Quantization & Model Compression Techniques

Quantization & Model Compression Techniques
INT8, 4-bit, Pruning, Distillation
Introduction
Modern AI models are powerful, but they are also heavy. Large language models, vision models, speech models, and recommendation systems often require huge memory, powerful GPUs, high electricity consumption, and expensive infrastructure. This creates a major challenge: how can we make AI models smaller, faster, cheaper, and easier to deploy without losing too much accuracy?
This is where quantization and model compression techniques become important. These techniques reduce the size and computational cost of models so that they can run efficiently on cloud servers, edge devices, mobile phones, laptops, and embedded systems. Instead of always building bigger models, AI engineers also focus on making models leaner and more practical.
The four major techniques in this lecture are INT8 quantization, 4-bit quantization, pruning, and distillation. Quantization reduces the numerical precision of model weights and activations. Pruning removes unnecessary parts of a model. Distillation trains a smaller model to imitate a larger model. Together, these methods help convert large AI systems into usable, deployable, and cost-efficient solutions.
Let’s dive deep into the topic now.
1. Why model compression is needed
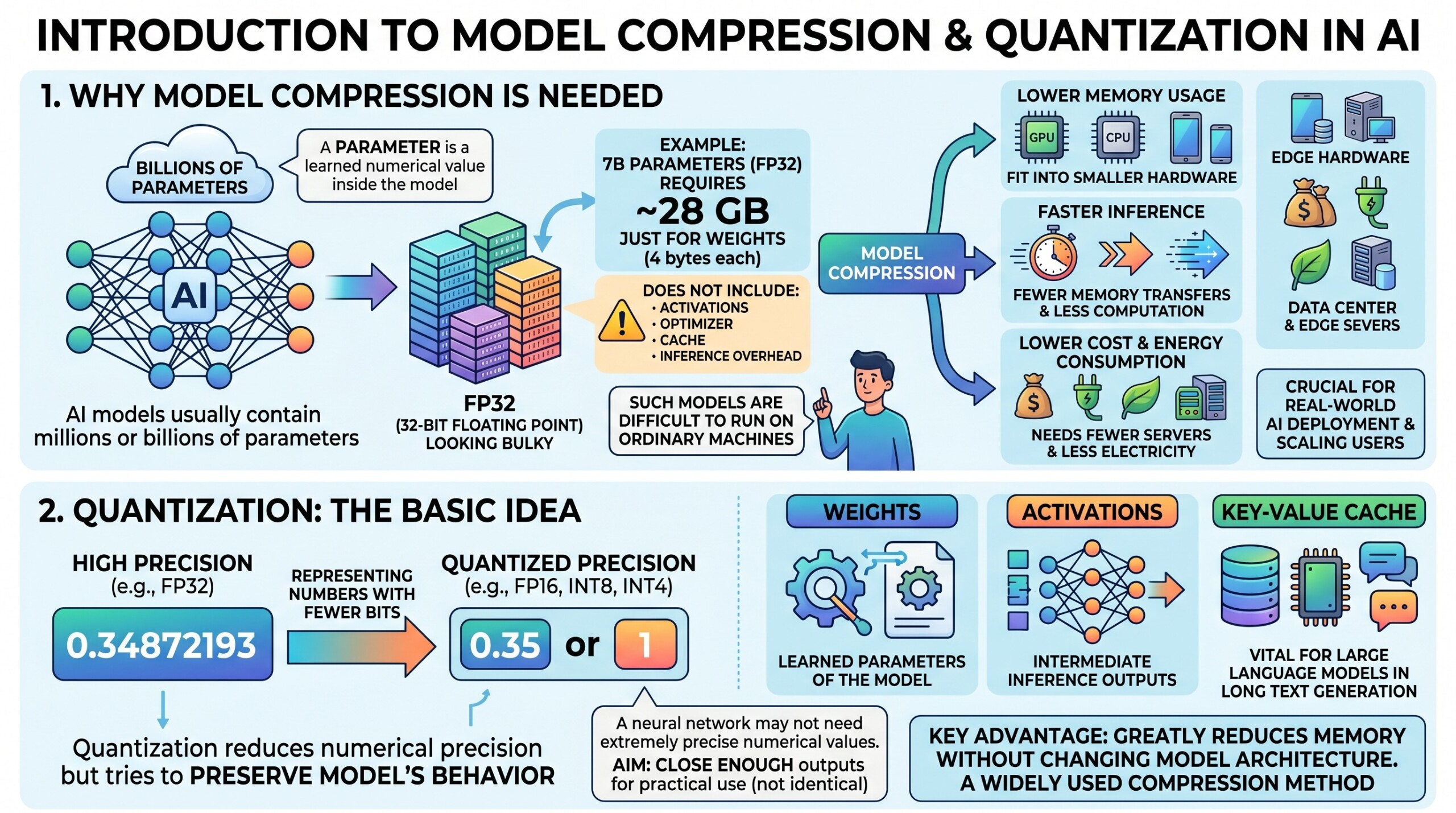
AI models usually contain millions or billions of parameters. A parameter is a learned numerical value inside the model, and these values are normally stored using high precision formats such as FP32, meaning 32-bit floating point numbers. When a model has billions of such parameters, the memory requirement becomes extremely large.
For example, a model with 7 billion parameters stored in FP32 may require around 28 GB just for weights, because each parameter takes 4 bytes. This does not include extra memory needed for activations, optimizer states, cache, or inference overhead. Such models are difficult to run on ordinary machines.
Model compression reduces this burden. It helps in:
- Lower memory usage, so models can fit into smaller GPUs, CPUs, mobile devices, and edge hardware.
- Faster inference, because smaller and lower-precision models require fewer memory transfers and less computation.
- Lower cost and energy consumption, because efficient models need fewer servers and less electricity.
This is especially important in real-world AI deployment. A model that performs well in a research lab is not enough if it is too slow, too expensive, or too large to serve users at scale.
2. Quantization: the basic idea
Quantization means representing model numbers with fewer bits. Instead of storing weights and activations as 32-bit floating point values, we can store them as 16-bit, 8-bit, 4-bit, or sometimes even lower precision values.
The basic idea is simple. A neural network may not need extremely precise numerical values for every weight. If a weight is stored as 0.34872193, the model may still work well if it is stored approximately as 0.35 or as an integer representation that can be converted back during computation. Quantization reduces the numerical precision but tries to preserve the model’s behaviour. The aim is not to make the model mathematically identical, but to make its outputs close enough for practical use.
Quantization can be applied to:
- Weights, which are the learned parameters of the model.
- Activations, which are intermediate outputs generated during inference.
- Key-value cache, which is especially important in large language models during long text generation.
The biggest advantage of quantization is that it can greatly reduce memory without changing the model architecture. This makes it one of the most widely used compression methods in modern AI. An excellent collection of learning videos awaits you on our Youtube channel.
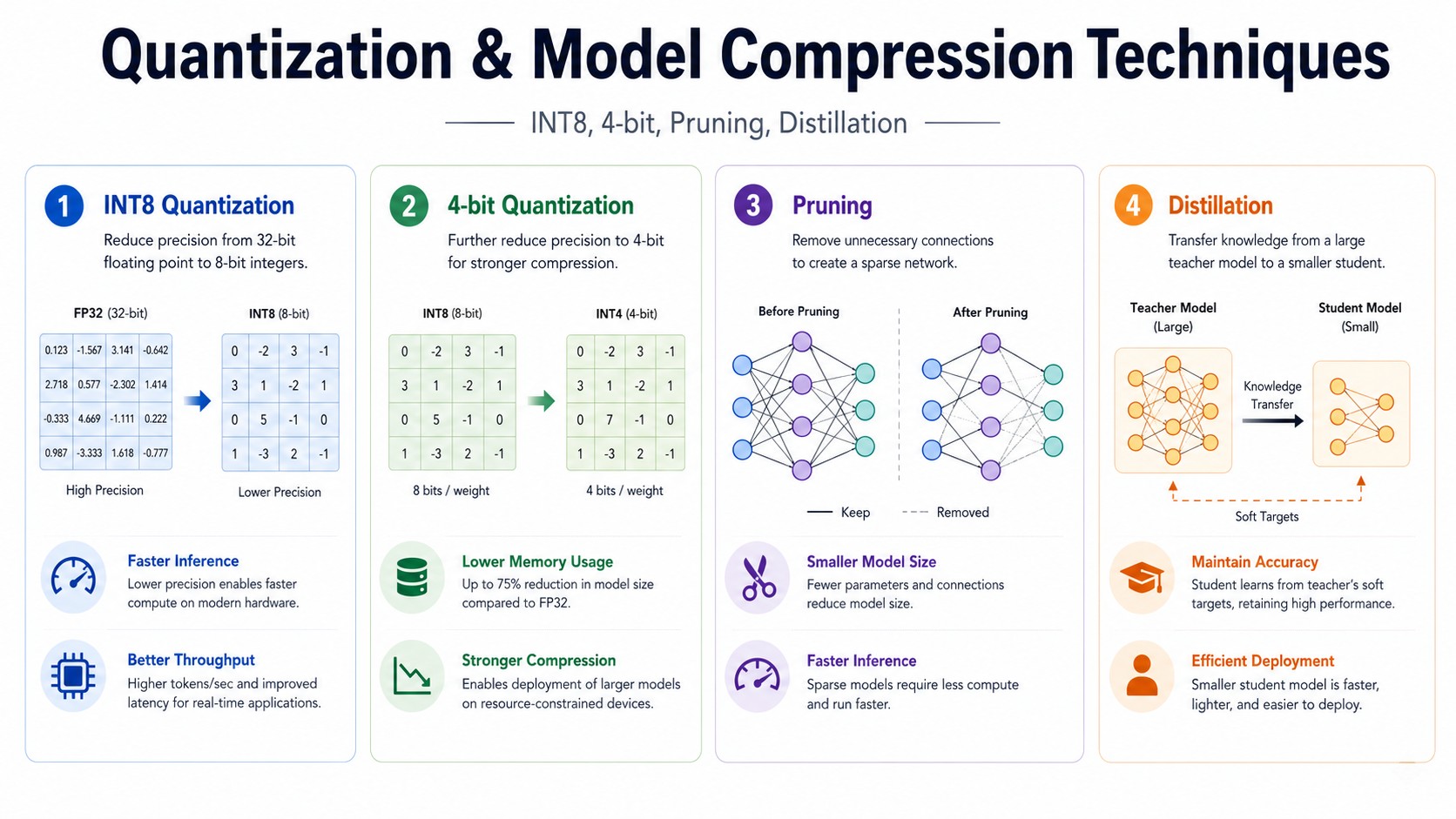
3. INT8 quantization
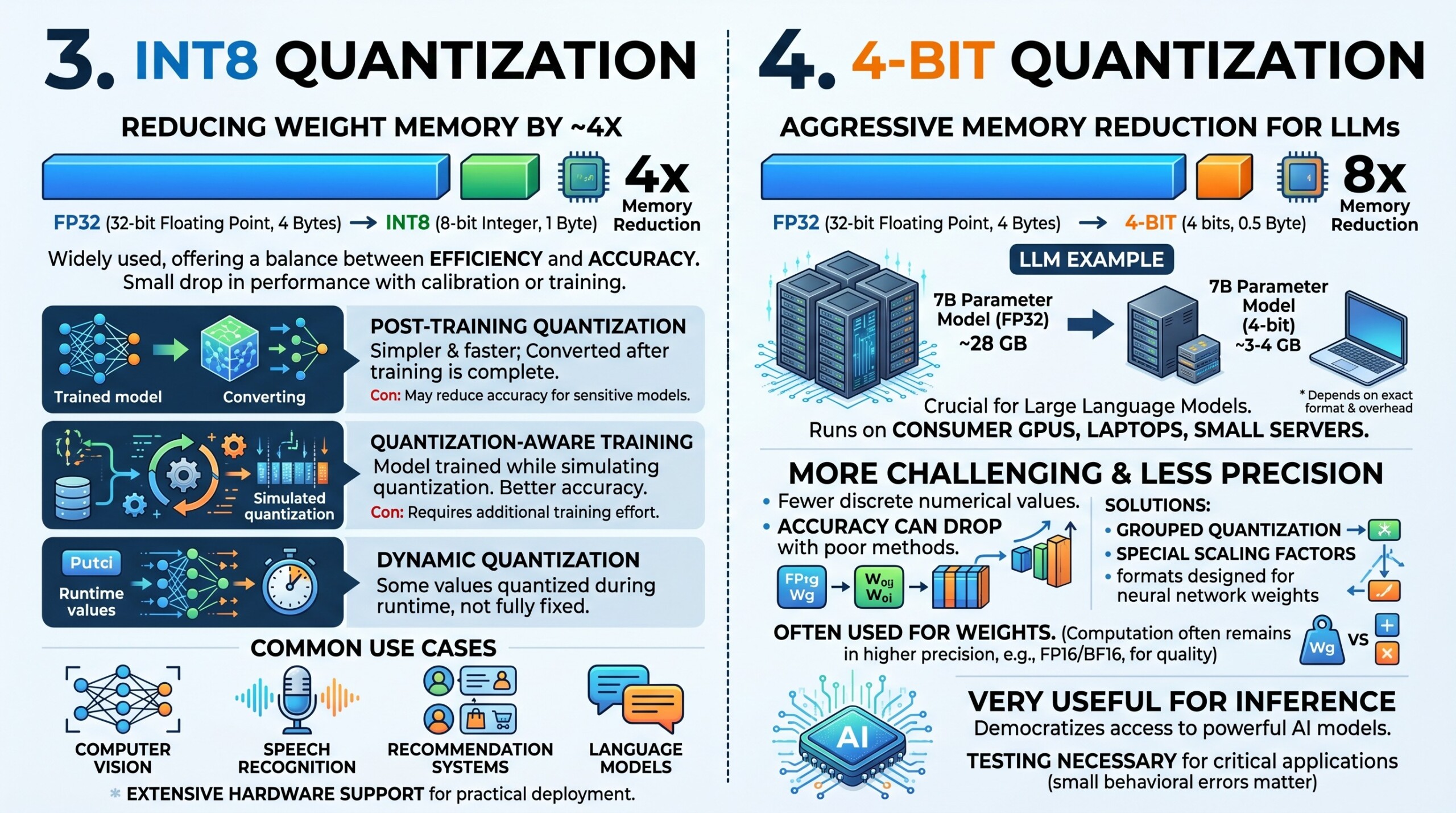
INT8 quantization stores model values using 8-bit integers instead of 32-bit floating point numbers. Since 8 bits use only 1 byte, while FP32 uses 4 bytes, INT8 can reduce weight memory by roughly 4 times compared to FP32.
INT8 is widely used because it offers a good balance between efficiency and accuracy. Many models can be converted to INT8 with only a small drop in performance, especially when proper calibration or quantization-aware training is used.
There are two common approaches to INT8 quantization:
- Post-training quantization, where a trained model is converted to INT8 after training is complete.
- Quantization-aware training, where the model is trained or fine-tuned while simulating quantization effects.
- Dynamic quantization, where some values are quantized during runtime rather than fully fixed in advance.
Post-training quantization is simpler and faster because it does not require retraining. However, it may reduce accuracy if the model is sensitive to precision changes. Quantization-aware training usually gives better accuracy, but it requires additional training effort.
INT8 is commonly used in computer vision models, speech recognition models, recommendation systems, and increasingly in language models. It is also supported by many hardware platforms, which makes it practical for deployment.
4. 4-bit quantization
4-bit quantization is a more aggressive form of quantization where model values are represented using only 4 bits. Since 4 bits are half a byte, this can theoretically reduce memory usage by about 8 times compared to FP32.
This is especially important for large language models. A 7 billion parameter model that may require around 28 GB in FP32 can be reduced to roughly 3.5 to 4 GB in 4-bit form, depending on the exact format and overhead. This makes it possible to run models on consumer GPUs, laptops, and smaller servers.
However, 4-bit quantization is more challenging than INT8. With fewer possible numerical values, the model has less precision, and accuracy can drop if the quantization method is poor. That is why modern 4-bit methods use smarter techniques such as grouped quantization, special scaling factors, and formats designed for neural network weights. In large language models, 4-bit quantization is often used mainly for weights, while some computation may still happen in higher precision such as FP16 or BF16. This helps reduce memory while preserving reasonable output quality.
4-bit quantization is very useful for inference. It allows more people and organisations to use powerful AI models without needing very expensive hardware. However, for critical applications, testing is necessary because small errors in model behaviour can matter. A constantly updated Whatsapp channel awaits your participation.
5. Difference between INT8 and 4-bit quantization
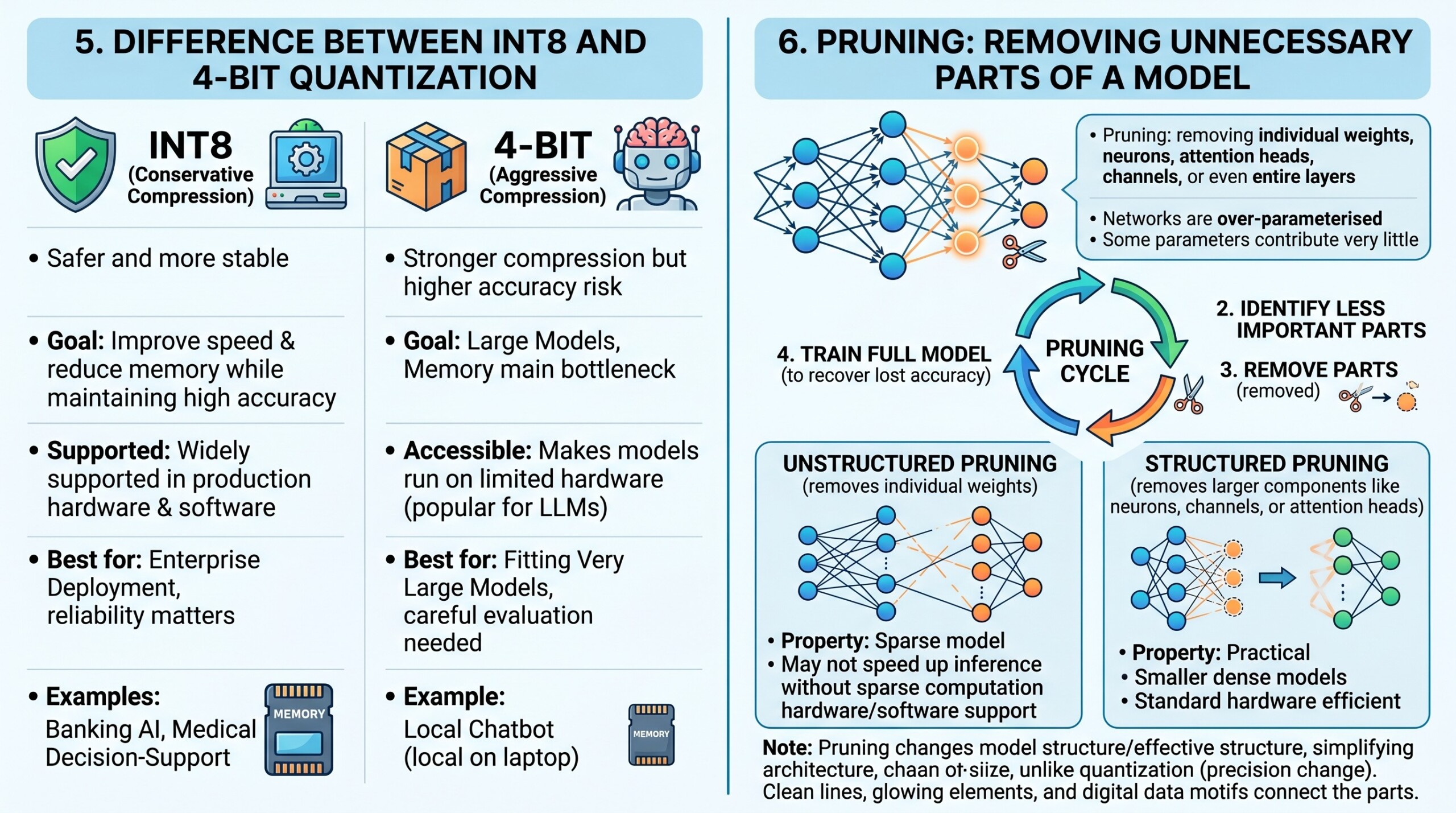
INT8 and 4-bit quantization both reduce precision, but they serve slightly different needs. INT8 is usually safer and more stable, while 4-bit gives stronger compression but may involve more accuracy risk.
INT8 is often suitable when the goal is to improve speed and reduce memory while maintaining high accuracy. It is widely supported in production hardware and software. It is commonly used in enterprise deployment where reliability matters.
4-bit quantization is more suitable when the model is very large and memory is the main bottleneck. It is especially popular for large language models because it allows models to run on limited hardware. The trade-off is that careful evaluation becomes more important. A simple comparison is that INT8 is conservative compression, while 4-bit is aggressive compression. INT8 focuses on dependable efficiency, while 4-bit focuses on making very large models accessible.
The choice depends on the use case. A banking AI system or medical decision-support model may prefer INT8 or higher precision for reliability. A chatbot running locally on a laptop may use 4-bit quantization to fit within memory limits.
6. Pruning: removing unnecessary parts of a model
Pruning means removing parts of a neural network that are considered less important. These parts may include individual weights, neurons, attention heads, channels, or even entire layers.
The idea comes from the observation that many neural networks are over-parameterised. They contain more parameters than strictly necessary for a particular task. Some parameters contribute very little to the final output, so removing them may not significantly harm performance.
There are two broad types of pruning. Unstructured pruning removes individual weights, making the model sparse. Structured pruning removes larger components such as neurons, channels, or attention heads, making the model easier to speed up on normal hardware.
Unstructured pruning can reduce the number of active weights, but it may not always make inference faster unless the hardware and software support sparse computation. Structured pruning is often more practical because it produces smaller dense models that standard hardware can run efficiently. Pruning usually follows a cycle. First, train a full model. Second, identify less important parts. Third, remove them. Fourth, fine-tune the model to recover lost accuracy.
Pruning is useful when the goal is to simplify the model architecture itself. Unlike quantization, which changes numerical precision, pruning changes the structure or effective structure of the network. Excellent individualised mentoring programmes available.
7. Knowledge distillation
Knowledge distillation is a compression method where a smaller model learns from a larger model. The large model is called the teacher model, and the smaller model is called the student model.
Instead of training the student only on the original labels, the student learns from the teacher’s outputs. These outputs often contain richer information than hard labels. For example, if an image is labelled “cat,” the teacher may still assign some probability to “tiger” or “fox,” and this probability distribution teaches the student about similarity between classes.
In language models, distillation can help a smaller model imitate the style, reasoning patterns, or answer quality of a larger model. The student model may not become equal to the teacher, but it can become much more efficient while retaining useful behaviour.
Distillation is powerful because it creates a genuinely smaller model, not just a compressed representation of the same model. This can make deployment easier, especially when inference speed and low latency are important. However, distillation requires training data, a teacher model, and a proper training process. It is more involved than simple post-training quantization, but it can produce excellent results when done carefully.
Distillation is widely used in practical AI systems because it helps balance performance and efficiency. Many production models are not the largest possible models, but distilled models that are fast enough and accurate enough for the use case.
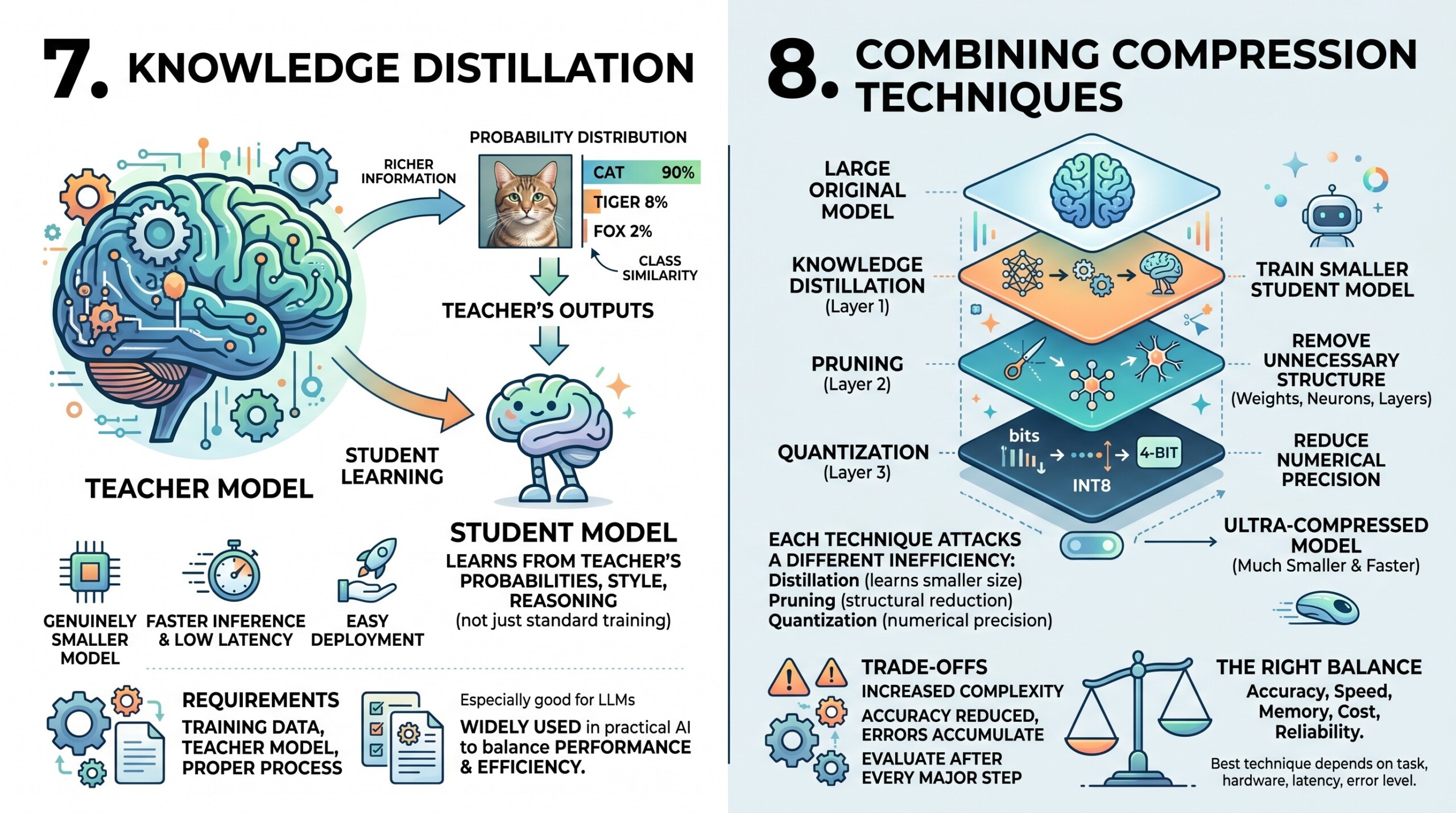
8. Combining compression techniques
In real-world deployment, compression techniques are often combined. A model may be distilled first, then pruned, and finally quantized. This layered approach can produce a model that is much smaller and faster than the original.
For example, a large teacher model may be used to train a smaller student model. The student may then be pruned to remove unnecessary components. After that, INT8 or 4-bit quantization may be applied to reduce memory even further.
This combination is useful because each technique attacks a different source of inefficiency. Distillation reduces model size through learning. Pruning removes unnecessary structure. Quantization reduces numerical precision. However, combining techniques also increases complexity. Each compression step can reduce accuracy, and the errors can accumulate. Therefore, engineers must evaluate the compressed model after every major step.
Good compression is not just about making the model smaller. It is about maintaining the right balance between accuracy, speed, memory, cost, and reliability. The best technique depends on the task, hardware, latency requirement, and acceptable error level. Subscribe to our free AI newsletter now.
9. Benefits and risks of model compression
Model compression offers major benefits. It makes AI more affordable, faster, and easier to deploy. It allows AI to run on mobile phones, edge devices, smaller servers, and private local systems.
Compression also helps organisations reduce infrastructure costs. A smaller model can serve more users with the same hardware, which is important for chatbots, recommendation engines, search systems, and enterprise AI tools.
It also supports privacy and offline use. If a compressed model can run locally, user data may not need to be sent to a central cloud server. This is valuable in healthcare, education, defence, and personal productivity applications. But compression also has risks. A compressed model may lose accuracy, become less stable, or perform worse on rare cases. It may also behave differently for different user groups if not tested carefully.
A major concern is that benchmark performance may look acceptable, while real-world performance may degrade in subtle ways. For example, a compressed language model may answer common questions well but fail more often on complex reasoning or domain-specific tasks.
This is why compressed models need proper evaluation. They should be tested on accuracy, latency, memory use, robustness, fairness, and safety before deployment.
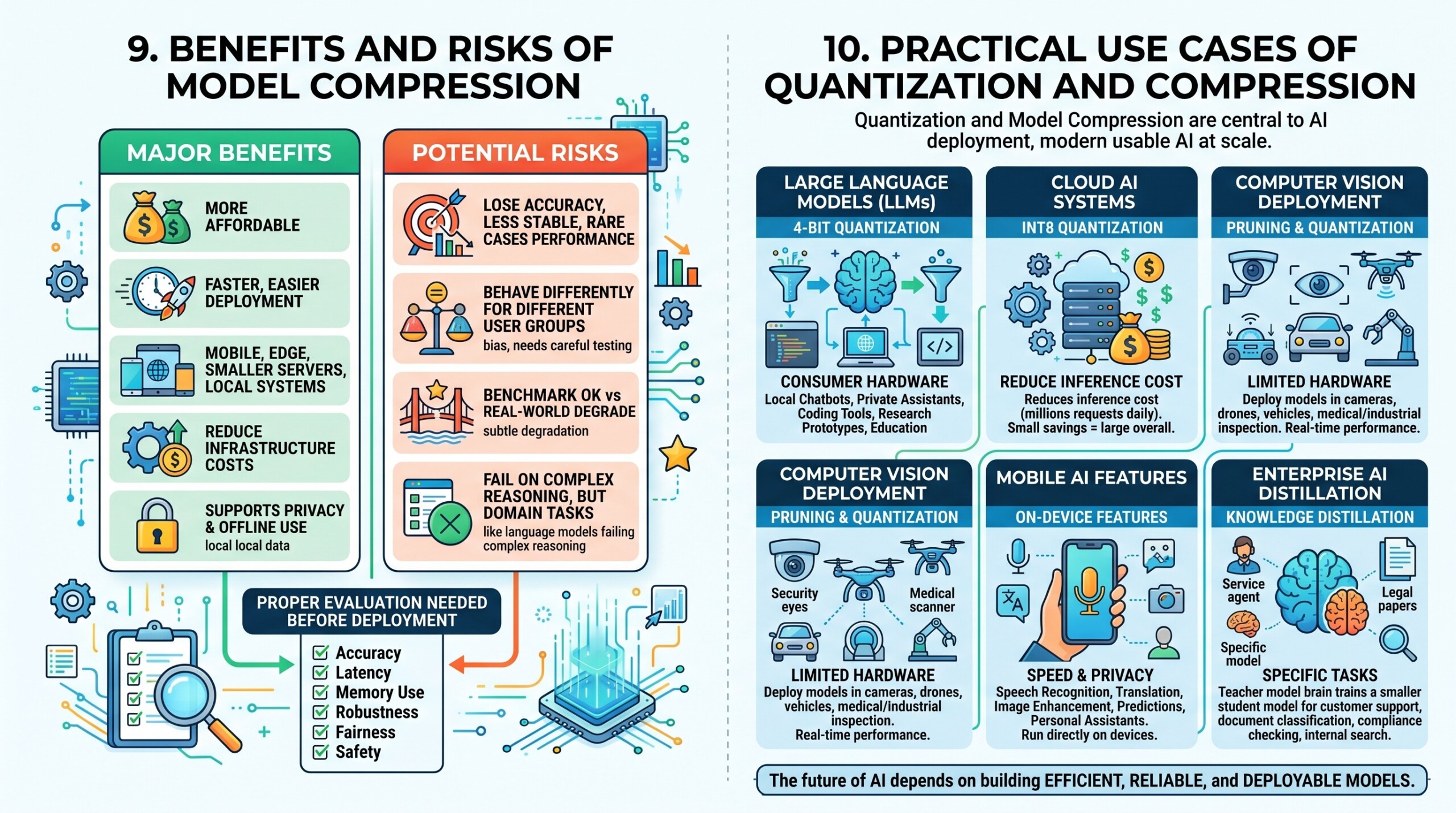
10. Practical use cases of quantization and compression
Quantization and model compression are now central to AI deployment. They are not minor engineering tricks, but core techniques that make modern AI usable at scale.
- In large language models, 4-bit quantization allows models to run on consumer hardware. This is useful for local chatbots, private assistants, coding tools, research prototypes, and educational use.
- In cloud AI systems, INT8 quantization helps reduce inference cost. When millions of requests are served daily, even a small reduction in computation per request can create large savings.
- In computer vision, pruning and quantization help deploy models in cameras, drones, vehicles, medical devices, and industrial inspection systems. These systems often need real-time performance with limited hardware.
- In mobile AI, compression allows features such as speech recognition, translation, image enhancement, keyboard prediction, and personal assistants to run directly on devices. This improves speed and can protect privacy.
- In enterprise AI, distillation helps create smaller models for specific tasks. A large general model can act as a teacher, while a smaller student model is trained for customer support, document classification, compliance checking, or internal search.
The future of AI will not only depend on who builds the biggest model. It will also depend on who can build the most efficient, reliable, and deployable model. Upgrade your AI-readiness with our masterclass.
Conclusion
Quantization and model compression techniques are essential for turning powerful AI models into practical AI systems. Large models may achieve impressive accuracy, but they are often expensive, slow, and difficult to deploy. Compression makes them smaller, faster, cheaper, and more accessible.
INT8 quantization provides a strong balance between accuracy and efficiency. 4-bit quantization gives more aggressive memory reduction and is especially useful for large language models. Pruning removes less useful parts of a model, while distillation transfers knowledge from a large teacher model to a smaller student model.
These techniques are not only technical optimisations. They are central to the future of AI adoption. Without compression, advanced AI would remain limited to large companies with expensive infrastructure. With compression, AI can move to mobile phones, edge devices, small businesses, classrooms, hospitals, and local systems.
The main lesson is simple: the best AI model is not always the largest model. In real-world deployment, the best model is the one that gives the right level of performance with the lowest practical cost, memory, latency, and energy use. Quantization, pruning, and distillation are the key tools that make this possible.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



