Planning and Reasoning in AI Agents

Planning and Reasoning in AI Agents
Chain-of-thought alternatives, tree search, task decomposition, self-correction, planning under uncertainty
Introduction
AI agents are becoming one of the most important directions in applied artificial intelligence. A normal chatbot answers a question. An AI agent tries to complete a goal. It may plan, search, use tools, inspect files, write code, call APIs, remember progress, ask for approval, and revise its approach when new information appears.
Planning and reasoning are therefore central to agent design. They decide how an agent breaks a large task into smaller steps, chooses between options, handles uncertainty, corrects mistakes, and acts safely in the real world. By June 2026, the field has moved beyond simple prompt engineering. Strong agents are built through a combination of reasoning models, task decomposition, tool use, memory, verification, orchestration, human oversight, and safety controls. The model is important, but the surrounding architecture is equally important.
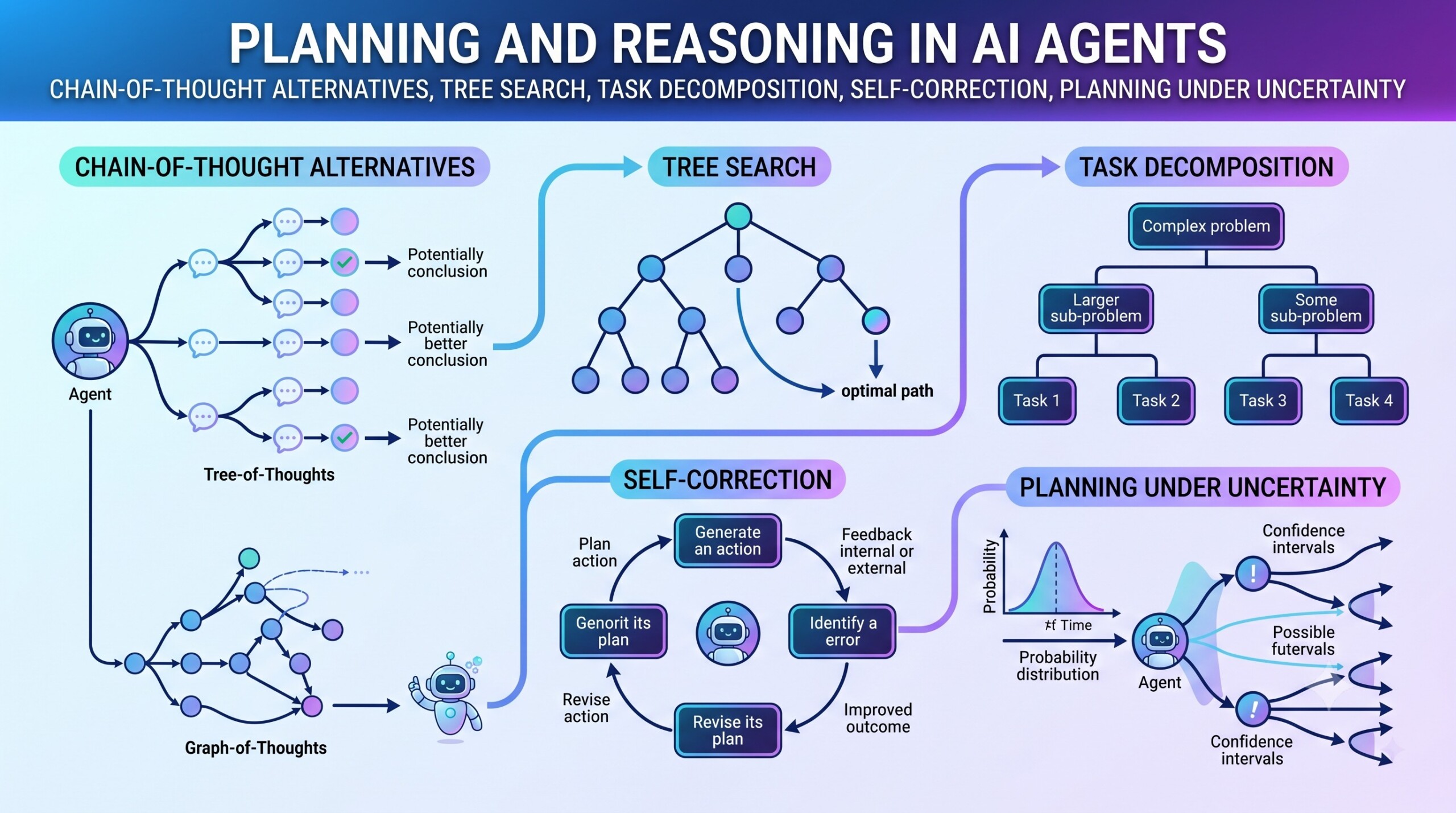
This lecture focuses on five major themes: chain-of-thought alternatives, tree search, task decomposition, self-correction, and planning under uncertainty.
Let’s dive deep into the topic now.
1. Chain-of-thought is useful, but raw chain-of-thought is not the best user interface
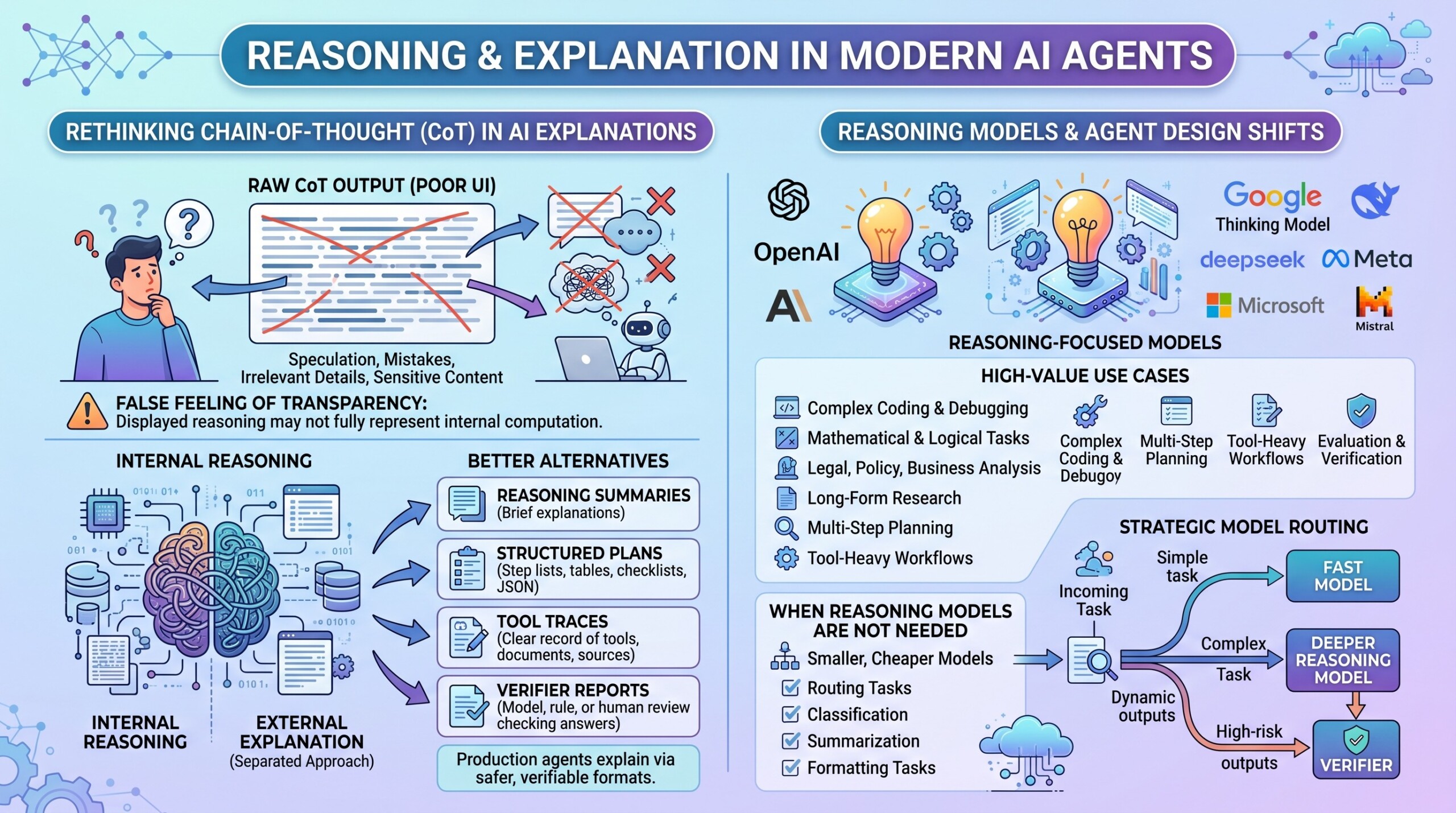
Chain-of-thought prompting became popular because it encouraged models to solve problems step by step. It helped with arithmetic, coding, logic, and multi-hop reasoning. However, production systems no longer treat visible raw chain-of-thought as the default way to explain AI decisions.
There are good reasons for this. Raw reasoning may include speculation, mistakes, hidden assumptions, irrelevant details, or sensitive intermediate content. It may also give users a false feeling that they are seeing exactly how the model made the decision. In reality, the displayed reasoning may not fully represent the model’s internal computation.
A better approach is to separate internal reasoning from external explanation. The agent may use internal reasoning, but the user should receive a clean answer, a short method summary, citations, tool traces, or a structured plan.
Better alternatives include:
- Reasoning summaries: Brief explanation of the approach without exposing every intermediate thought.
- Structured plans: Step lists, tables, checklists, decision trees, or JSON outputs.
- Tool traces: Clear record of tools used, documents checked, or sources consulted.
- Verifier reports: A second model, rule, test, or human reviewer checks the answer.
The practical lesson is clear: chain-of-thought can help internally, but production agents should explain themselves through safer and more verifiable formats.
2. Reasoning models have changed how agents are designed
Reasoning-focused models are now a major part of the agent ecosystem. OpenAI, Anthropic, Google, DeepSeek, Meta, Microsoft, Mistral, and others have all moved toward models that can spend more computation on difficult problems. Google has described Gemini 2.5 as a “thinking model,” and OpenAI’s agent documentation describes agents as applications that can plan, call tools, collaborate, and keep state.
Reasoning models are especially useful for:
- Complex coding and debugging
- Mathematical and logical tasks
- Legal, policy, and business analysis
- Long-form research
- Multi-step planning
- Tool-heavy workflows
- Evaluation and verification
But reasoning models are not always needed. A simple routing task, classification task, summarization task, or formatting task can often be handled by a smaller and cheaper model. This is why modern systems often use model routing. The agent may use a fast model for simple work, a deeper model for complex reasoning, and a verifier for high-risk outputs.
Good agent design is therefore not about always using the largest model. It is about using the right model for the right step. An excellent collection of learning videos awaits you on our Youtube channel.
3. Task decomposition is the backbone of agent planning
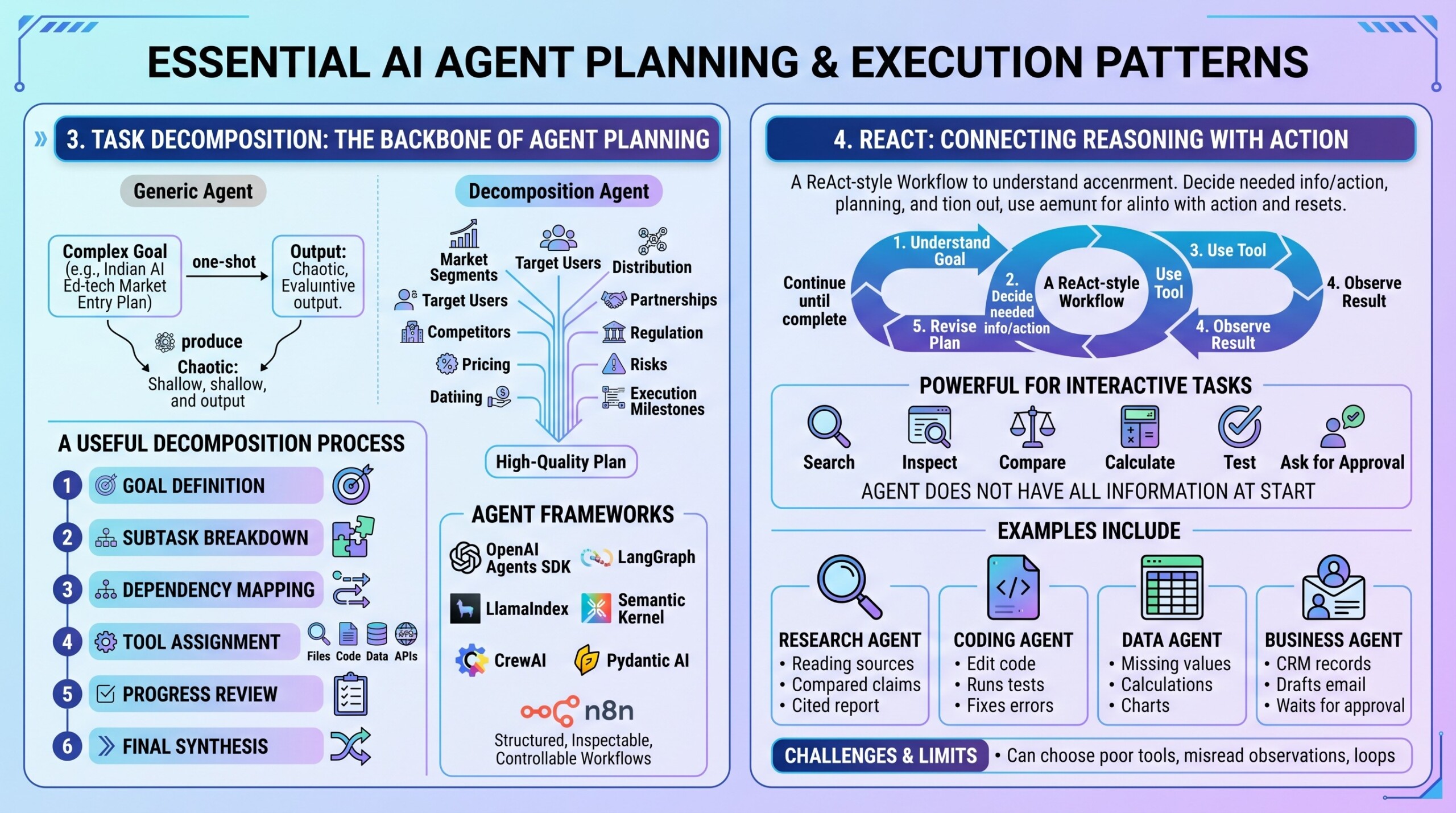
Task decomposition means breaking a large goal into smaller tasks. Without decomposition, an agent may try to solve everything in one response and produce shallow, generic, or incorrect output.
For example, if the user asks, “Prepare a market-entry plan for an AI education company in India,” a good agent should not immediately produce a final report. It should divide the work into market segments, target users, competitors, pricing, distribution, partnerships, regulation, risks, and execution milestones.
A useful decomposition process includes:
- Goal definition: What final output is needed?
- Subtask breakdown: What smaller jobs must be completed?
- Dependency mapping: Which steps must come first?
- Tool assignment: Which steps need search, files, code, data, or APIs?
- Progress review: Has each subtask produced usable evidence?
- Final synthesis: How should the pieces be combined?
Agent frameworks such as OpenAI Agents SDK, LangGraph, LlamaIndex, Microsoft Semantic Kernel, AutoGen-style systems, CrewAI, Pydantic AI, Vercel AI SDK, and n8n help developers design such workflows. They differ in philosophy, but the common goal is to make agent behavior more structured, inspectable, and controllable.
Task decomposition reduces confusion. It also makes it easier to debug the agent when something goes wrong.

4. ReAct connects reasoning with action
ReAct, short for reasoning and acting, is one of the most influential agent patterns. Instead of only generating a final answer, the agent alternates between deciding what to do, using a tool, observing the result, and updating its next step.
A ReAct-style workflow looks like this:
- Understand the goal.
- Decide what information or action is needed.
- Use a tool.
- Observe the result.
- Revise the plan.
- Continue until the task is complete.
This is powerful because real tasks are interactive. The agent often does not have all information at the start. It must search, inspect, compare, calculate, test, or ask for approval.
Examples include:
- A research agent that searches, reads sources, compares claims, and writes a cited report.
- A coding agent that opens files, edits code, runs tests, and fixes errors.
- A data agent that loads a spreadsheet, checks missing values, runs calculations, and creates charts.
- A business agent that checks CRM records, drafts emails, and waits for human approval before sending.
ReAct is not perfect. It can choose poor tools, misread observations, or enter loops. But it remains a core pattern because it links language reasoning with real-world action. A constantly updated Whatsapp channel awaits your participation.
5. Tree search helps agents compare alternatives
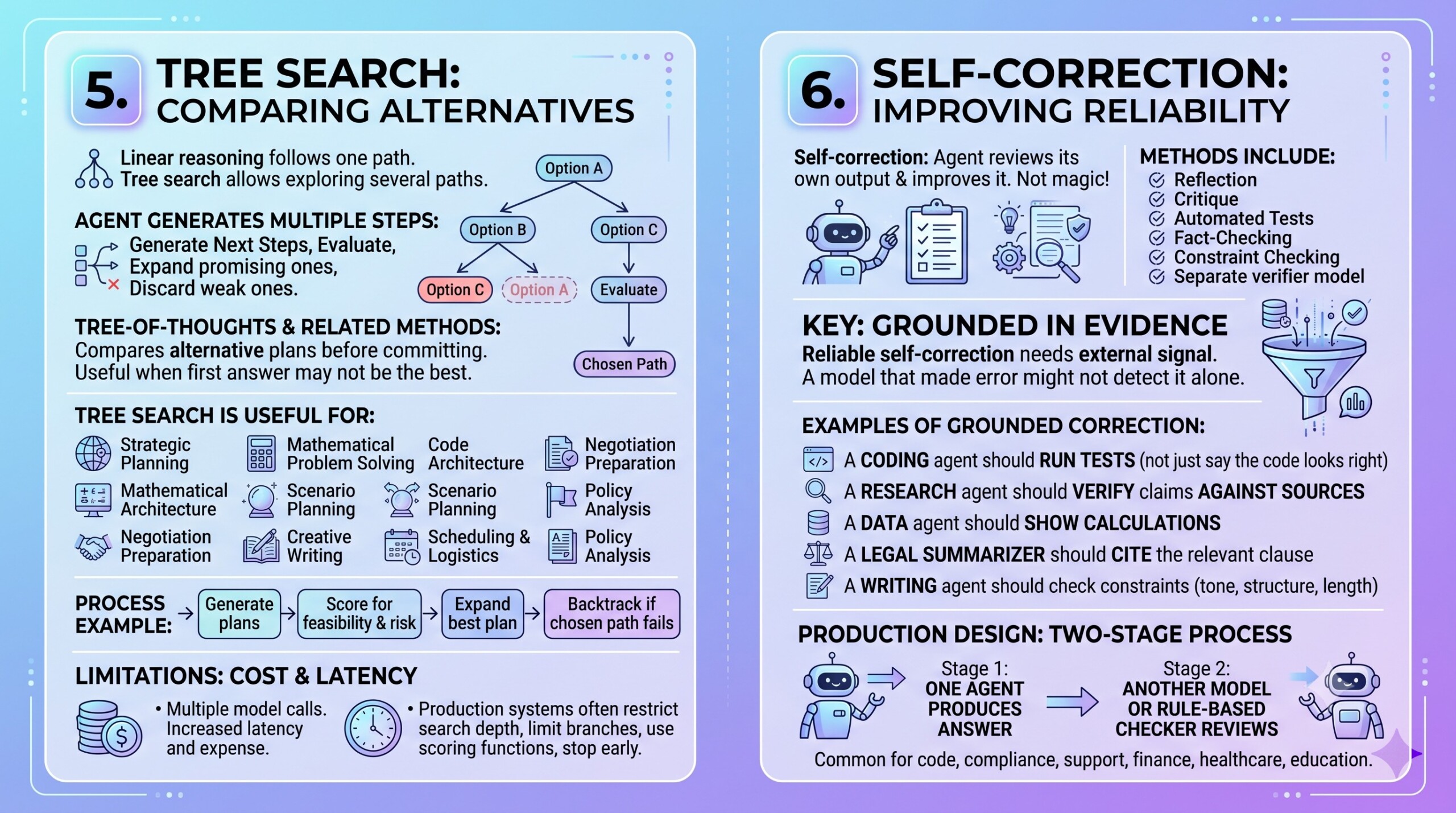
Linear reasoning follows one path. Many hard problems require exploring several paths. Tree search allows an agent to generate multiple possible next steps, evaluate them, expand the promising ones, and discard weak ones.
Tree-of-Thoughts and related methods are useful when the first answer may not be the best answer. The agent can compare alternative plans before committing.
Tree search is useful for:
- Strategic planning
- Mathematical problem-solving
- Code architecture
- Negotiation preparation
- Scenario planning
- Creative writing
- Scheduling and logistics
- Policy analysis
A simple tree-search process may generate three possible plans, score each plan for feasibility and risk, expand the best plan, then backtrack if the chosen path fails.
The limitation is cost. Tree search often requires multiple model calls. It can increase latency and expense. Therefore, production systems usually restrict the search depth, limit the number of candidate branches, use scoring functions, and stop early when confidence is high.
Tree search is best used for high-value tasks where better reasoning is worth the extra computation.
6. Self-correction improves reliability when it is grounded
Self-correction means the agent reviews its own output and improves it. This may happen through reflection, critique, automated tests, fact-checking, constraint checking, or a separate verifier model.
However, self-correction is not magic. A model that made an error may fail to detect it if it has no external signal. The most reliable self-correction is grounded in evidence.
Examples:
- A coding agent should run tests, not merely say the code looks right.
- A research agent should verify claims against sources.
- A data agent should show calculations.
- A legal summarizer should cite the relevant clause.
- A writing agent should check whether tone, structure, and length constraints were followed.
Self-correction works best when the system has a concrete standard to check against. That standard may be a unit test, source document, database value, policy rule, rubric, calculation, or human instruction.
In production, many teams use a two-stage design: one agent produces the answer, and another model or rule-based checker reviews it. This is especially useful for code, compliance, customer support, finance, healthcare, and education. Excellent individualised mentoring programmes available.
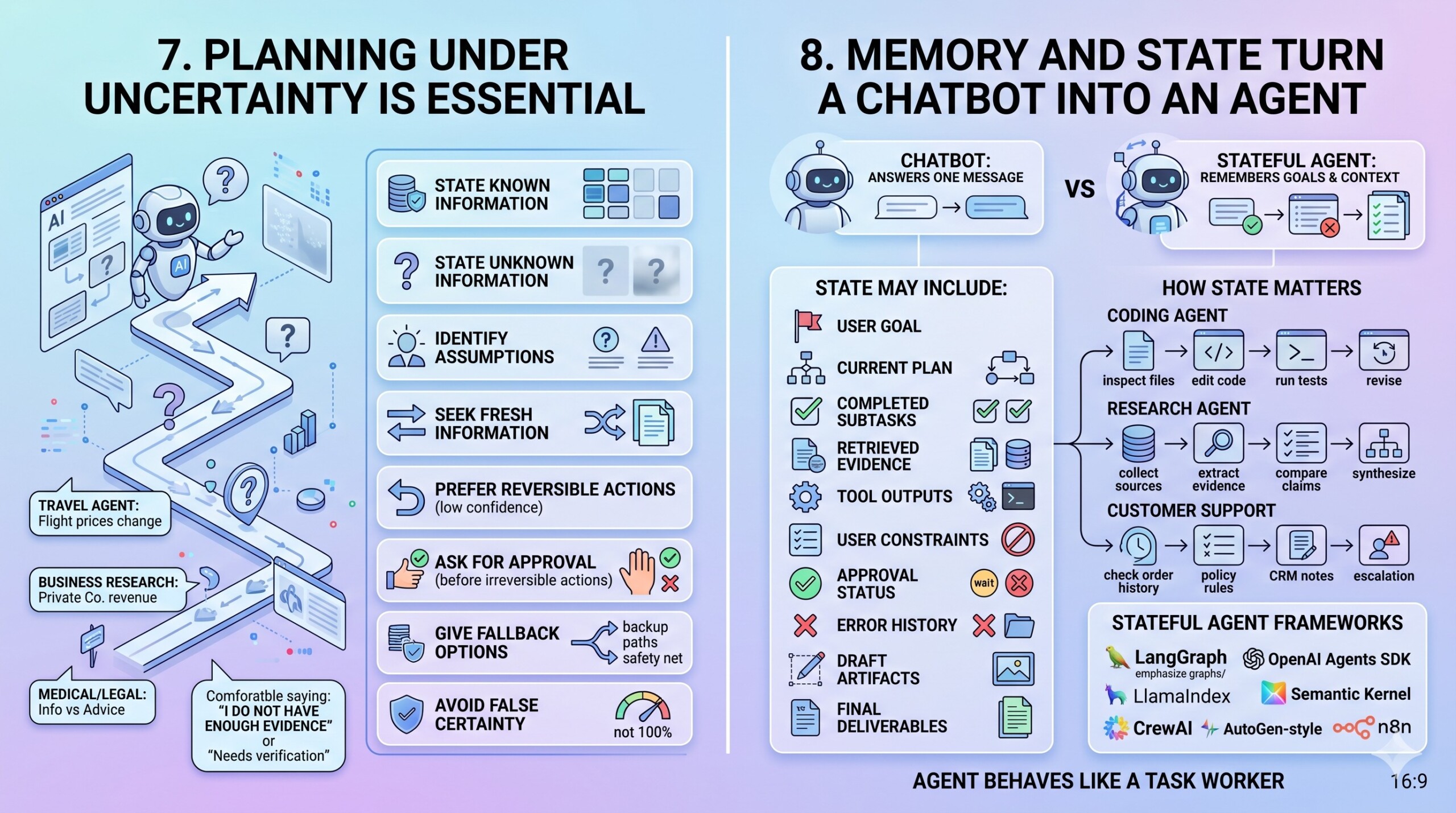
7. Planning under uncertainty is essential
Real-world agents rarely have perfect information. Prices change, laws change, websites differ, data may be incomplete, and user instructions may be ambiguous. A useful agent must know how to act under uncertainty.
An uncertainty-aware agent should:
- State what is known.
- State what is unknown.
- Identify assumptions.
- Seek fresh information when needed.
- Prefer reversible actions when confidence is low.
- Ask for approval before irreversible actions.
- Give fallback options.
- Avoid pretending certainty where none exists.
For example, a travel agent should not assume flight prices are stable. A business research agent should not claim exact revenue for a private company without a reliable source. A medical or legal assistant should distinguish general information from professional advice.
Planning under uncertainty is not just about accuracy. It is also about responsibility. Good agents should be comfortable saying, “I do not have enough evidence,” or “This needs verification before action.”
8. Memory and state turn a chatbot into an agent
A chatbot can answer one message. An agent needs state. State means the system remembers the goal, plan, completed steps, tool outputs, user preferences, approvals, errors, and pending actions.
State may include:
- User goal
- Current plan
- Completed subtasks
- Retrieved evidence
- Tool outputs
- User constraints
- Approval status
- Error history
- Draft artifacts
- Final deliverables
Frameworks such as LangGraph emphasize stateful workflows, persistence, human-in-the-loop control, streaming, debugging, and graph-based execution. OpenAI’s Agents SDK, LlamaIndex, Semantic Kernel, CrewAI, AutoGen-style systems, and n8n also support different approaches to state and orchestration.
State matters because many tasks cannot be completed in a single model call. A coding agent must inspect files, edit code, run tests, and revise. A research agent must collect sources, extract evidence, compare claims, and synthesize. A customer-support agent must check order history, policy rules, CRM notes, and escalation criteria.
Without state, an agent forgets where it is. With state, it can behave more like a task worker. Subscribe to our free AI newsletter now.
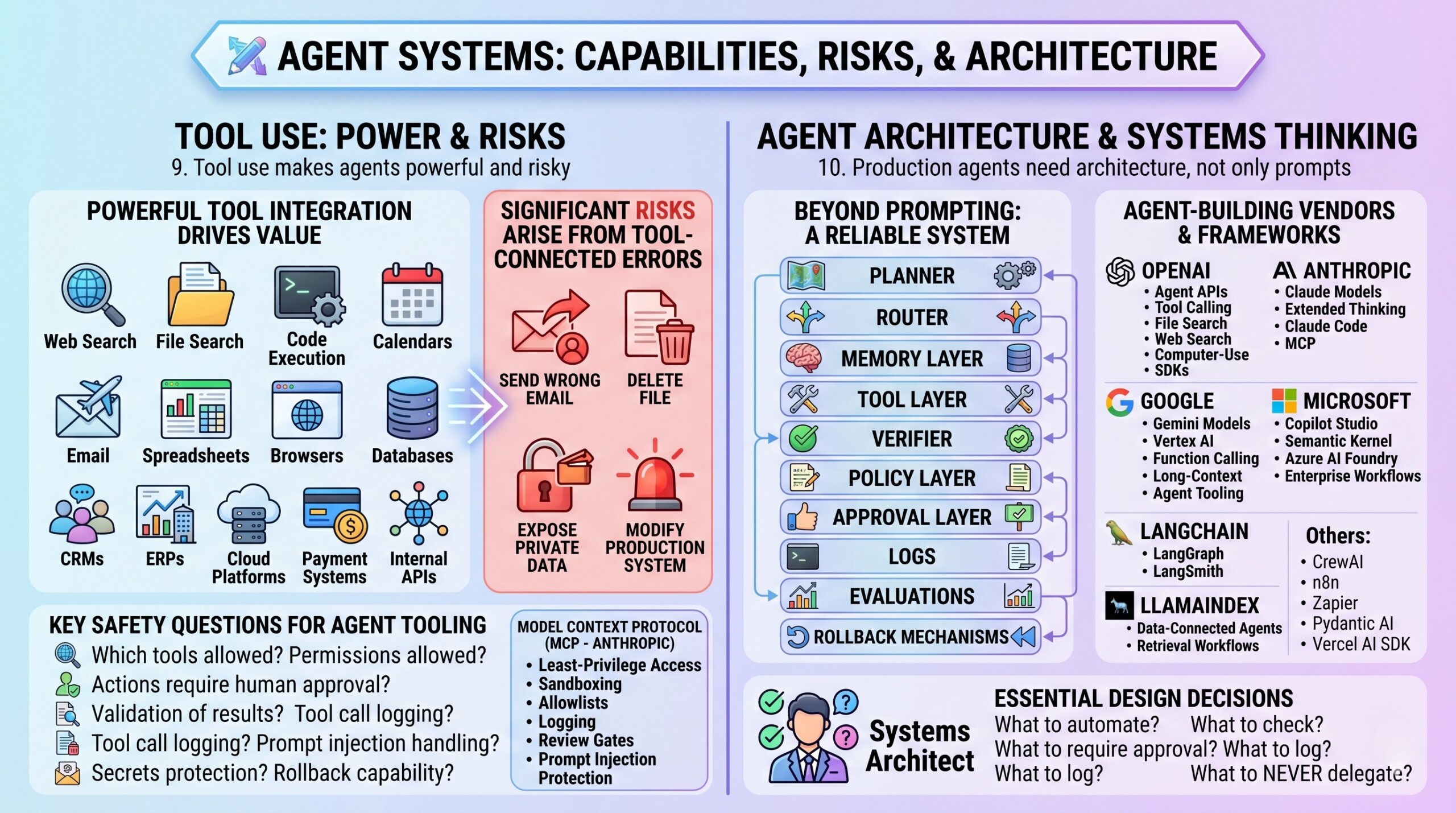
9. Tool use makes agents powerful and risky
Tool use is where reasoning meets the real world. Tools may include web search, file search, code execution, calendars, email, spreadsheets, browsers, databases, CRMs, ERPs, cloud platforms, payment systems, and internal APIs.
This creates enormous value. It also creates risk. A text error is one thing. A tool-connected error can send the wrong email, delete a file, expose private data, or modify a production system.
The main safety questions are:
- Which tools should the agent have?
- What permissions should each tool allow?
- Which actions require human approval?
- How are tool results validated?
- How are tool calls logged?
- How are secrets protected?
- How is prompt injection handled?
- Can the action be rolled back?
The Model Context Protocol, introduced by Anthropic, has become important because it standardizes connections between AI systems, tools, and data sources. However, standardization does not remove security concerns. Tool-connected agents still need least-privilege access, sandboxing, allowlists, logging, review gates, and protection against malicious tool descriptions or prompt injection.
10. Production agents need architecture, not only prompts
Prompting is useful, but production agents require architecture. A reliable system usually includes a planner, router, memory layer, tool layer, verifier, policy layer, approval layer, logs, evaluations, and rollback mechanisms.
Vendors and frameworks now reflect this shift. OpenAI provides agent-oriented APIs, tool calling, file search, web search, computer-use capabilities, tracing, and SDKs. Anthropic provides Claude models, extended thinking modes, Claude Code, and MCP. Google provides Gemini models, Vertex AI, function calling, long-context features, and agent tooling. Microsoft supports Copilot Studio, Semantic Kernel, Azure AI Foundry, and enterprise agent workflows. LangChain provides LangGraph and LangSmith. LlamaIndex focuses on data-connected agents and retrieval workflows. CrewAI, n8n, Zapier, Pydantic AI, and Vercel AI SDK support different parts of the agent-building stack.
The best builders now think like systems architects. They ask what should be automated, what should be checked, what should require approval, what should be logged, and what should never be delegated to an AI system. Upgrade your AI-readiness with our masterclass.
Conclusion
Planning and reasoning are the difference between a simple AI assistant and a useful AI agent. A simple assistant responds. An agent plans, acts, observes, revises, and completes work.
By June 2026, the mature view is that agentic AI needs much more than visible chain-of-thought. It needs structured planning, task decomposition, tree search when useful, grounded self-correction, uncertainty handling, tool use, memory, and human oversight.
The future of AI agents will not be decided only by larger models. It will be decided by better architectures. The most useful systems will combine strong reasoning models with secure tools, reliable verification, stateful workflows, clear approval gates, and accountability.
For educators, this means teaching agents as engineered systems, not magical machines. For business leaders, it means beginning with bounded workflows and measurable outcomes. For policymakers, it means focusing on auditability, privacy, liability, tool permissions, and human control.
Planning and reasoning in AI agents is therefore both a technical subject and a governance subject. It is the foundation for building AI systems that are capable, safe, useful, and aligned with human goals.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



