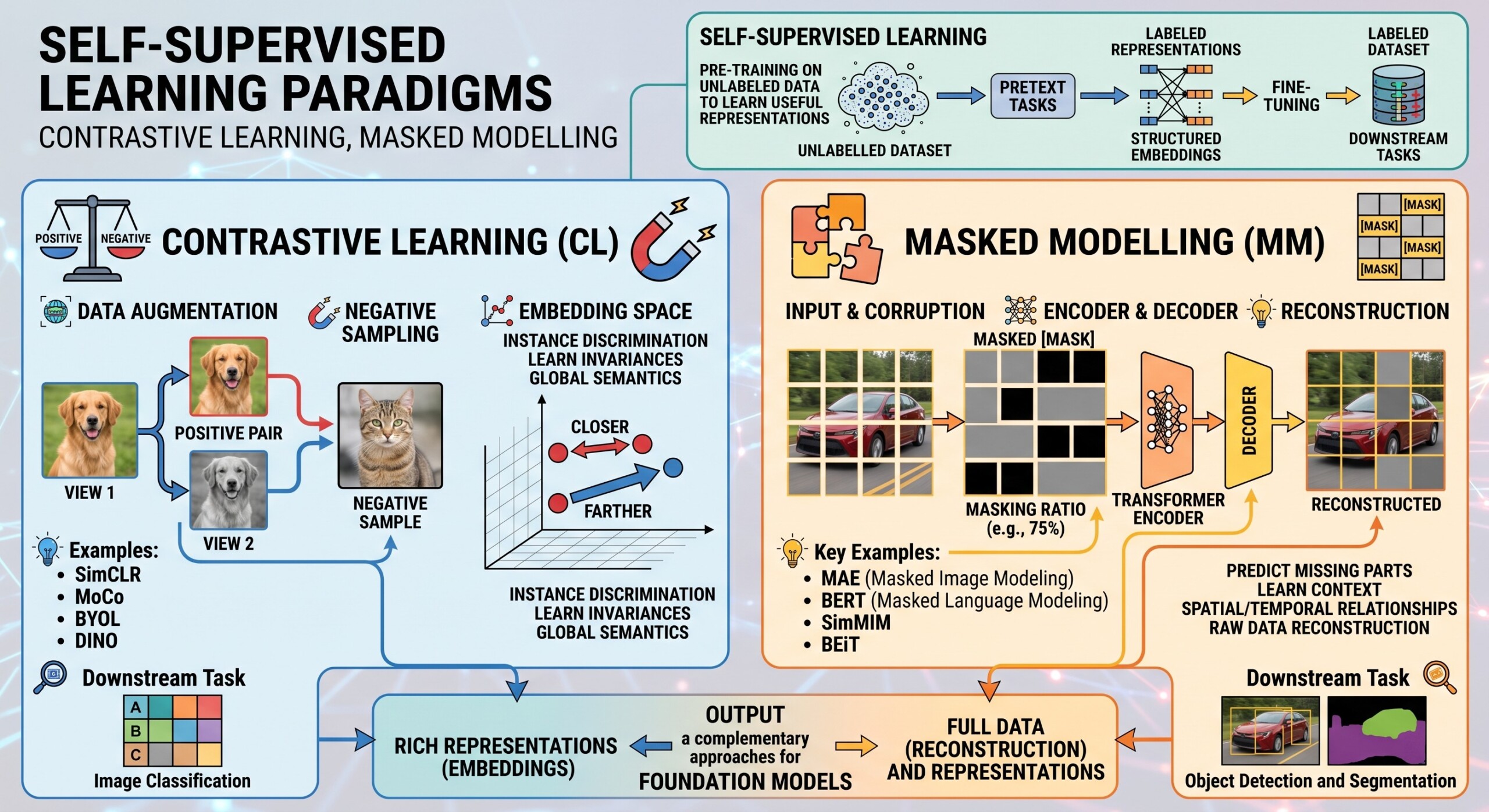
Self-Supervised Learning Paradigms

Self-Supervised Learning Paradigms
Contrastive learning, Masked modelling
Introduction
Self-Supervised Learning (SSL) has emerged as one of the most powerful paradigms in modern Machine Learning, especially in scenarios where labeled data is scarce or expensive. Instead of relying on human-annotated datasets, SSL leverages the inherent structure in data to generate its own supervision signals.
At its core, SSL transforms unlabeled data into supervised signals by designing proxy objectives – tasks where the “labels” are derived from the data itself. This allows models to learn deep representations without manual annotation, dramatically reducing dependency on costly labeling pipelines.
Two dominant paradigms define the modern SSL landscape:
- Contrastive Learning → learning by comparing similarities and differences
- Masked Modelling → learning by reconstructing hidden or missing information
These paradigms power influential systems like BERT in NLP and SimCLR in computer vision.
Let’s dive deep into the topic.
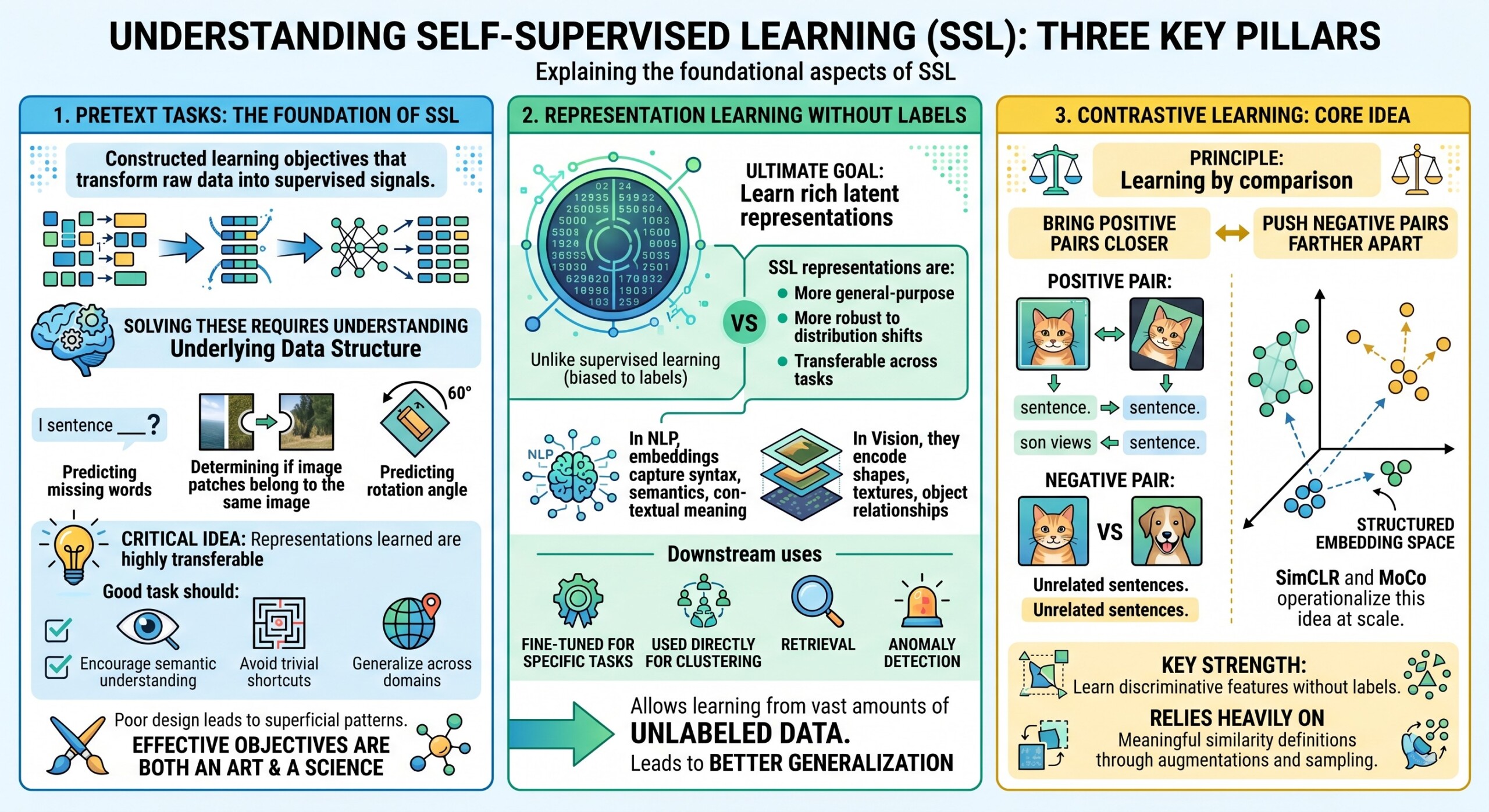
1. Pretext Tasks: The foundation of SSL
Pretext tasks are artificially constructed learning objectives that transform raw data into supervised signals. They act as the bridge between unlabeled data and meaningful learning.
These tasks are carefully designed so that solving them requires understanding underlying data structure. For example:
- Predicting missing words in a sentence
- Determining whether two image patches belong to the same image
- Predicting the rotation angle applied to an image
The critical idea is that while the task itself may not be directly useful (e.g., rotation prediction), the representations learned while solving it are highly transferable.
A good pretext task should:
- Encourage semantic understanding
- Avoid trivial shortcuts (e.g., exploiting noise patterns)
- Generalize across domains
Poorly designed pretext tasks can lead to models learning superficial patterns rather than meaningful features. Thus, designing effective pretext objectives is both an art and a science.
2. Representation learning without labels
The ultimate goal of SSL is to learn rich latent representations – compact numerical embeddings that encode meaningful patterns in data.
Unlike supervised learning, where representations are biased toward specific labels, SSL representations are:
- More general-purpose
- More robust to distribution shifts
- Transferable across tasks
For example:
- In NLP, embeddings capture syntax, semantics, and contextual meaning
- In vision, they encode shapes, textures, and object relationships
These learned representations can then be:
- Fine-tuned for specific tasks
- Used directly for clustering, retrieval, or anomaly detection
An important advantage is that SSL allows learning from vast amounts of unlabeled data, which is often orders of magnitude larger than labeled datasets. This leads to better generalization and performance in real-world scenarios. An excellent collection of learning videos awaits you on our Youtube channel.
3. Contrastive Learning: Core idea
Contrastive learning is based on a simple but powerful principle: learning by comparison.
The model is trained to:
- Bring positive pairs closer in representation space
- Push negative pairs farther apart
A positive pair might be:
- Two augmented versions of the same image
- Two views of the same sentence
Negative pairs are typically:
- Different images
- Unrelated sentences
This creates a structured embedding space where similar items cluster together.
Frameworks like SimCLR and MoCo operationalize this idea at scale.
A key strength of contrastive learning is its ability to learn discriminative features without labels. However, it relies heavily on defining meaningful similarity through augmentations and sampling strategies.
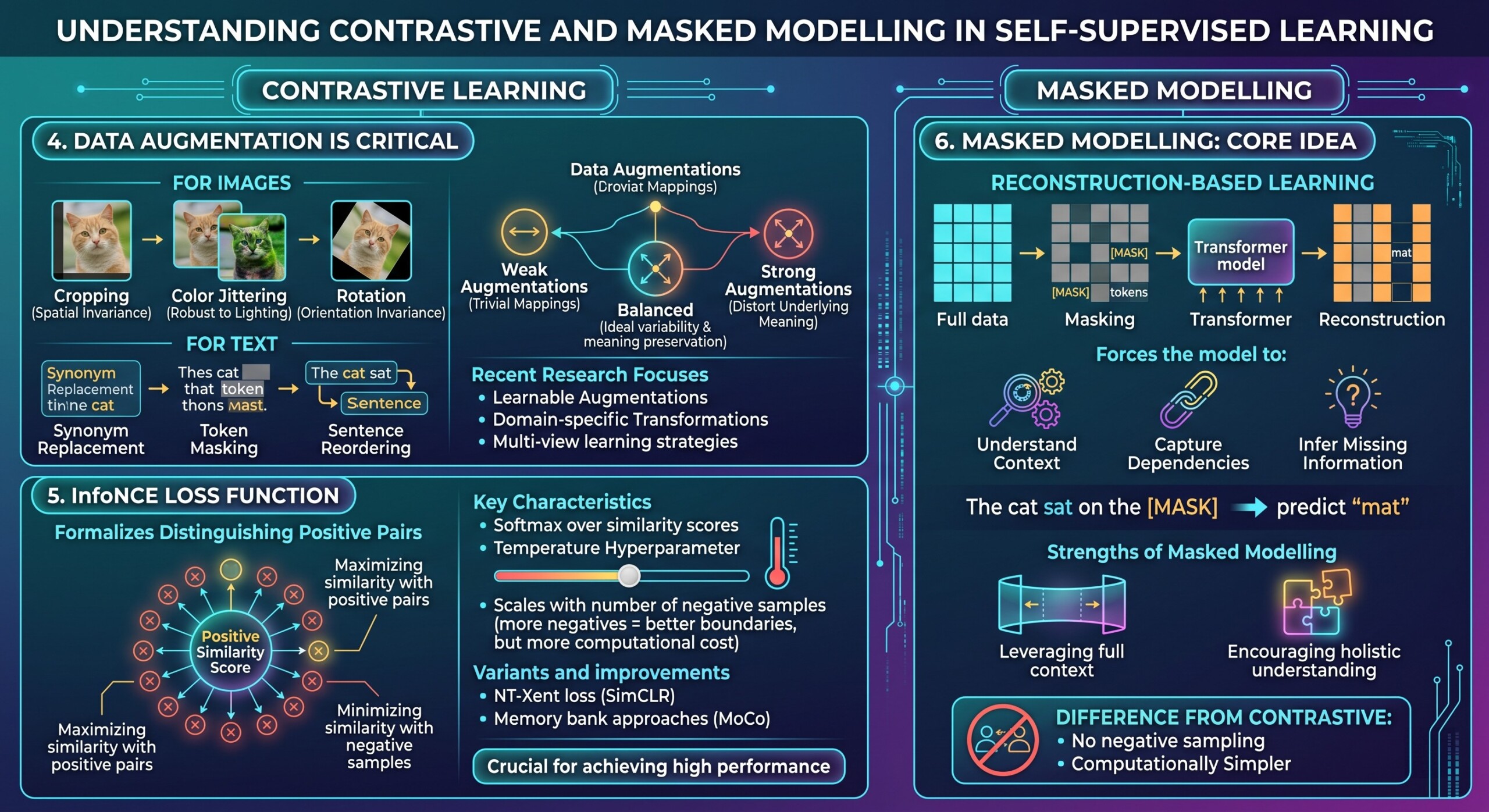
4. Data augmentation is critical
In contrastive learning, augmentations define the notion of “similarity.” Without proper augmentations, the model may fail to learn useful representations.
For images:
- Cropping encourages spatial invariance
- Color jittering encourages robustness to lighting
- Rotation encourages orientation invariance
For text:
- Synonym replacement
- Token masking
- Sentence reordering
The challenge lies in designing augmentations that:
- Preserve semantic meaning
- Introduce sufficient variability
If augmentations are too weak, the model learns trivial identity mappings. If too strong, they may distort the underlying meaning.
Recent research focuses on:
- Learnable augmentations
- Domain-specific transformations
- Multi-view learning strategies
Thus, augmentation design is a core driver of contrastive learning success. A constantly updated Whatsapp channel awaits your participation.
5. InfoNCE loss function
The InfoNCE loss is widely used in contrastive learning to formalize the objective of distinguishing positive pairs from negatives.
It works by:
- Maximizing similarity between positive pairs
- Minimizing similarity with negative samples
Mathematically, it converts the problem into a classification task where the model must identify the correct positive among many candidates.
Key characteristics:
- Uses softmax over similarity scores
- Sensitive to temperature hyperparameter
- Scales with number of negative samples
The more negative samples included, the better the model can learn discriminative boundaries. However, this also increases computational cost.
Variants and improvements include:
- NT-Xent loss (used in SimCLR)
- Memory bank approaches (MoCo)
Understanding and tuning this loss function is crucial for achieving high performance in contrastive frameworks.
6. Masked Modelling: core idea
Masked modelling focuses on reconstruction-based learning. Instead of comparing samples, it removes parts of the input and trains the model to predict them.
This forces the model to:
- Understand context
- Capture dependencies
- Infer missing information
For example:
“The cat sat on the [MASK]” → predict “mat”
Models like BERT use this approach to learn deep contextual embeddings.
The strength of masked modelling lies in:
- Leveraging full context
- Encouraging holistic understanding
Unlike contrastive learning, it does not require negative sampling, making it computationally simpler in many cases. Excellent individualised mentoring programmes available.
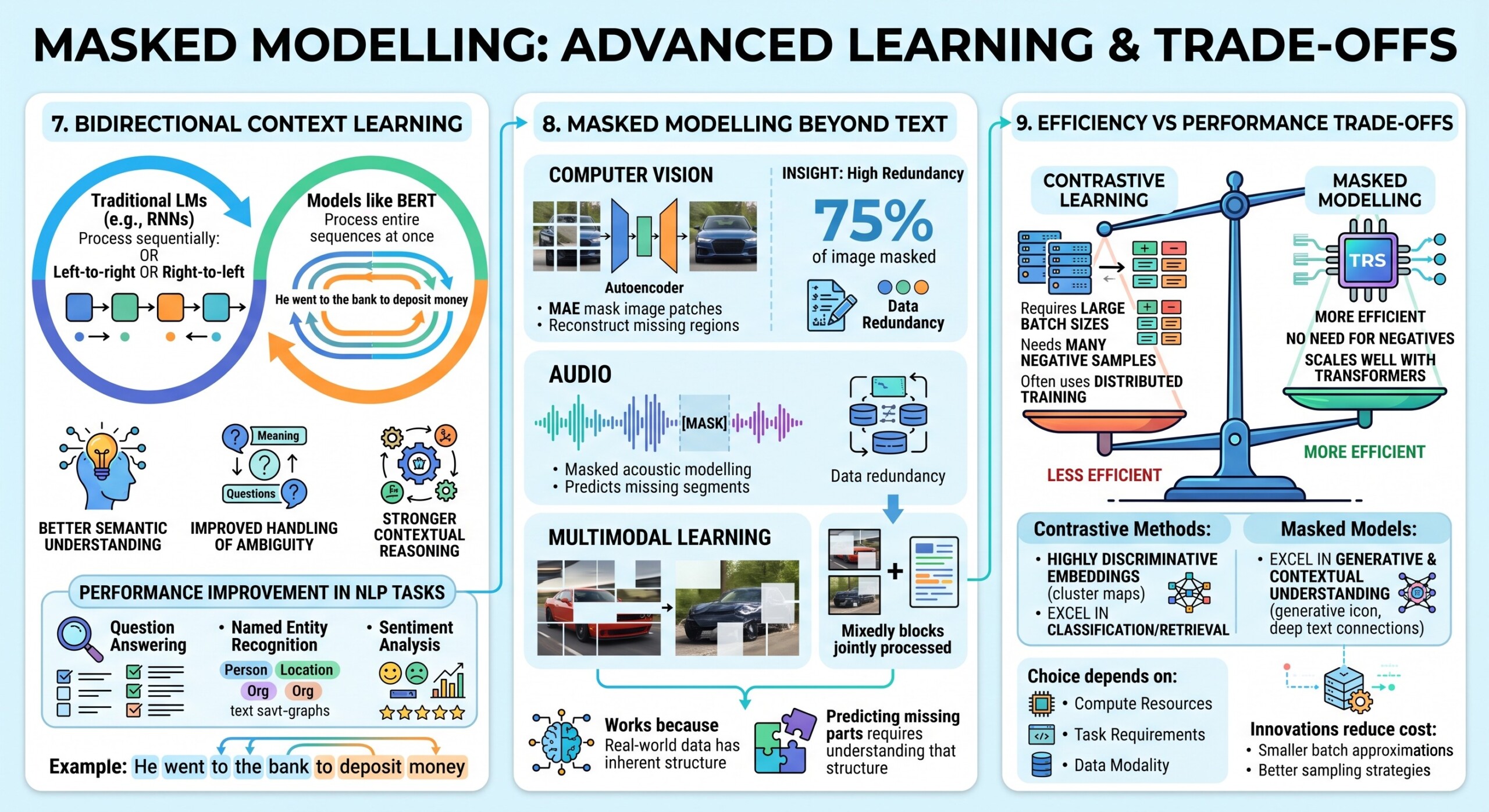
7. Bidirectional context learning
Masked modelling enables bidirectional learning, meaning the model can use both past and future context simultaneously.
Traditional language models (like early RNNs) process text:
- Left-to-right or right-to-left
In contrast, models like BERT process:
- Entire sequences at once
This allows:
- Better semantic understanding
- Improved handling of ambiguity
- Stronger contextual reasoning
For example:
“He went to the bank to deposit money” vs “He sat by the river bank”
Bidirectional models can distinguish meanings based on full sentence context.
This paradigm shift significantly improved performance across NLP tasks such as:
- Question answering
- Named entity recognition
- Sentiment analysis
8. Masked modelling beyond text
Masked modelling has expanded beyond NLP into multiple domains, showing its versatility.
In computer vision:
- Masked Autoencoders (MAE) mask image patches
- Models reconstruct missing visual regions
In audio:
- Masked acoustic modelling predicts missing waveform segments
In multimodal learning:
- Models mask parts of images and text jointly
This approach works because:
- Real-world data has inherent structure
- Predicting missing parts requires understanding that structure
A surprising insight from vision research is that masking large portions (e.g., 75% of an image) still leads to strong learning, indicating high redundancy in visual data. Subscribe to our free AI newsletter now.
9. Efficiency vs Performance trade-offs
Contrastive and masked approaches differ significantly in computational characteristics.
Contrastive Learning:
- Requires large batch sizes
- Needs many negative samples
- Often uses distributed training
Masked Modelling:
- More efficient
- No need for negatives
- Scales well with transformers
However:
- Contrastive methods often produce highly discriminative embeddings
- Masked models excel in generative and contextual understanding
The choice depends on:
- Available compute resources
- Task requirements
- Data modality
Recent innovations aim to reduce contrastive learning cost via:
- Smaller batch approximations
- Better sampling strategies
10. Hybrid approaches are emerging
Modern research increasingly combines contrastive and masked paradigms to leverage their complementary strengths.
Examples include:
- Joint contrastive + reconstruction objectives
- Vision-language models aligning text and images
- Multimodal transformers learning shared embeddings
These hybrid models:
- Improve robustness
- Capture both discriminative and generative features
- Perform well across diverse tasks
For instance:
- Contrastive loss ensures alignment across modalities
- Masked loss ensures deep contextual understanding
Such approaches are central to next-generation AI systems, including:
- Multimodal assistants
- Retrieval-augmented systems
- Foundation models
Conclusion
Self-Supervised Learning represents a fundamental shift in how AI systems are trained. By removing the dependency on labeled data, it enables scalable, flexible, and domain-agnostic learning.
- Contrastive Learning builds powerful discriminative representations through comparison
- Masked Modelling builds deep contextual understanding through reconstruction
Together, they power state-of-the-art systems like BERT and advanced multimodal architectures.
As the volume of unlabeled data continues to grow exponentially, SSL is poised to become the default paradigm in AI – driving innovation across industries and bringing machine intelligence closer to human-like learning. Upgrade your AI-readiness with our masterclass.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



