performance across demographic groups,
- evaluating failures under domain shift.
For careers, this creates demand for professionals who can think like a scientist, engineer, risk analyst, attacker, regulator, and user at the same time.
In the age of AI agents, scenario testing becomes even more complex. An AI agent may not simply classify or generate text; it may browse, call tools, write code, send emails, update records, trigger workflows, or interact with other systems. Testing such agents requires simulated environments where the agent can act safely without affecting the real world.
This is one of the fastest-growing areas in AI testing: agent evaluation environments. These environments test planning ability, tool use, memory, permissions, safety, hallucination, recovery from errors, and resistance to malicious instructions. A constantly updated Whatsapp channel awaits your participation.
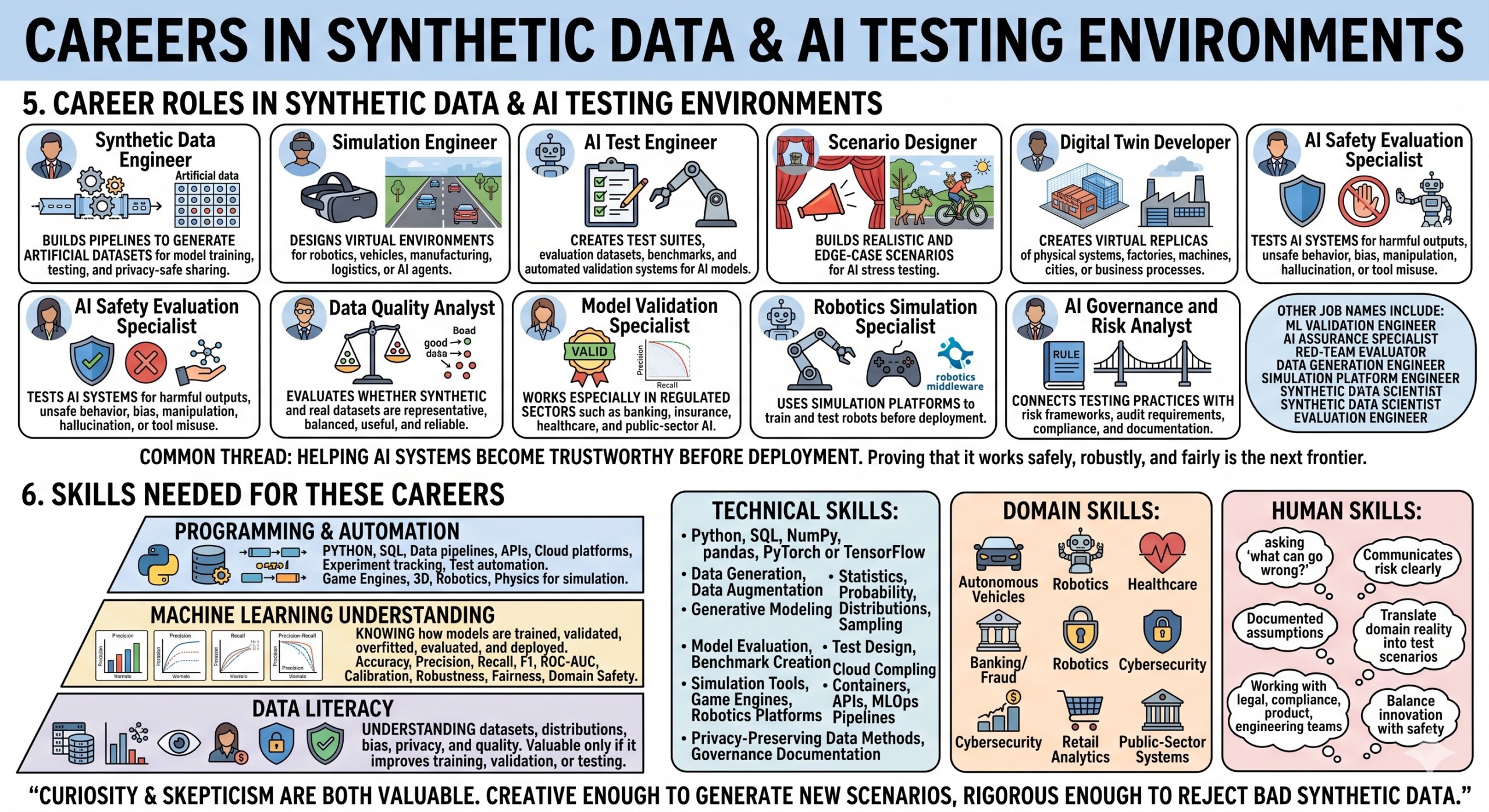
5. Career Roles in Synthetic Data and AI Testing Environments
The career landscape in this field is broad. It is not limited to one job title. It includes technical, analytical, governance, product, and domain-specific roles.
Important career roles include:
- Synthetic Data Engineer: Builds pipelines to generate artificial datasets for model training, testing, and privacy-safe sharing.
- Simulation Engineer: Designs virtual environments for robotics, vehicles, manufacturing, logistics, or AI agents.
- AI Test Engineer: Creates test suites, evaluation datasets, benchmarks, and automated validation systems for AI models.
- Scenario Designer: Builds realistic and edge-case scenarios for AI stress testing.
- Digital Twin Developer: Creates virtual replicas of physical systems, factories, machines, cities, or business processes.
- AI Safety Evaluation Specialist: Tests AI systems for harmful outputs, unsafe behavior, bias, manipulation, hallucination, or tool misuse.
- Data Quality Analyst: Evaluates whether synthetic and real datasets are representative, balanced, useful, and reliable.
- Model Validation Specialist: Works especially in regulated sectors such as banking, insurance, healthcare, and public-sector AI.
- Robotics Simulation Specialist: Uses simulation platforms to train and test robots before deployment.
- AI Governance and Risk Analyst: Connects testing practices with risk frameworks, audit requirements, compliance, and documentation.
These roles may appear under different names in companies. Some organizations may call them ML validation engineers, AI assurance specialists, red-team evaluators, data generation engineers, simulation platform engineers, synthetic data scientists, or evaluation engineers.
The common thread is this:
These professionals help AI systems become trustworthy before they are deployed.
In many organizations, this may become as important as model development itself. Building an AI model is only one part of the lifecycle. Proving that it works safely, robustly, and fairly is the next frontier.
6. Skills Needed for these careers
A successful career in synthetic data, simulation, and AI testing requires a layered skill set. It combines technical competence with practical judgment.
At the foundation, one needs data literacy. This means understanding datasets, distributions, sampling, bias, missing data, labeling, privacy, and quality metrics. Synthetic data is not valuable merely because it is large. It is valuable only if it improves training, validation, or testing.
The second skill is machine learning understanding. Professionals must know how models are trained, validated, overfitted, evaluated, and deployed. They should understand metrics such as accuracy, precision, recall, F1 score, ROC-AUC, calibration, robustness, fairness metrics, and domain-specific safety metrics.
The third skill is programming and automation. Python remains essential. SQL, data pipelines, APIs, cloud platforms, experiment tracking, and test automation are also useful. For simulation-heavy roles, knowledge of game engines, 3D environments, robotics middleware, and physics-based simulation can be valuable.
Useful technical skills include:
- Python, SQL, NumPy, pandas, PyTorch or TensorFlow;
- data generation, data augmentation, and generative modeling;
- statistics, probability, distributions, and sampling;
- model evaluation, test design, and benchmark creation;
- simulation tools, digital twins, game engines, or robotics platforms;
- cloud computing, containers, APIs, and MLOps pipelines;
- privacy-preserving data methods and governance documentation.
Useful domain skills include:
- autonomous vehicles and mobility,
- robotics and manufacturing,
- healthcare and life sciences,
- banking, insurance, and fraud detection,
- cybersecurity,
- retail and customer analytics,
- public-sector and regulatory systems.
Useful human skills include:
- asking “what can go wrong?”,
- communicating risk clearly,
- documenting assumptions,
- translating domain reality into test scenarios,
- working with legal, compliance, product, and engineering teams,
- balancing innovation with safety.
This is a field where curiosity and skepticism are both valuable. You must be creative enough to generate new scenarios, but rigorous enough to reject bad synthetic data. Excellent individualised mentoring programmes available.
7. Industries, opportunities, and future growth
Synthetic data and simulation careers will grow wherever AI must be trained or tested under constraints. This includes both digital AI and physical AI.
In healthcare, synthetic data can help with medical imaging, patient-flow simulation, rare disease modeling, clinical trial planning, and privacy-aware analytics. However, healthcare synthetic data must be handled carefully because poor simulation can create dangerous conclusions.
In finance, synthetic transaction data can support fraud detection, stress testing, model validation, anti-money laundering systems, customer analytics, and privacy-preserving testing. Banks and insurers already have strong model-risk-management cultures, making AI validation roles especially relevant.
In autonomous vehicles and mobility, simulation is fundamental. Real roads cannot provide every possible rare event, weather condition, accident pattern, or pedestrian behavior. Synthetic scenes and simulation platforms help create diverse driving conditions for training and testing.
In robotics and manufacturing, simulation allows companies to train robots in virtual factories before deploying them physically. NVIDIA has highlighted the use of synthetic data and simulation for physical AI, including robotics training across varied conditions.
In cybersecurity, synthetic attack data and simulated networks can help train detection models, test response systems, and evaluate AI security tools without exposing real infrastructure.
In enterprise AI, synthetic documents, synthetic customer conversations, simulated workflows, and agent testing environments will become increasingly important. As AI agents enter business operations, companies will need safe testbeds where agents can make mistakes without damaging real systems.
The future career opportunity is not only technical. There will also be demand for educators, auditors, consultants, policy experts, and product managers who understand synthetic data and AI testing environments. Companies will need people who can explain why a model is ready, where it is weak, and what evidence supports deployment.
The strongest career positioning will be at the intersection of three areas:
AI knowledge + domain expertise + testing discipline
Someone who understands AI and healthcare simulation will be valuable. Someone who understands AI and financial stress testing will be valuable. Someone who understands AI and robotics simulation will be valuable. The best careers will belong to people who can connect model behavior with real-world risk. Subscribe to our free AI newsletter now.
Conclusion
Synthetic data, simulation, and AI testing environments are becoming one of the most important career frontiers in artificial intelligence. As AI systems become more powerful and more deeply embedded in real life, the need for better data, better testing, and better risk measurement will only increase.
Synthetic data helps overcome data scarcity, privacy limits, rare-event shortages, and expensive labeling. Simulation platforms allow AI systems to be tested in virtual worlds before facing the real one. Scenario modeling and stress testing reveal weaknesses that average benchmarks often hide.
For students, professionals, and career switchers, this field offers a powerful opportunity. It combines data science, machine learning, software engineering, simulation, risk thinking, domain knowledge, and AI governance. It is useful across healthcare, finance, robotics, autonomous vehicles, manufacturing, cybersecurity, and enterprise AI.
The big lesson is simple:
The future of AI will not depend only on who builds the smartest models.
It will also depend on who can create the best training environments, the most realistic simulations, the strongest test scenarios, and the clearest evidence that AI systems are safe, reliable, and ready for the real world. Upgrade your AI-readiness with our masterclass.
Share this with the world
Related Articles



