RAG beyond basics – Graph RAG, Hybrid Search, and Enterprise Knowledge Systems

RAG beyond basics – Graph RAG, Hybrid Search, and Enterprise Knowledge Systems
Combining vector search, keyword search, knowledge graphs, metadata, permissions, and citations
Introduction
Retrieval-Augmented Generation, or RAG, began as a simple idea: instead of asking a language model to answer only from its training data, retrieve relevant information from an external knowledge base and place that information into the model’s context. This made AI systems more useful for enterprise work because they could answer from company documents, policies, manuals, tickets, product specifications, contracts, research reports, and internal knowledge repositories.
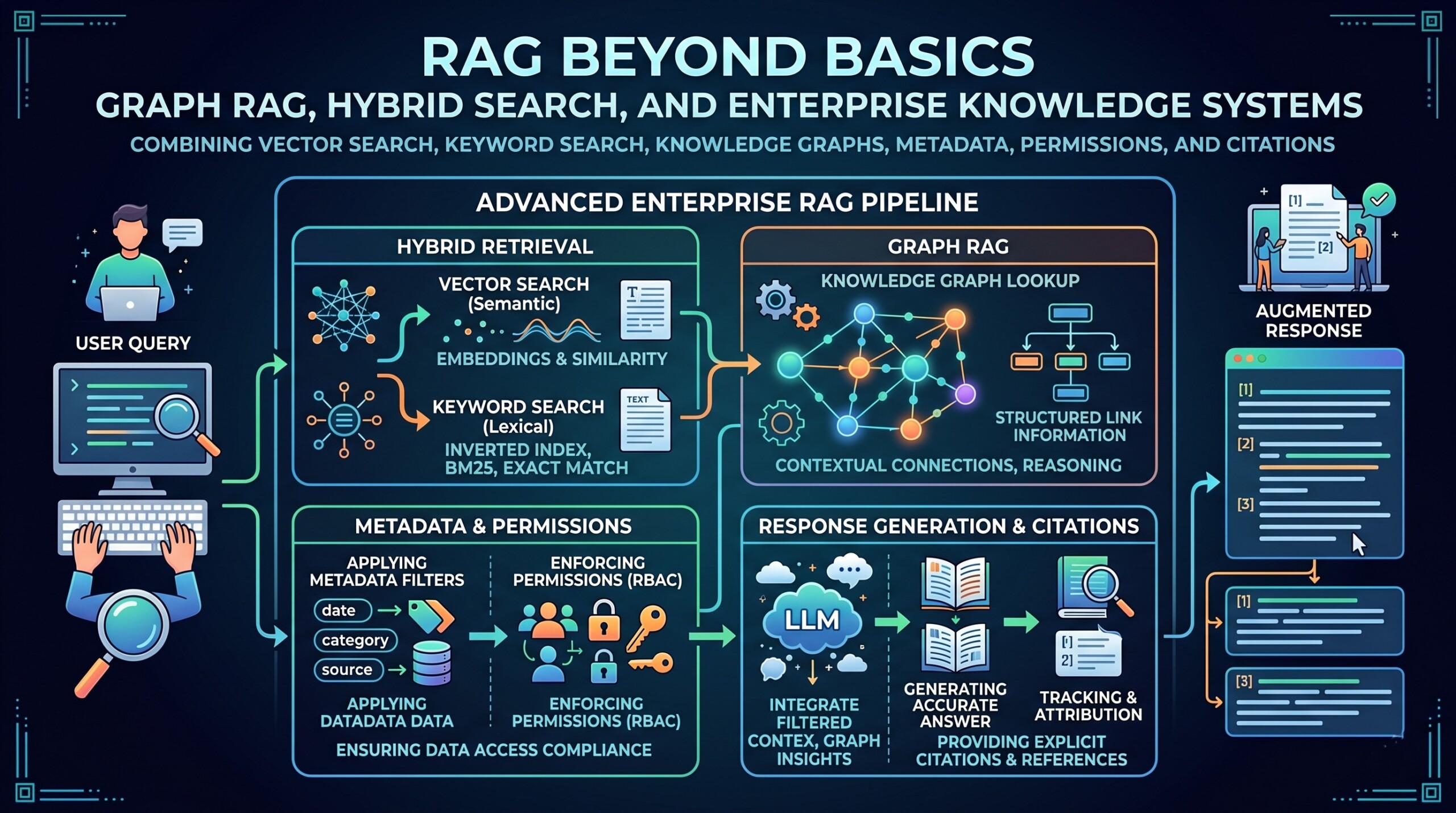
But now, serious enterprise RAG has moved far beyond “chunk documents, create embeddings, search vectors, and generate an answer.” That basic pipeline is useful for demos, but it is not enough for real organizations. Enterprises need answers that are accurate, current, permission-aware, explainable, auditable, and traceable to sources. They also need retrieval systems that work across messy data: PDFs, spreadsheets, emails, CRM notes, code repositories, regulations, tables, wikis, support tickets, and scanned documents.
This is where advanced RAG becomes an enterprise knowledge system. It combines vector search for semantic meaning, keyword search for exact matches, knowledge graphs for relationships, metadata for filtering, permissions for security, reranking for relevance, and citations for trust. The goal is not merely to “chat with documents.” The goal is to build a reliable knowledge layer that helps people find, reason over, and verify organizational knowledge.
Let’s dive deep into the topic now.
1. Basic RAG is useful, but it is not enterprise-grade by itself
The basic RAG pipeline usually has four stages: ingest documents, split them into chunks, create embeddings, and retrieve similar chunks when a user asks a question. This works well when the question is simple and the answer is located in one or two clearly written passages.
However, enterprise questions are often more complex. A user may ask: “Which customers are affected by the new compliance rule?”, “What changed between the 2024 and 2026 versions of this policy?”, or “Which product incidents are linked to the same root cause?” These questions require more than semantic similarity. They require filtering, comparison, reasoning, relationship traversal, date awareness, access control, and source verification.
The weakness of basic RAG is that it often treats knowledge as isolated text chunks. But enterprise knowledge is rarely isolated. It is connected across people, products, projects, customers, policies, systems, and time. A strong enterprise RAG system must preserve these connections instead of flattening everything into anonymous text fragments.
2. Hybrid search is now the practical default for serious RAG
Vector search is powerful because it understands meaning. A user can ask “How do we handle employee exits?” and the system may retrieve documents titled “Offboarding Procedure” even if the exact words do not match. But vector search alone can miss exact terms, IDs, dates, acronyms, legal phrases, error codes, product names, part numbers, and numerical references.
Keyword search, especially BM25-style lexical search, remains valuable because it is precise. It finds exact words, phrases, codes, and structured terms. In many enterprise settings, exactness matters as much as semantic understanding.
A hybrid search system combines both.
- Vector search retrieves conceptually similar content even when the wording differs.
- Keyword search retrieves exact matches, named entities, codes, numbers, and domain-specific terminology.
- Sparse retrieval models can bridge the gap between keyword and semantic retrieval.
- Rank fusion, such as Reciprocal Rank Fusion, combines multiple ranked lists into one result set.
- Reranking models then reorder the top candidates based on deeper relevance.
This is important because no single retrieval method wins everywhere. For broad conceptual questions, vector search may perform well. For precise financial, legal, technical, or tabular questions, lexical retrieval may be stronger. Hybrid search reduces dependence on one retrieval method and gives the system a better chance of finding the right evidence. An excellent collection of learning videos awaits you on our Youtube channel.

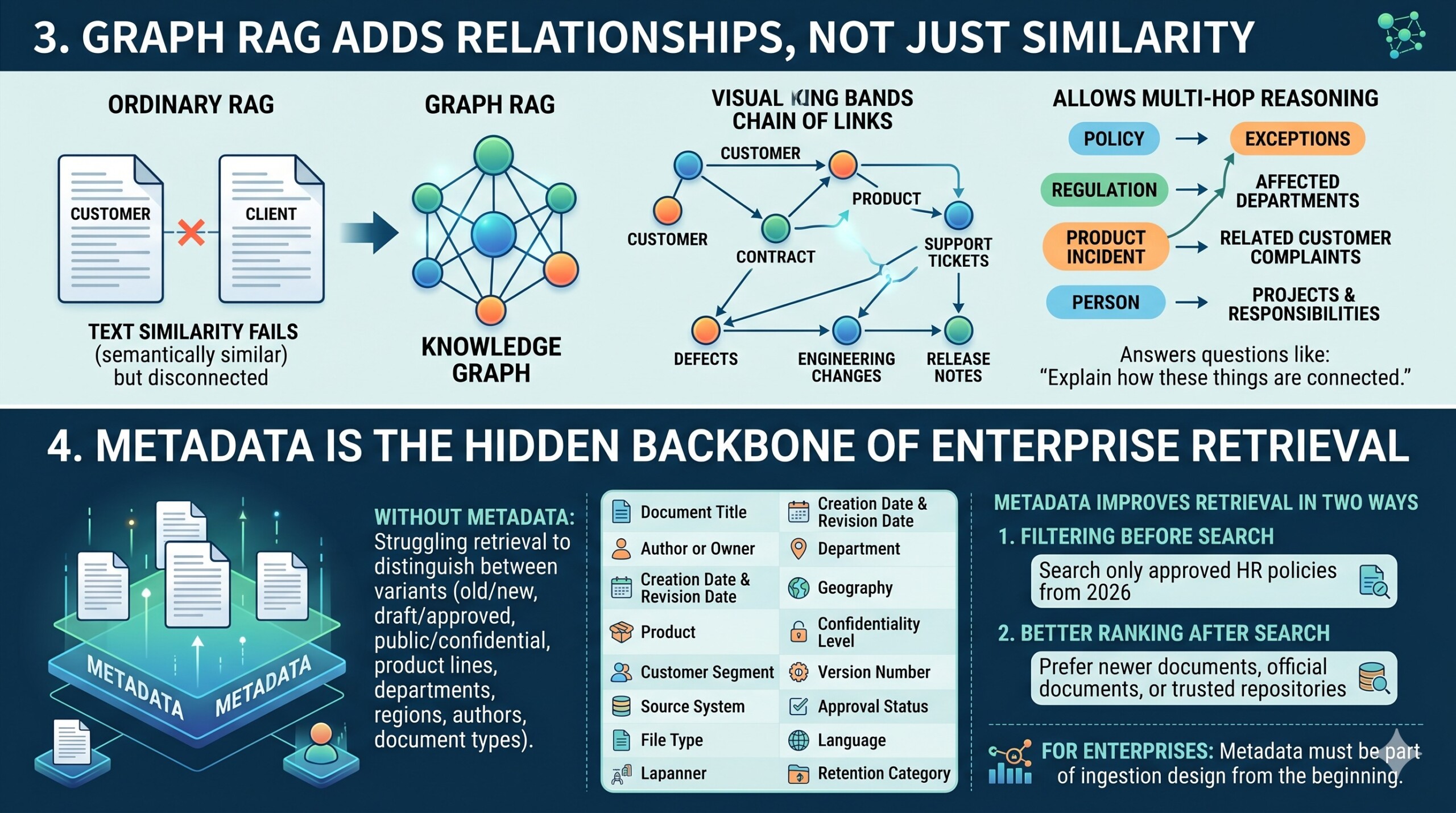
3. Graph RAG adds relationships, not just similarity
Graph RAG, or Graph-based Retrieval-Augmented Generation, addresses a major limitation of ordinary RAG: text similarity does not necessarily capture relationships. Two documents may never use similar wording, but they may still be connected through the same customer, regulation, project, product defect, supplier, employee role, or business process.
A knowledge graph represents information as entities and relationships. For example:
- A customer is linked to a contract.
- A contract is linked to a product.
- A product is linked to support tickets.
- Support tickets are linked to defects.
- Defects are linked to engineering changes.
- Engineering changes are linked to release notes.
This structure allows the system to answer questions that require multi-hop reasoning. Instead of retrieving only the most semantically similar chunks, Graph RAG can follow relationships: from a policy to its exceptions, from a regulation to affected departments, from a product incident to related customer complaints, or from a person to projects and responsibilities.
Graph RAG is especially useful when the user’s question is not simply “find me a paragraph,” but “explain how these things are connected.”

4. Metadata is the hidden backbone of enterprise retrieval
Metadata is often less glamorous than embeddings, but it is one of the most important parts of enterprise RAG. Without metadata, retrieval systems struggle to distinguish between old and new documents, drafts and approved versions, public and confidential files, product lines, departments, regions, authors, and document types.
Metadata can include:
- Document title
- Author or owner
- Creation date and revision date
- Department
- Geography
- Product
- Customer segment
- Confidentiality level
- Version number
- Source system
- File type
- Approval status
- Language
- Retention category
Metadata improves retrieval in two ways. First, it allows filtering before search: for example, search only approved HR policies from 2026. Second, it allows better ranking after search: for example, prefer newer documents, official documents, or documents from a trusted repository.
For enterprises, metadata should not be an afterthought added after the RAG system fails. It should be part of the ingestion design from the beginning. A constantly updated Whatsapp channel awaits your participation.
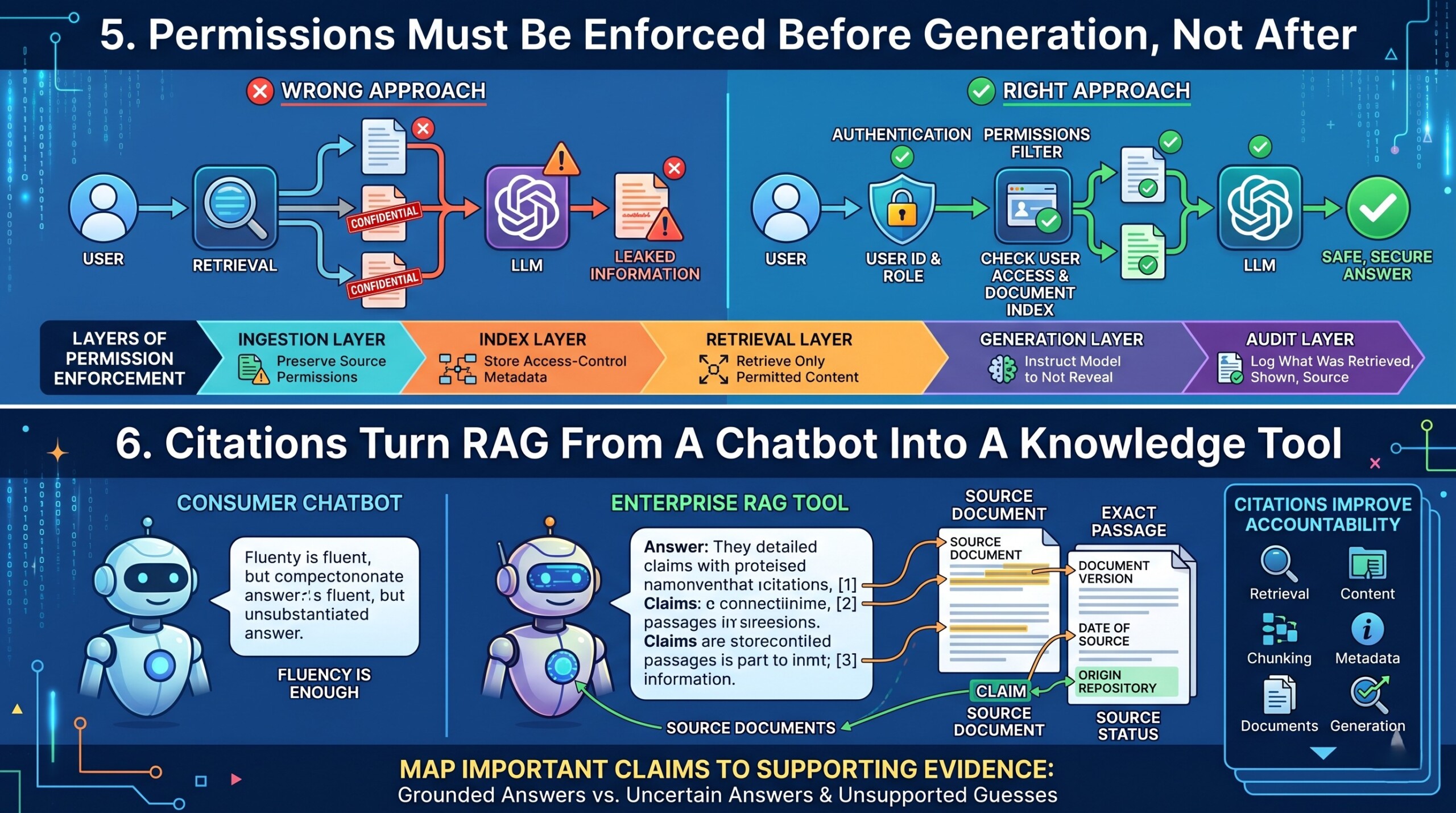
5. Permissions must be enforced before generation, not after
One of the biggest enterprise mistakes is treating RAG as only a relevance problem. It is also a security problem.
A retrieval system may find a document because it is relevant, but that does not mean the user is authorized to see it. If permissions are not enforced at retrieval time, the system may place confidential content into the model context. Once that happens, the model may summarize or reveal information the user should never have accessed.
Enterprise RAG must therefore support permission-aware retrieval. This means the system should filter candidate documents based on the user’s identity, role, group membership, department, geography, project access, customer account access, and document-level permissions before the final context is passed to the model.
Good practice is to enforce permissions at several layers:
- Ingestion layer: preserve source permissions from SharePoint, Google Drive, Confluence, Jira, Salesforce, Git repositories, databases, or file systems.
- Index layer: store access-control metadata with each chunk or document.
- Retrieval layer: retrieve only from content the user is allowed to access.
- Generation layer: instruct the model not to reveal unsupported or unauthorized information.
- Audit layer: log what was retrieved, what was shown, and what source was used.
Permissions are not a cosmetic feature. They are a core requirement for enterprise trust.
6. Citations turn RAG from a chatbot into a knowledge tool
In consumer chat, a fluent answer may be enough. In enterprise work, fluency is not enough. Users need to know where the answer came from. A manager, lawyer, engineer, doctor, analyst, or policymaker cannot act on an answer unless it can be verified.
Citations make RAG more useful because they connect generated claims to source documents. A good citation system should show:
- The source document
- The exact passage or page
- The document version
- The date of the source
- The repository or system of origin
- Whether the source is official, draft, archived, or user-generated
Citations also improve accountability. If the answer is wrong, the organization can inspect whether the problem came from retrieval, outdated content, poor chunking, bad metadata, missing documents, or model generation.
The best enterprise systems do not merely append random links at the end. They map important claims to supporting evidence. This helps users distinguish between grounded answers, uncertain answers, and unsupported model guesses. Excellent individualised mentoring programmes available.
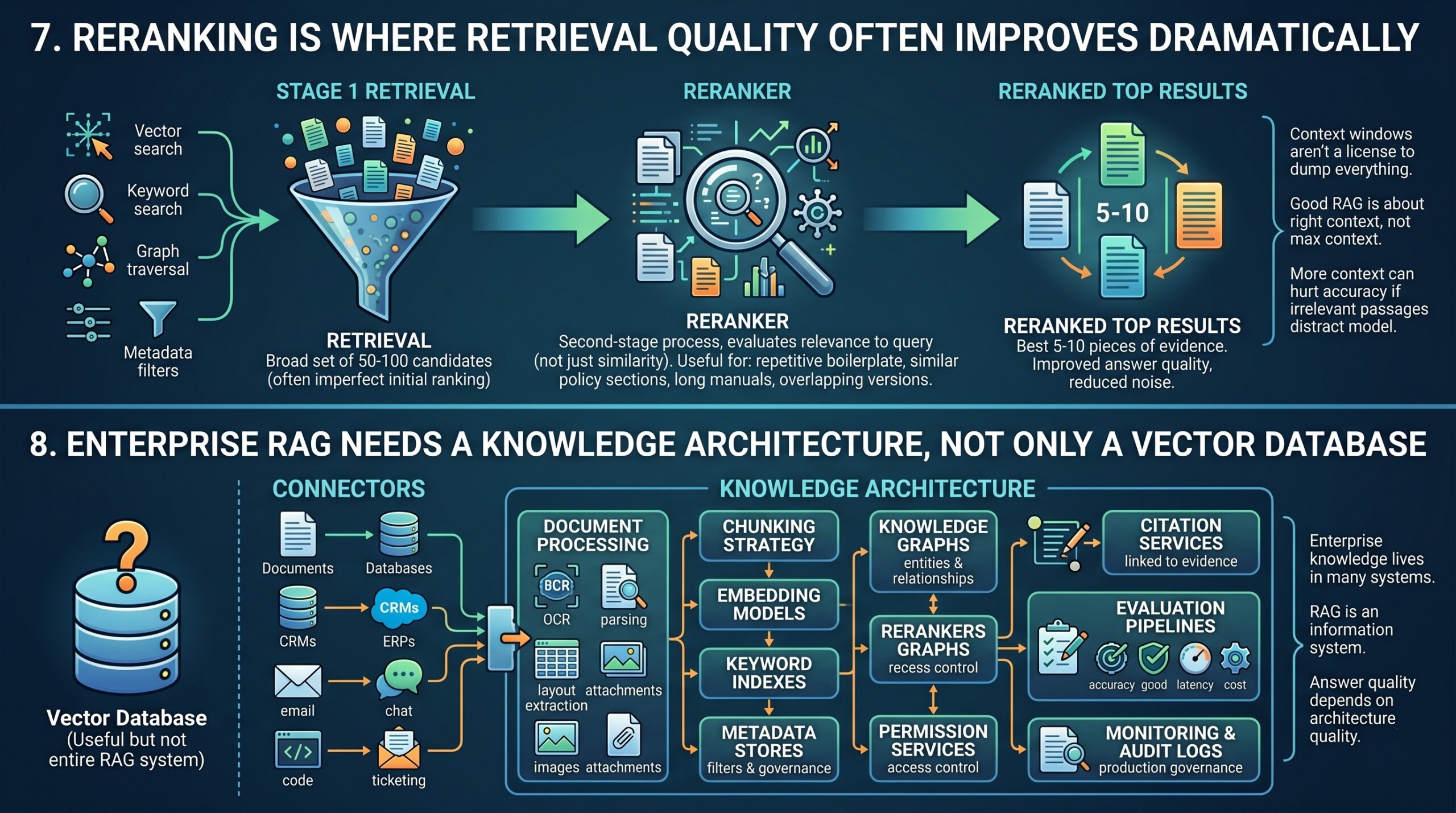
7. Reranking is where retrieval quality often improves dramatically
The first retrieval stage usually brings back a broad set of candidate chunks. These candidates may come from vector search, keyword search, graph traversal, metadata filters, or multiple indexes. But the initial ranking is often imperfect.
Reranking is a second-stage process that looks more carefully at the user query and the retrieved candidates. A reranker can evaluate whether a passage actually answers the question, not just whether it is similar. This is especially useful when documents contain repeated boilerplate, similar policy sections, long manuals, or many overlapping versions.
In a mature RAG pipeline, the system may retrieve 50 or 100 candidates, then rerank them down to the best 5 to 10 pieces of evidence. This improves answer quality and reduces noise in the model context.
Reranking is also important because context windows, although larger than before, are still not a license to dump everything into the prompt. More context can sometimes hurt accuracy if irrelevant passages distract the model. Good RAG is not about maximum context. It is about the right context.
8. Enterprise RAG needs a knowledge architecture, not only a vector database
A vector database is useful, but it is not the entire RAG system. Enterprise knowledge usually lives in many systems: document repositories, databases, CRMs, ERPs, email, chat, code repositories, ticketing systems, data warehouses, BI tools, and external regulatory sources.
A serious enterprise RAG architecture typically includes:
- Connectors to ingest data from enterprise systems
- Document processing for OCR, parsing, layout extraction, tables, images, and attachments
- Chunking strategy tuned for document type and task
- Embedding models for semantic representation
- Keyword indexes for lexical search
- Metadata stores for filters and governance
- Knowledge graphs for entities and relationships
- Permission services for access control
- Rerankers for relevance improvement
- Citation services for evidence traceability
- Evaluation pipelines for accuracy, groundedness, latency, and cost
- Monitoring and audit logs for production governance
The point is simple: enterprise RAG is not a plug-in. It is an information system. The quality of the answers depends on the quality of the knowledge architecture behind them. Subscribe to our free AI newsletter now.
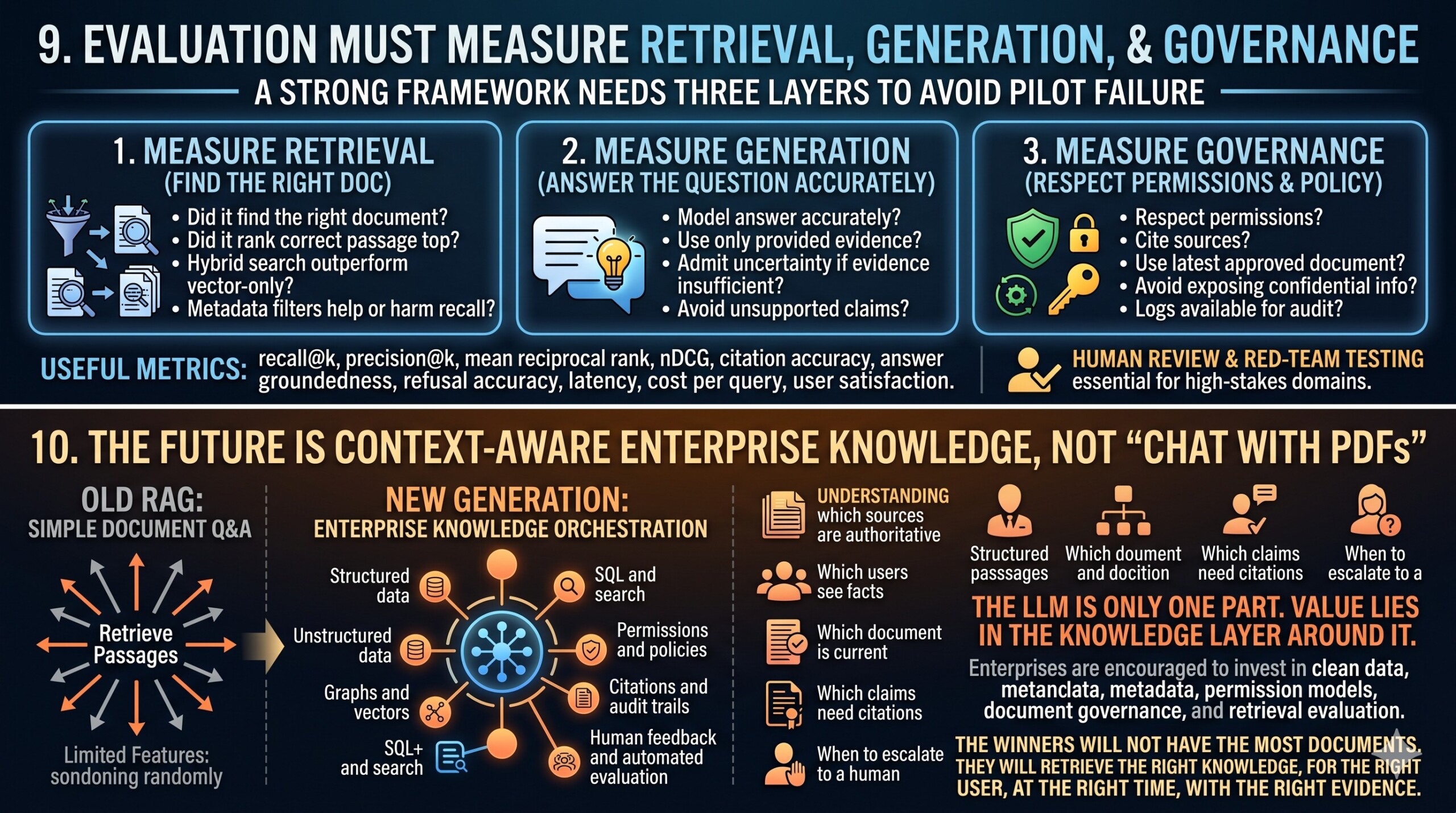
9. Evaluation must measure retrieval, generation, and governance
Many RAG pilots fail because teams evaluate only the final answer. That is not enough. A wrong answer may be caused by failed retrieval, poor ranking, missing documents, outdated sources, bad chunking, weak prompts, or hallucination during generation.
A strong evaluation framework should measure at least three layers.
First, measure retrieval. Did the system find the right document? Did it rank the correct passage near the top? Did hybrid search outperform vector-only search? Did metadata filters help or harm recall?
Second, measure generation. Did the model answer the question accurately? Did it use only the provided evidence? Did it admit uncertainty when evidence was insufficient? Did it avoid unsupported claims?
Third, measure governance. Did the system respect permissions? Did it cite sources? Did it use the latest approved document? Did it avoid exposing confidential information? Were logs available for audit?
Useful metrics include recall@k, precision@k, mean reciprocal rank, nDCG, citation accuracy, answer groundedness, refusal accuracy, latency, cost per query, and user satisfaction. For high-stakes domains, human review and red-team testing remain essential.
10. The future is context-aware enterprise knowledge, not “chat with PDFs”
By June 2026, the direction is clear. RAG is becoming less about simple document Q&A and more about enterprise knowledge orchestration.
The next generation of systems will combine structured and unstructured data, graphs and vectors, SQL and search, permissions and policies, citations and audit trails, human feedback and automated evaluation. They will not merely retrieve passages. They will understand which sources are authoritative, which users are allowed to see which facts, which document is current, which claims need citations, and which questions require escalation to a human.
In this world, the language model is only one part of the system. The larger value comes from the knowledge layer around it. Enterprises that invest in clean data, metadata, permission models, document governance, and retrieval evaluation will get far better results than those that only switch to a larger model.
The winners will not be the organizations with the most documents. They will be the organizations that can retrieve the right knowledge, for the right user, at the right time, with the right evidence. Upgrade your AI-readiness with our masterclass.
Conclusion
RAG beyond basics is not a single upgrade. It is a shift from simple semantic search to governed enterprise knowledge systems. Vector search remains important, but it must be combined with keyword search, graph relationships, metadata filters, reranking, permissions, citations, and evaluation.
Graph RAG helps systems understand relationships. Hybrid search improves retrieval across different query types. Metadata makes filtering and governance possible. Permissions protect confidential information. Citations make answers verifiable. Reranking improves evidence quality. Evaluation keeps the system honest.
The central lesson for June 2026 is this: enterprise RAG is not about making AI sound knowledgeable. It is about making AI reliably connected to organizational truth. A good system does not simply answer. It retrieves responsibly, reasons carefully, cites clearly, respects access rights, and shows users where its knowledge comes from.
Share this with the world
Related Articles



{kind=link}
{kind=link}
{kind=link}



